 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoCA: Incorporating Multi-stage Domain Pretraining and Cross-guided Multimodal Attention for Textbook Question Answering
Paper and Code
Dec 06, 2021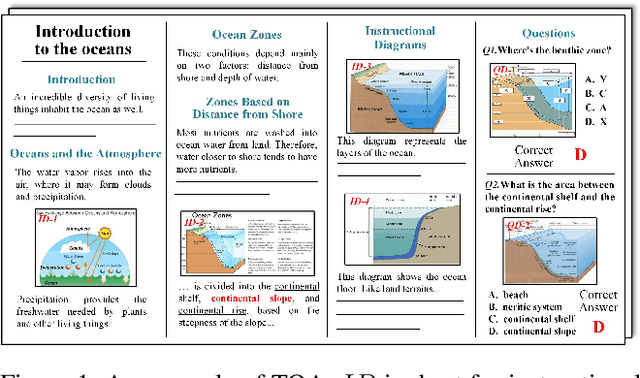

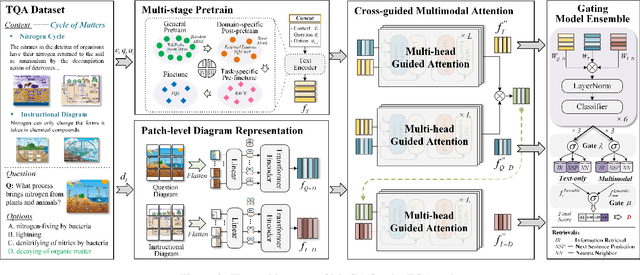
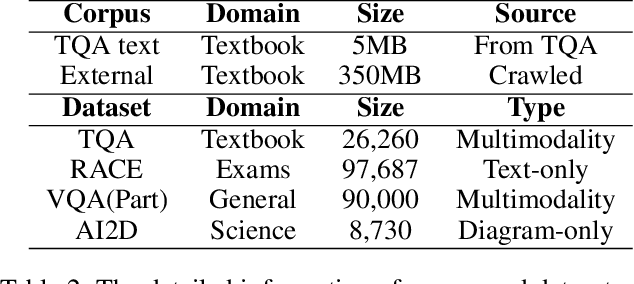
Textbook Question Answering (TQA) is a complex multimodal task to infer answers given large context descriptions and abundant diagrams. Compared with Visual Question Answering (VQA), TQA contains a large number of uncommon terminologies and various diagram inputs. It brings new challenges to the representation capability of language model for domain-specific spans. And it also pushes the multimodal fusion to a more complex level. To tackle the above issues, we propose a novel model named MoCA, which incorporates multi-stage domain pretraining and multimodal cross attention for the TQA task. Firstly, we introduce a multi-stage domain pretraining module to conduct unsupervised post-pretraining with the span mask strategy and supervised pre-finetune. Especially for domain post-pretraining, we propose a heuristic generation algorithm to employ the terminology corpus. Secondly, to fully consider the rich inputs of context and diagrams, we propose cross-guided multimodal attention to update the features of text, question diagram and instructional diagram based on a progressive strategy. Further, a dual gating mechanism is adopted to improve the model ensemble. The experimental results show the superiority of our model, which outperforms the state-of-the-art methods by 2.21% and 2.43% for validation and test split respectively.