 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInFi-Check: Interpretable and Fine-Grained Fact-Checking of LLMs
Jan 10, 2026Large language models (LLMs) often hallucinate, yet most existing fact-checking methods treat factuality evaluation as a binary classification problem, offering limited interpretability and failing to capture fine-grained error types. In this paper, we introduce InFi-Check, a framework for interpretable and fine-grained fact-checking of LLM outputs. Specifically, we first propose a controlled data synthesis pipeline that generates high-quality data featuring explicit evidence, fine-grained error type labels, justifications, and corrections. Based on this, we further construct large-scale training data and a manually verified benchmark InFi-Check-FG for fine-grained fact-checking of LLM outputs. Building on these high-quality training data, we further propose InFi-Checker, which can jointly provide supporting evidence, classify fine-grained error types, and produce justifications along with corrections. Experiments show that InFi-Checker achieves state-of-the-art performance on InFi-Check-FG and strong generalization across various downstream tasks, significantly improving the utility and trustworthiness of factuality evaluation.
MEIC-DT: Memory-Efficient Incremental Clustering for Long-Text Coreference Resolution with Dual-Threshold Constraints
Dec 31, 2025In the era of large language models (LLMs), supervised neural methods remain the state-of-the-art (SOTA) for Coreference Resolution. Yet, their full potential is underexplored, particularly in incremental clustering, which faces the critical challenge of balancing efficiency with performance for long texts. To address the limitation, we propose \textbf{MEIC-DT}, a novel dual-threshold, memory-efficient incremental clustering approach based on a lightweight Transformer. MEIC-DT features a dual-threshold constraint mechanism designed to precisely control the Transformer's input scale within a predefined memory budget. This mechanism incorporates a Statistics-Aware Eviction Strategy (\textbf{SAES}), which utilizes distinct statistical profiles from the training and inference phases for intelligent cache management. Furthermore, we introduce an Internal Regularization Policy (\textbf{IRP}) that strategically condenses clusters by selecting the most representative mentions, thereby preserving semantic integrity. Extensive experiments on common benchmarks demonstrate that MEIC-DT achieves highly competitive coreference performance under stringent memory constraints.
FaithLens: Detecting and Explaining Faithfulness Hallucination
Dec 23, 2025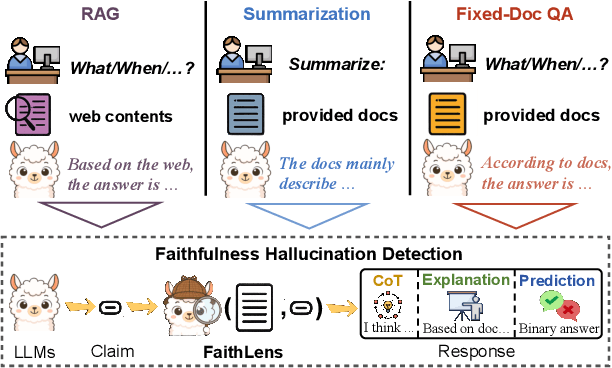
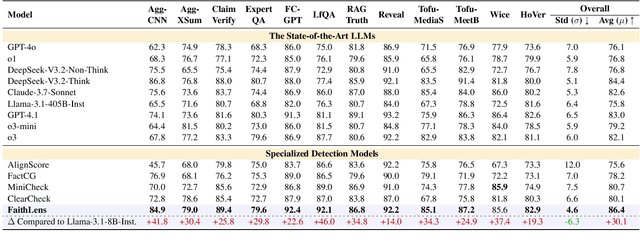
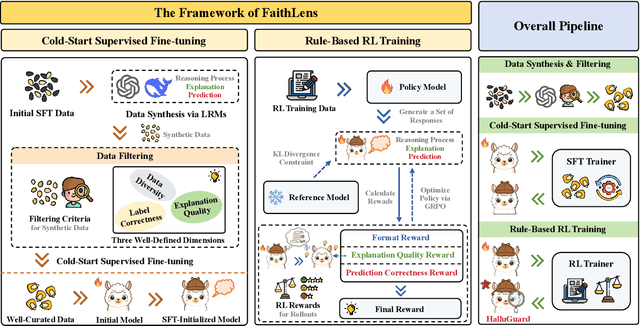
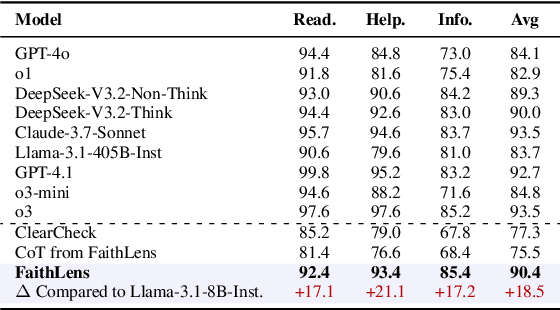
Recognizing whether outputs from large language models (LLMs) contain faithfulness hallucination is crucial for real-world applications, e.g., retrieval-augmented generation and summarization. In this paper, we introduce FaithLens, a cost-efficient and effective faithfulness hallucination detection model that can jointly provide binary predictions and corresponding explanations to improve trustworthiness. To achieve this, we first synthesize training data with explanations via advanced LLMs and apply a well-defined data filtering strategy to ensure label correctness, explanation quality, and data diversity. Subsequently, we fine-tune the model on these well-curated training data as a cold start and further optimize it with rule-based reinforcement learning, using rewards for both prediction correctness and explanation quality. Results on 12 diverse tasks show that the 8B-parameter FaithLens outperforms advanced models such as GPT-4.1 and o3. Also, FaithLens can produce high-quality explanations, delivering a distinctive balance of trustworthiness, efficiency, and effectiveness.
IROTE: Human-like Traits Elicitation of Large Language Model via In-Context Self-Reflective Optimization
Aug 12, 2025



Trained on various human-authored corpora, Large Language Models (LLMs) have demonstrated a certain capability of reflecting specific human-like traits (e.g., personality or values) by prompting, benefiting applications like personalized LLMs and social simulations. However, existing methods suffer from the superficial elicitation problem: LLMs can only be steered to mimic shallow and unstable stylistic patterns, failing to embody the desired traits precisely and consistently across diverse tasks like humans. To address this challenge, we propose IROTE, a novel in-context method for stable and transferable trait elicitation. Drawing on psychological theories suggesting that traits are formed through identity-related reflection, our method automatically generates and optimizes a textual self-reflection within prompts, which comprises self-perceived experience, to stimulate LLMs' trait-driven behavior. The optimization is performed by iteratively maximizing an information-theoretic objective that enhances the connections between LLMs' behavior and the target trait, while reducing noisy redundancy in reflection without any fine-tuning, leading to evocative and compact trait reflection. Extensive experiments across three human trait systems manifest that one single IROTE-generated self-reflection can induce LLMs' stable impersonation of the target trait across diverse downstream tasks beyond simple questionnaire answering, consistently outperforming existing strong baselines.
MiniCPM4: Ultra-Efficient LLMs on End Devices
Jun 09, 2025



This paper introduces MiniCPM4, a highly efficient large language model (LLM) designed explicitly for end-side devices. We achieve this efficiency through systematic innovation in four key dimensions: model architecture, training data, training algorithms, and inference systems. Specifically, in terms of model architecture, we propose InfLLM v2, a trainable sparse attention mechanism that accelerates both prefilling and decoding phases for long-context processing. Regarding training data, we propose UltraClean, an efficient and accurate pre-training data filtering and generation strategy, and UltraChat v2, a comprehensive supervised fine-tuning dataset. These datasets enable satisfactory model performance to be achieved using just 8 trillion training tokens. Regarding training algorithms, we propose ModelTunnel v2 for efficient pre-training strategy search, and improve existing post-training methods by introducing chunk-wise rollout for load-balanced reinforcement learning and data-efficient tenary LLM, BitCPM. Regarding inference systems, we propose CPM.cu that integrates sparse attention, model quantization, and speculative sampling to achieve efficient prefilling and decoding. To meet diverse on-device requirements, MiniCPM4 is available in two versions, with 0.5B and 8B parameters, respectively. Sufficient evaluation results show that MiniCPM4 outperforms open-source models of similar size across multiple benchmarks, highlighting both its efficiency and effectiveness. Notably, MiniCPM4-8B demonstrates significant speed improvements over Qwen3-8B when processing long sequences. Through further adaptation, MiniCPM4 successfully powers diverse applications, including trustworthy survey generation and tool use with model context protocol, clearly showcasing its broad usability.
Teaching Large Language Models to Maintain Contextual Faithfulness via Synthetic Tasks and Reinforcement Learning
May 22, 2025Teaching large language models (LLMs) to be faithful in the provided context is crucial for building reliable information-seeking systems. Therefore, we propose a systematic framework, CANOE, to improve the faithfulness of LLMs in both short-form and long-form generation tasks without human annotations. Specifically, we first synthesize short-form question-answering (QA) data with four diverse tasks to construct high-quality and easily verifiable training data without human annotation. Also, we propose Dual-GRPO, a rule-based reinforcement learning method that includes three tailored rule-based rewards derived from synthesized short-form QA data, while simultaneously optimizing both short-form and long-form response generation. Notably, Dual-GRPO eliminates the need to manually label preference data to train reward models and avoids over-optimizing short-form generation when relying only on the synthesized short-form QA data. Experimental results show that CANOE greatly improves the faithfulness of LLMs across 11 different downstream tasks, even outperforming the most advanced LLMs, e.g., GPT-4o and OpenAI o1.
GLTW: Joint Improved Graph Transformer and LLM via Three-Word Language for Knowledge Graph Completion
Feb 17, 2025Knowledge Graph Completion (KGC), which aims to infer missing or incomplete facts, is a crucial task for KGs. However, integrating the vital structural information of KGs into Large Language Models (LLMs) and outputting predictions deterministically remains challenging. To address this, we propose a new method called GLTW, which encodes the structural information of KGs and merges it with LLMs to enhance KGC performance. Specifically, we introduce an improved Graph Transformer (iGT) that effectively encodes subgraphs with both local and global structural information and inherits the characteristics of language model, bypassing training from scratch. Also, we develop a subgraph-based multi-classification training objective, using all entities within KG as classification objects, to boost learning efficiency.Importantly, we combine iGT with an LLM that takes KG language prompts as input.Our extensive experiments on various KG datasets show that GLTW achieves significant performance gains compared to SOTA baselines.
Aligning Large Language Models to Follow Instructions and Hallucinate Less via Effective Data Filtering
Feb 11, 2025Training LLMs on data that contains unfamiliar knowledge during the instruction tuning stage can make LLMs overconfident and encourage hallucinations. To address this challenge, we introduce a novel framework, NOVA, which identifies high-quality data that aligns well with the LLM's learned knowledge to reduce hallucinations. NOVA includes Internal Consistency Probing (ICP) and Semantic Equivalence Identification (SEI) to measure how familiar the LLM is with instruction data. Specifically, ICP evaluates the LLM's understanding of the given instruction by calculating the tailored consistency among multiple self-generated responses. SEI further assesses the familiarity of the LLM with the target response by comparing it to the generated responses, using the proposed semantic clustering and well-designed voting strategy. Finally, we introduce an expert-aligned reward model, considering characteristics beyond just familiarity to enhance data quality. By considering data quality and avoiding unfamiliar data, we can utilize the selected data to effectively align LLMs to follow instructions and hallucinate less. Extensive experiments and analysis show that NOVA significantly reduces hallucinations and allows LLMs to maintain a strong ability to follow instructions.
Value Compass Leaderboard: A Platform for Fundamental and Validated Evaluation of LLMs Values
Jan 13, 2025As Large Language Models (LLMs) achieve remarkable breakthroughs, aligning their values with humans has become imperative for their responsible development and customized applications. However, there still lack evaluations of LLMs values that fulfill three desirable goals. (1) Value Clarification: We expect to clarify the underlying values of LLMs precisely and comprehensively, while current evaluations focus narrowly on safety risks such as bias and toxicity. (2) Evaluation Validity: Existing static, open-source benchmarks are prone to data contamination and quickly become obsolete as LLMs evolve. Additionally, these discriminative evaluations uncover LLMs' knowledge about values, rather than valid assessments of LLMs' behavioral conformity to values. (3) Value Pluralism: The pluralistic nature of human values across individuals and cultures is largely ignored in measuring LLMs value alignment. To address these challenges, we presents the Value Compass Leaderboard, with three correspondingly designed modules. It (i) grounds the evaluation on motivationally distinct \textit{basic values to clarify LLMs' underlying values from a holistic view; (ii) applies a \textit{generative evolving evaluation framework with adaptive test items for evolving LLMs and direct value recognition from behaviors in realistic scenarios; (iii) propose a metric that quantifies LLMs alignment with a specific value as a weighted sum over multiple dimensions, with weights determined by pluralistic values.
OlympiadBench: A Challenging Benchmark for Promoting AGI with Olympiad-Level Bilingual Multimodal Scientific Problems
Feb 21, 2024



Recent advancements have seen Large Language Models (LLMs) and Large Multimodal Models (LMMs) surpassing general human capabilities in various tasks, approaching the proficiency level of human experts across multiple domains. With traditional benchmarks becoming less challenging for these models, new rigorous challenges are essential to gauge their advanced abilities. In this work, we present OlympiadBench, an Olympiad-level bilingual multimodal scientific benchmark, featuring 8,952 problems from Olympiad-level mathematics and physics competitions, including the Chinese college entrance exam. Each problem is detailed with expert-level annotations for step-by-step reasoning. Evaluating top-tier models on OlympiadBench, we implement a comprehensive assessment methodology to accurately evaluate model responses. Notably, the best-performing model, GPT-4V, attains an average score of 17.23% on OlympiadBench, with a mere 11.28% in physics, highlighting the benchmark rigor and the intricacy of physical reasoning. Our analysis orienting GPT-4V points out prevalent issues with hallucinations, knowledge omissions, and logical fallacies. We hope that our challenging benchmark can serve as a valuable resource for helping future AGI research endeavors.