 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolveNav: Proactive Preflection and Self-Evolving Memory for Zero-Shot Object Goal Navigation
Jun 16, 2026Zero-Shot Object-Goal Navigation (ZS-OGN) requires embodied agents to explore and locate target objects without any prior training. To this end, recent methods leverage foundation models. But they typically rely on static priors and lack adaptation, which leads to repeated errors and costly trial and error. In this paper, we propose a self-evolving ZS-OGN framework that enables continuous test-time improvement. Specifically, we build an agentic rule memory by extracting actionable knowledge from past trajectories. Then, we propose a retrieval strategy based on upper confidence bound, selecting effective rules by balancing semantic relevance and historical success. In addition, we introduce a memory-guided preflection module that forecasts potential outcomes before action, reducing inefficient exploration. Extensive experiments show that our method outperforms existing zero-shot baselines, achieving a 10.1\% improvement in success rate with fewer unnecessary steps.
VistaWise: Building Cost-Effective Agent with Cross-Modal Knowledge Graph for Minecraft
Aug 26, 2025Large language models (LLMs) have shown significant promise in embodied decision-making tasks within virtual open-world environments. Nonetheless, their performance is hindered by the absence of domain-specific knowledge. Methods that finetune on large-scale domain-specific data entail prohibitive development costs. This paper introduces VistaWise, a cost-effective agent framework that integrates cross-modal domain knowledge and finetunes a dedicated object detection model for visual analysis. It reduces the requirement for domain-specific training data from millions of samples to a few hundred. VistaWise integrates visual information and textual dependencies into a cross-modal knowledge graph (KG), enabling a comprehensive and accurate understanding of multimodal environments. We also equip the agent with a retrieval-based pooling strategy to extract task-related information from the KG, and a desktop-level skill library to support direct operation of the Minecraft desktop client via mouse and keyboard inputs. Experimental results demonstrate that VistaWise achieves state-of-the-art performance across various open-world tasks, highlighting its effectiveness in reducing development costs while enhancing agent performance.
CausalMACE: Causality Empowered Multi-Agents in Minecraft Cooperative Tasks
Aug 26, 2025Minecraft, as an open-world virtual interactive environment, has become a prominent platform for research on agent decision-making and execution. Existing works primarily adopt a single Large Language Model (LLM) agent to complete various in-game tasks. However, for complex tasks requiring lengthy sequences of actions, single-agent approaches often face challenges related to inefficiency and limited fault tolerance. Despite these issues, research on multi-agent collaboration remains scarce. In this paper, we propose CausalMACE, a holistic causality planning framework designed to enhance multi-agent systems, in which we incorporate causality to manage dependencies among subtasks. Technically, our proposed framework introduces two modules: an overarching task graph for global task planning and a causality-based module for dependency management, where inherent rules are adopted to perform causal intervention. Experimental results demonstrate our approach achieves state-of-the-art performance in multi-agent cooperative tasks of Minecraft.
Interpreting Fedspeak with Confidence: A LLM-Based Uncertainty-Aware Framework Guided by Monetary Policy Transmission Paths
Aug 12, 2025"Fedspeak", the stylized and often nuanced language used by the U.S. Federal Reserve, encodes implicit policy signals and strategic stances. The Federal Open Market Committee strategically employs Fedspeak as a communication tool to shape market expectations and influence both domestic and global economic conditions. As such, automatically parsing and interpreting Fedspeak presents a high-impact challenge, with significant implications for financial forecasting, algorithmic trading, and data-driven policy analysis. In this paper, we propose an LLM-based, uncertainty-aware framework for deciphering Fedspeak and classifying its underlying monetary policy stance. Technically, to enrich the semantic and contextual representation of Fedspeak texts, we incorporate domain-specific reasoning grounded in the monetary policy transmission mechanism. We further introduce a dynamic uncertainty decoding module to assess the confidence of model predictions, thereby enhancing both classification accuracy and model reliability. Experimental results demonstrate that our framework achieves state-of-the-art performance on the policy stance analysis task. Moreover, statistical analysis reveals a significant positive correlation between perceptual uncertainty and model error rates, validating the effectiveness of perceptual uncertainty as a diagnostic signal.
MultiMind: Enhancing Werewolf Agents with Multimodal Reasoning and Theory of Mind
Apr 25, 2025Large Language Model (LLM) agents have demonstrated impressive capabilities in social deduction games (SDGs) like Werewolf, where strategic reasoning and social deception are essential. However, current approaches remain limited to textual information, ignoring crucial multimodal cues such as facial expressions and tone of voice that humans naturally use to communicate. Moreover, existing SDG agents primarily focus on inferring other players' identities without modeling how others perceive themselves or fellow players. To address these limitations, we use One Night Ultimate Werewolf (ONUW) as a testbed and present MultiMind, the first framework integrating multimodal information into SDG agents. MultiMind processes facial expressions and vocal tones alongside verbal content, while employing a Theory of Mind (ToM) model to represent each player's suspicion levels toward others. By combining this ToM model with Monte Carlo Tree Search (MCTS), our agent identifies communication strategies that minimize suspicion directed at itself. Through comprehensive evaluation in both agent-versus-agent simulations and studies with human players, we demonstrate MultiMind's superior performance in gameplay. Our work presents a significant advancement toward LLM agents capable of human-like social reasoning across multimodal domains.
FortisAVQA and MAVEN: a Benchmark Dataset and Debiasing Framework for Robust Multimodal Reasoning
Apr 02, 2025
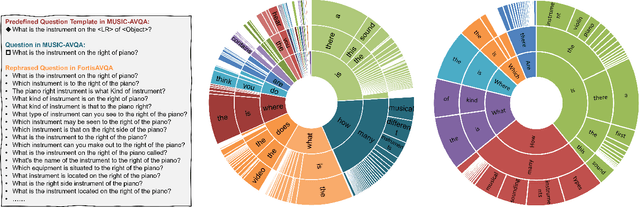
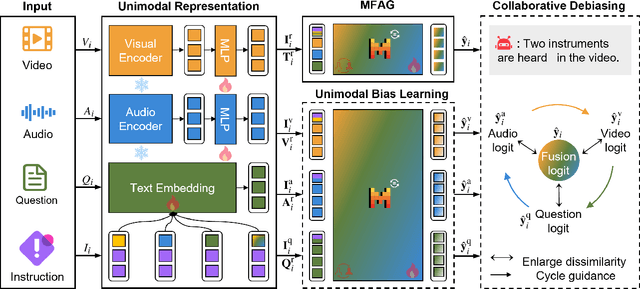
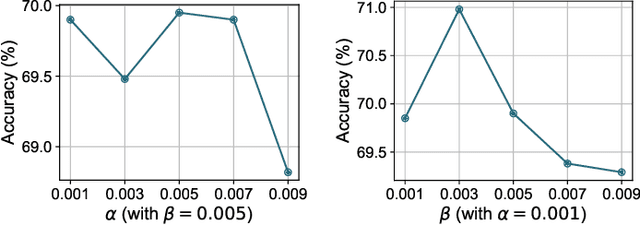
Audio-Visual Question Answering (AVQA) is a challenging multimodal reasoning task requiring intelligent systems to answer natural language queries based on paired audio-video inputs accurately. However, existing AVQA approaches often suffer from overfitting to dataset biases, leading to poor robustness. Moreover, current datasets may not effectively diagnose these methods. To address these challenges, we first introduce a novel dataset, FortisAVQA, constructed in two stages: (1) rephrasing questions in the test split of the public MUSIC-AVQA dataset and (2) introducing distribution shifts across questions. The first stage expands the test space with greater diversity, while the second enables a refined robustness evaluation across rare, frequent, and overall question distributions. Second, we introduce a robust Multimodal Audio-Visual Epistemic Network (MAVEN) that leverages a multifaceted cycle collaborative debiasing strategy to mitigate bias learning. Experimental results demonstrate that our architecture achieves state-of-the-art performance on FortisAVQA, with a notable improvement of 7.81\%. Extensive ablation studies on both datasets validate the effectiveness of our debiasing components. Additionally, our evaluation reveals the limited robustness of existing multimodal QA methods. We also verify the plug-and-play capability of our strategy by integrating it with various baseline models across both datasets. Our dataset and code are available at https://github.com/reml-group/fortisavqa.
Debate on Graph: a Flexible and Reliable Reasoning Framework for Large Language Models
Sep 05, 2024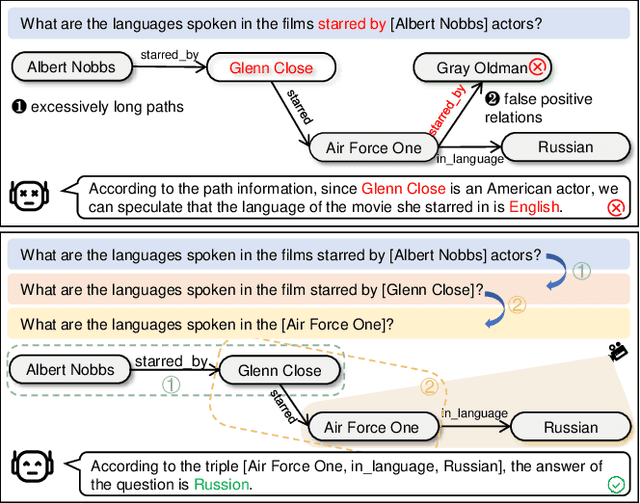
Large Language Models (LLMs) may suffer from hallucinations in real-world applications due to the lack of relevant knowledge. In contrast, knowledge graphs encompass extensive, multi-relational structures that store a vast array of symbolic facts. Consequently, integrating LLMs with knowledge graphs has been extensively explored, with Knowledge Graph Question Answering (KGQA) serving as a critical touchstone for the integration. This task requires LLMs to answer natural language questions by retrieving relevant triples from knowledge graphs. However, existing methods face two significant challenges: \textit{excessively long reasoning paths distracting from the answer generation}, and \textit{false-positive relations hindering the path refinement}. In this paper, we propose an iterative interactive KGQA framework that leverages the interactive learning capabilities of LLMs to perform reasoning and Debating over Graphs (DoG). Specifically, DoG employs a subgraph-focusing mechanism, allowing LLMs to perform answer trying after each reasoning step, thereby mitigating the impact of lengthy reasoning paths. On the other hand, DoG utilizes a multi-role debate team to gradually simplify complex questions, reducing the influence of false-positive relations. This debate mechanism ensures the reliability of the reasoning process. Experimental results on five public datasets demonstrate the effectiveness and superiority of our architecture. Notably, DoG outperforms the state-of-the-art method ToG by 23.7\% and 9.1\% in accuracy on WebQuestions and GrailQA, respectively. Furthermore, the integration experiments with various LLMs on the mentioned datasets highlight the flexibility of DoG. Code is available at \url{https://github.com/reml-group/DoG}.
MoCA: Incorporating Multi-stage Domain Pretraining and Cross-guided Multimodal Attention for Textbook Question Answering
Dec 06, 2021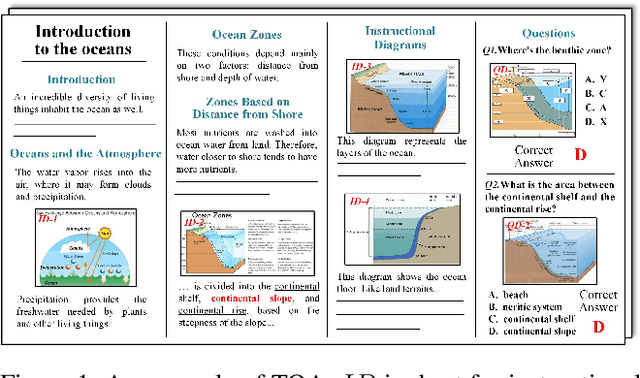

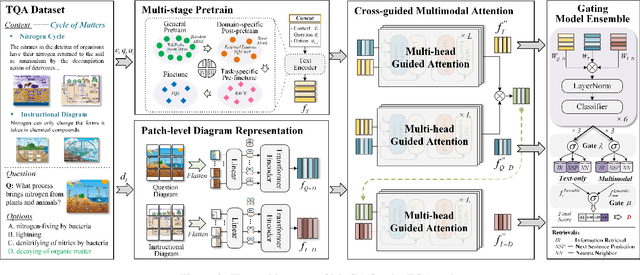
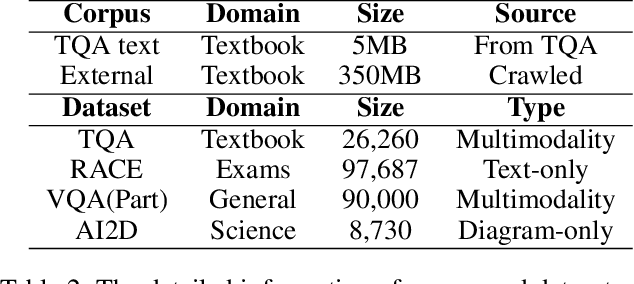
Textbook Question Answering (TQA) is a complex multimodal task to infer answers given large context descriptions and abundant diagrams. Compared with Visual Question Answering (VQA), TQA contains a large number of uncommon terminologies and various diagram inputs. It brings new challenges to the representation capability of language model for domain-specific spans. And it also pushes the multimodal fusion to a more complex level. To tackle the above issues, we propose a novel model named MoCA, which incorporates multi-stage domain pretraining and multimodal cross attention for the TQA task. Firstly, we introduce a multi-stage domain pretraining module to conduct unsupervised post-pretraining with the span mask strategy and supervised pre-finetune. Especially for domain post-pretraining, we propose a heuristic generation algorithm to employ the terminology corpus. Secondly, to fully consider the rich inputs of context and diagrams, we propose cross-guided multimodal attention to update the features of text, question diagram and instructional diagram based on a progressive strategy. Further, a dual gating mechanism is adopted to improve the model ensemble. The experimental results show the superiority of our model, which outperforms the state-of-the-art methods by 2.21% and 2.43% for validation and test split respectively.