 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiniCPM-SALA: Hybridizing Sparse and Linear Attention for Efficient Long-Context Modeling
Feb 12, 2026The evolution of large language models (LLMs) towards applications with ultra-long contexts faces challenges posed by the high computational and memory costs of the Transformer architecture. While existing sparse and linear attention mechanisms attempt to mitigate these issues, they typically involve a trade-off between memory efficiency and model performance. This paper introduces MiniCPM-SALA, a 9B-parameter hybrid architecture that integrates the high-fidelity long-context modeling of sparse attention (InfLLM-V2) with the global efficiency of linear attention (Lightning Attention). By employing a layer selection algorithm to integrate these mechanisms in a 1:3 ratio and utilizing a hybrid positional encoding (HyPE), the model maintains efficiency and performance for long-context tasks. Furthermore, we introduce a cost-effective continual training framework that transforms pre-trained Transformer-based models into hybrid models, which reduces training costs by approximately 75% compared to training from scratch. Extensive experiments show that MiniCPM-SALA maintains general capabilities comparable to full-attention models while offering improved efficiency. On a single NVIDIA A6000D GPU, the model achieves up to 3.5x the inference speed of the full-attention model at the sequence length of 256K tokens and supports context lengths of up to 1M tokens, a scale where traditional full-attention 8B models fail because of memory constraints.
Pinching Antenna-aided NOMA Systems with Internal Eavesdropping
Dec 25, 2025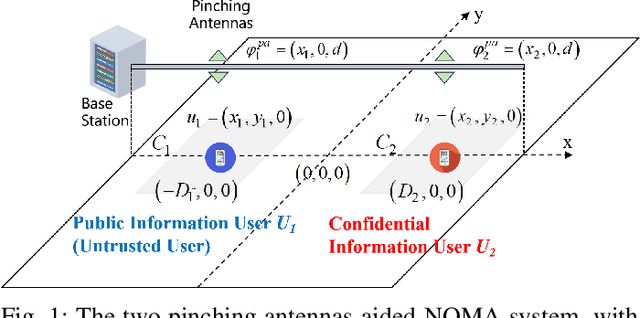
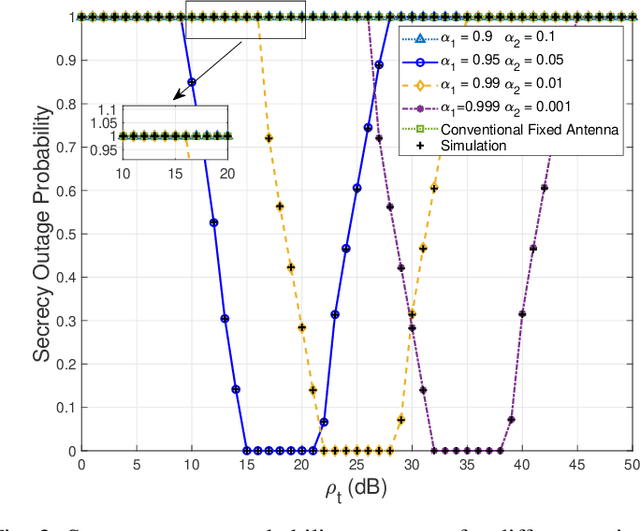
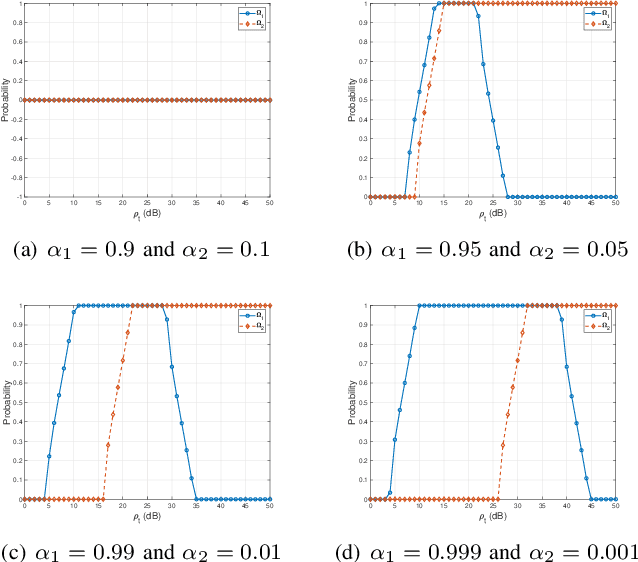
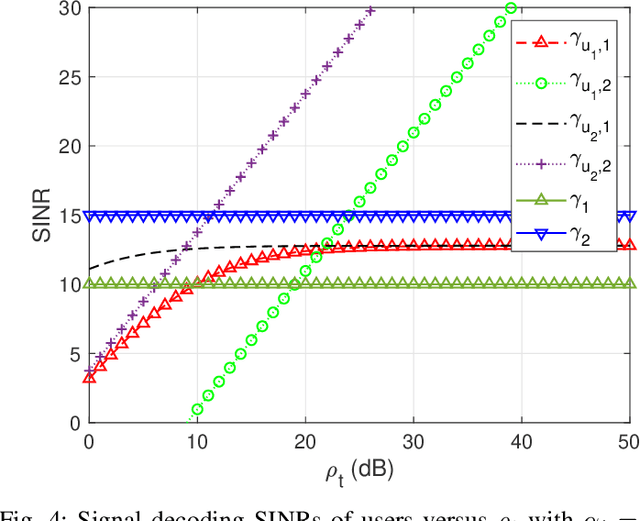
As a novel member of flexible antennas, the pinching antenna (PA) is realized by integrating small dielectric particles on a waveguide, offering unique regulatory capabilities on constructing line-of-sight (LoS) links and enhancing transceiver channels, reducing path loss and signal blockage. Meanwhile, non-orthogonal multiple access (NOMA) has become a potential technology of next-generation communications due to its remarkable advantages in spectrum efficiency and user access capability. The integration of PA and NOMA enables synergistic leveraging of PA's channel regulation capability and NOMA's multi-user multiplexing advantage, forming a complementary technical framework to deliver high-performance communication solutions. However, the use of successive interference cancellation (SIC) introduces significant security risks to power-domain NOMA systems when internal eavesdropping is present. To this end, this paper investigates the physical layer security of a PA-aided NOMA system where a nearby user is considered as an internal eavesdropper. We enhance the security of the NOMA system through optimizing the radiated power of PAs and analyze the secrecy performance by deriving the closed-form expressions for the secrecy outage probability (SOP). Furthermore, we extend the characterization of PA flexibility beyond deployment and scale adjustment to include flexible regulation of PA coupling length. Based on two conventional PA power models, i.e., the equal power model and the proportional power model, we propose a flexible power strategy to achieve secure transmission. The results highlight the potential of the PA-aided NOMA system in mitigating internal eavesdropping risks, and provide an effective strategy for optimizing power allocation and cell range of user activity.
Enabling Regulatory Multi-Agent Collaboration: Architecture, Challenges, and Solutions
Sep 11, 2025



Large language models (LLMs)-empowered autonomous agents are transforming both digital and physical environments by enabling adaptive, multi-agent collaboration. While these agents offer significant opportunities across domains such as finance, healthcare, and smart manufacturing, their unpredictable behaviors and heterogeneous capabilities pose substantial governance and accountability challenges. In this paper, we propose a blockchain-enabled layered architecture for regulatory agent collaboration, comprising an agent layer, a blockchain data layer, and a regulatory application layer. Within this framework, we design three key modules: (i) an agent behavior tracing and arbitration module for automated accountability, (ii) a dynamic reputation evaluation module for trust assessment in collaborative scenarios, and (iii) a malicious behavior forecasting module for early detection of adversarial activities. Our approach establishes a systematic foundation for trustworthy, resilient, and scalable regulatory mechanisms in large-scale agent ecosystems. Finally, we discuss the future research directions for blockchain-enabled regulatory frameworks in multi-agent systems.
Federated Fine-Tuning of Sparsely-Activated Large Language Models on Resource-Constrained Devices
Aug 26, 2025Federated fine-tuning of Mixture-of-Experts (MoE)-based large language models (LLMs) is challenging due to their massive computational requirements and the resource constraints of participants. Existing working attempts to fill this gap through model quantization, computation offloading, or expert pruning. However, they cannot achieve desired performance due to impractical system assumptions and a lack of consideration for MoE-specific characteristics. In this paper, we propose FLUX, a system designed to enable federated fine-tuning of MoE-based LLMs across participants with constrained computing resources (e.g., consumer-grade GPUs), aiming to minimize time-to-accuracy. FLUX introduces three key innovations: (1) quantization-based local profiling to estimate expert activation with minimal overhead, (2) adaptive layer-aware expert merging to reduce resource consumption while preserving accuracy, and (3) dynamic expert role assignment using an exploration-exploitation strategy to balance tuning and non-tuning experts. Extensive experiments on LLaMA-MoE and DeepSeek-MoE with multiple benchmark datasets demonstrate that FLUX significantly outperforms existing methods, achieving up to 4.75X speedup in time-to-accuracy.
MiniCPM4: Ultra-Efficient LLMs on End Devices
Jun 09, 2025



This paper introduces MiniCPM4, a highly efficient large language model (LLM) designed explicitly for end-side devices. We achieve this efficiency through systematic innovation in four key dimensions: model architecture, training data, training algorithms, and inference systems. Specifically, in terms of model architecture, we propose InfLLM v2, a trainable sparse attention mechanism that accelerates both prefilling and decoding phases for long-context processing. Regarding training data, we propose UltraClean, an efficient and accurate pre-training data filtering and generation strategy, and UltraChat v2, a comprehensive supervised fine-tuning dataset. These datasets enable satisfactory model performance to be achieved using just 8 trillion training tokens. Regarding training algorithms, we propose ModelTunnel v2 for efficient pre-training strategy search, and improve existing post-training methods by introducing chunk-wise rollout for load-balanced reinforcement learning and data-efficient tenary LLM, BitCPM. Regarding inference systems, we propose CPM.cu that integrates sparse attention, model quantization, and speculative sampling to achieve efficient prefilling and decoding. To meet diverse on-device requirements, MiniCPM4 is available in two versions, with 0.5B and 8B parameters, respectively. Sufficient evaluation results show that MiniCPM4 outperforms open-source models of similar size across multiple benchmarks, highlighting both its efficiency and effectiveness. Notably, MiniCPM4-8B demonstrates significant speed improvements over Qwen3-8B when processing long sequences. Through further adaptation, MiniCPM4 successfully powers diverse applications, including trustworthy survey generation and tool use with model context protocol, clearly showcasing its broad usability.
Deliberation on Priors: Trustworthy Reasoning of Large Language Models on Knowledge Graphs
May 21, 2025Knowledge graph-based retrieval-augmented generation seeks to mitigate hallucinations in Large Language Models (LLMs) caused by insufficient or outdated knowledge. However, existing methods often fail to fully exploit the prior knowledge embedded in knowledge graphs (KGs), particularly their structural information and explicit or implicit constraints. The former can enhance the faithfulness of LLMs' reasoning, while the latter can improve the reliability of response generation. Motivated by these, we propose a trustworthy reasoning framework, termed Deliberation over Priors (DP), which sufficiently utilizes the priors contained in KGs. Specifically, DP adopts a progressive knowledge distillation strategy that integrates structural priors into LLMs through a combination of supervised fine-tuning and Kahneman-Tversky optimization, thereby improving the faithfulness of relation path generation. Furthermore, our framework employs a reasoning-introspection strategy, which guides LLMs to perform refined reasoning verification based on extracted constraint priors, ensuring the reliability of response generation. Extensive experiments on three benchmark datasets demonstrate that DP achieves new state-of-the-art performance, especially a Hit@1 improvement of 13% on the ComplexWebQuestions dataset, and generates highly trustworthy responses. We also conduct various analyses to verify its flexibility and practicality. The code is available at https://github.com/reml-group/Deliberation-on-Priors.
Internet of Agents: Fundamentals, Applications, and Challenges
May 12, 2025



With the rapid proliferation of large language models and vision-language models, AI agents have evolved from isolated, task-specific systems into autonomous, interactive entities capable of perceiving, reasoning, and acting without human intervention. As these agents proliferate across virtual and physical environments, from virtual assistants to embodied robots, the need for a unified, agent-centric infrastructure becomes paramount. In this survey, we introduce the Internet of Agents (IoA) as a foundational framework that enables seamless interconnection, dynamic discovery, and collaborative orchestration among heterogeneous agents at scale. We begin by presenting a general IoA architecture, highlighting its hierarchical organization, distinguishing features relative to the traditional Internet, and emerging applications. Next, we analyze the key operational enablers of IoA, including capability notification and discovery, adaptive communication protocols, dynamic task matching, consensus and conflict-resolution mechanisms, and incentive models. Finally, we identify open research directions toward building resilient and trustworthy IoA ecosystems.
Security of Internet of Agents: Attacks and Countermeasures
May 12, 2025With the rise of large language and vision-language models, AI agents have evolved into autonomous, interactive systems capable of perception, reasoning, and decision-making. As they proliferate across virtual and physical domains, the Internet of Agents (IoA) has emerged as a key infrastructure for enabling scalable and secure coordination among heterogeneous agents. This survey offers a comprehensive examination of the security and privacy landscape in IoA systems. We begin by outlining the IoA architecture and its distinct vulnerabilities compared to traditional networks, focusing on four critical aspects: identity authentication threats, cross-agent trust issues, embodied security, and privacy risks. We then review existing and emerging defense mechanisms and highlight persistent challenges. Finally, we identify open research directions to advance the development of resilient and privacy-preserving IoA ecosystems.
ArtistAuditor: Auditing Artist Style Pirate in Text-to-Image Generation Models
Apr 17, 2025Text-to-image models based on diffusion processes, such as DALL-E, Stable Diffusion, and Midjourney, are capable of transforming texts into detailed images and have widespread applications in art and design. As such, amateur users can easily imitate professional-level paintings by collecting an artist's work and fine-tuning the model, leading to concerns about artworks' copyright infringement. To tackle these issues, previous studies either add visually imperceptible perturbation to the artwork to change its underlying styles (perturbation-based methods) or embed post-training detectable watermarks in the artwork (watermark-based methods). However, when the artwork or the model has been published online, i.e., modification to the original artwork or model retraining is not feasible, these strategies might not be viable. To this end, we propose a novel method for data-use auditing in the text-to-image generation model. The general idea of ArtistAuditor is to identify if a suspicious model has been finetuned using the artworks of specific artists by analyzing the features related to the style. Concretely, ArtistAuditor employs a style extractor to obtain the multi-granularity style representations and treats artworks as samplings of an artist's style. Then, ArtistAuditor queries a trained discriminator to gain the auditing decisions. The experimental results on six combinations of models and datasets show that ArtistAuditor can achieve high AUC values (> 0.937). By studying ArtistAuditor's transferability and core modules, we provide valuable insights into the practical implementation. Finally, we demonstrate the effectiveness of ArtistAuditor in real-world cases by an online platform Scenario. ArtistAuditor is open-sourced at https://github.com/Jozenn/ArtistAuditor.
FortisAVQA and MAVEN: a Benchmark Dataset and Debiasing Framework for Robust Multimodal Reasoning
Apr 02, 2025
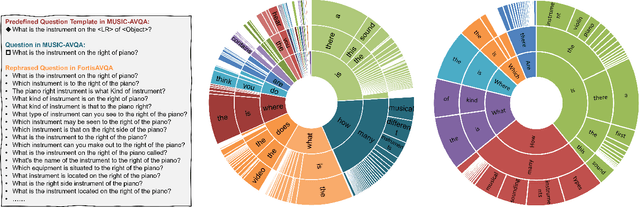
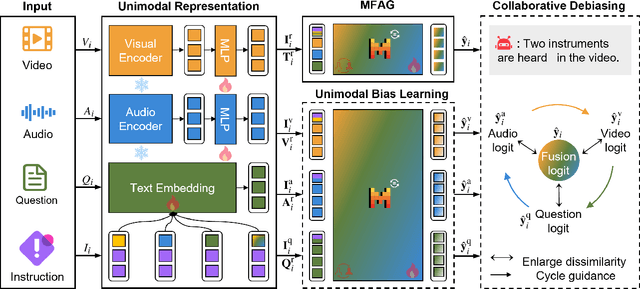
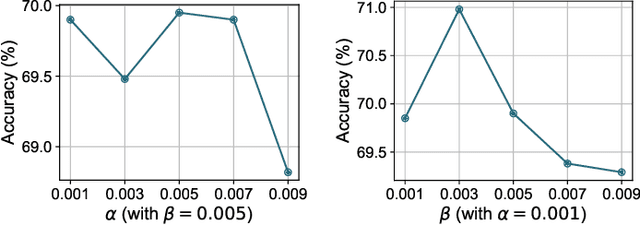
Audio-Visual Question Answering (AVQA) is a challenging multimodal reasoning task requiring intelligent systems to answer natural language queries based on paired audio-video inputs accurately. However, existing AVQA approaches often suffer from overfitting to dataset biases, leading to poor robustness. Moreover, current datasets may not effectively diagnose these methods. To address these challenges, we first introduce a novel dataset, FortisAVQA, constructed in two stages: (1) rephrasing questions in the test split of the public MUSIC-AVQA dataset and (2) introducing distribution shifts across questions. The first stage expands the test space with greater diversity, while the second enables a refined robustness evaluation across rare, frequent, and overall question distributions. Second, we introduce a robust Multimodal Audio-Visual Epistemic Network (MAVEN) that leverages a multifaceted cycle collaborative debiasing strategy to mitigate bias learning. Experimental results demonstrate that our architecture achieves state-of-the-art performance on FortisAVQA, with a notable improvement of 7.81\%. Extensive ablation studies on both datasets validate the effectiveness of our debiasing components. Additionally, our evaluation reveals the limited robustness of existing multimodal QA methods. We also verify the plug-and-play capability of our strategy by integrating it with various baseline models across both datasets. Our dataset and code are available at https://github.com/reml-group/fortisavqa.