 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHER: Human-like Reasoning and Reinforcement Learning for LLM Role-playing
Jan 29, 2026LLM role-playing, i.e., using LLMs to simulate specific personas, has emerged as a key capability in various applications, such as companionship, content creation, and digital games. While current models effectively capture character tones and knowledge, simulating the inner thoughts behind their behaviors remains a challenge. Towards cognitive simulation in LLM role-play, previous efforts mainly suffer from two deficiencies: data with high-quality reasoning traces, and reliable reward signals aligned with human preferences. In this paper, we propose HER, a unified framework for cognitive-level persona simulation. HER introduces dual-layer thinking, which distinguishes characters' first-person thinking from LLMs' third-person thinking. To bridge these gaps, we curate reasoning-augmented role-playing data via reverse engineering and construct human-aligned principles and reward models. Leveraging these resources, we train \method models based on Qwen3-32B via supervised and reinforcement learning. Extensive experiments validate the effectiveness of our approach. Notably, our models significantly outperform the Qwen3-32B baseline, achieving a 30.26 improvement on the CoSER benchmark and a 14.97 gain on the Minimax Role-Play Bench. Our datasets, principles, and models will be released to facilitate future research.
The Tool Decathlon: Benchmarking Language Agents for Diverse, Realistic, and Long-Horizon Task Execution
Oct 29, 2025Real-world language agents must handle complex, multi-step workflows across diverse Apps. For instance, an agent may manage emails by coordinating with calendars and file systems, or monitor a production database to detect anomalies and generate reports following an operating manual. However, existing language agent benchmarks often focus on narrow domains or simplified tasks that lack the diversity, realism, and long-horizon complexity required to evaluate agents' real-world performance. To address this gap, we introduce the Tool Decathlon (dubbed as Toolathlon), a benchmark for language agents offering diverse Apps and tools, realistic environment setup, and reliable execution-based evaluation. Toolathlon spans 32 software applications and 604 tools, ranging from everyday platforms such as Google Calendar and Notion to professional ones like WooCommerce, Kubernetes, and BigQuery. Most of the tools are based on a high-quality set of Model Context Protocol (MCP) servers that we may have revised or implemented ourselves. Unlike prior works, which primarily ensure functional realism but offer limited environment state diversity, we provide realistic initial environment states from real software, such as Canvas courses with dozens of students or real financial spreadsheets. This benchmark includes 108 manually sourced or crafted tasks in total, requiring interacting with multiple Apps over around 20 turns on average to complete. Each task is strictly verifiable through dedicated evaluation scripts. Comprehensive evaluation of SOTA models highlights their significant shortcomings: the best-performing model, Claude-4.5-Sonnet, achieves only a 38.6% success rate with 20.2 tool calling turns on average, while the top open-weights model DeepSeek-V3.2-Exp reaches 20.1%. We expect Toolathlon to drive the development of more capable language agents for real-world, long-horizon task execution.
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Jun 16, 2025



We introduce MiniMax-M1, the world's first open-weight, large-scale hybrid-attention reasoning model. MiniMax-M1 is powered by a hybrid Mixture-of-Experts (MoE) architecture combined with a lightning attention mechanism. The model is developed based on our previous MiniMax-Text-01 model, which contains a total of 456 billion parameters with 45.9 billion parameters activated per token. The M1 model natively supports a context length of 1 million tokens, 8x the context size of DeepSeek R1. Furthermore, the lightning attention mechanism in MiniMax-M1 enables efficient scaling of test-time compute. These properties make M1 particularly suitable for complex tasks that require processing long inputs and thinking extensively. MiniMax-M1 is trained using large-scale reinforcement learning (RL) on diverse problems including sandbox-based, real-world software engineering environments. In addition to M1's inherent efficiency advantage for RL training, we propose CISPO, a novel RL algorithm to further enhance RL efficiency. CISPO clips importance sampling weights rather than token updates, outperforming other competitive RL variants. Combining hybrid-attention and CISPO enables MiniMax-M1's full RL training on 512 H800 GPUs to complete in only three weeks, with a rental cost of just $534,700. We release two versions of MiniMax-M1 models with 40K and 80K thinking budgets respectively, where the 40K model represents an intermediate phase of the 80K training. Experiments on standard benchmarks show that our models are comparable or superior to strong open-weight models such as the original DeepSeek-R1 and Qwen3-235B, with particular strengths in complex software engineering, tool utilization, and long-context tasks. We publicly release MiniMax-M1 at https://github.com/MiniMax-AI/MiniMax-M1.
SynLogic: Synthesizing Verifiable Reasoning Data at Scale for Learning Logical Reasoning and Beyond
May 26, 2025Recent advances such as OpenAI-o1 and DeepSeek R1 have demonstrated the potential of Reinforcement Learning (RL) to enhance reasoning abilities in Large Language Models (LLMs). While open-source replication efforts have primarily focused on mathematical and coding domains, methods and resources for developing general reasoning capabilities remain underexplored. This gap is partly due to the challenge of collecting diverse and verifiable reasoning data suitable for RL. We hypothesize that logical reasoning is critical for developing general reasoning capabilities, as logic forms a fundamental building block of reasoning. In this work, we present SynLogic, a data synthesis framework and dataset that generates diverse logical reasoning data at scale, encompassing 35 diverse logical reasoning tasks. The SynLogic approach enables controlled synthesis of data with adjustable difficulty and quantity. Importantly, all examples can be verified by simple rules, making them ideally suited for RL with verifiable rewards. In our experiments, we validate the effectiveness of RL training on the SynLogic dataset based on 7B and 32B models. SynLogic leads to state-of-the-art logical reasoning performance among open-source datasets, surpassing DeepSeek-R1-Distill-Qwen-32B by 6 points on BBEH. Furthermore, mixing SynLogic data with mathematical and coding tasks improves the training efficiency of these domains and significantly enhances reasoning generalization. Notably, our mixed training model outperforms DeepSeek-R1-Zero-Qwen-32B across multiple benchmarks. These findings position SynLogic as a valuable resource for advancing the broader reasoning capabilities of LLMs. We open-source both the data synthesis pipeline and the SynLogic dataset at https://github.com/MiniMax-AI/SynLogic.
Learn to Reason Efficiently with Adaptive Length-based Reward Shaping
May 21, 2025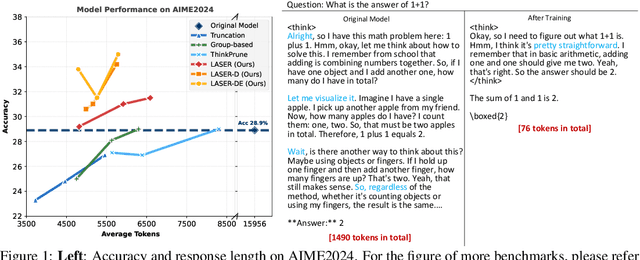
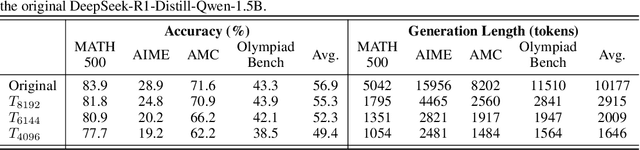
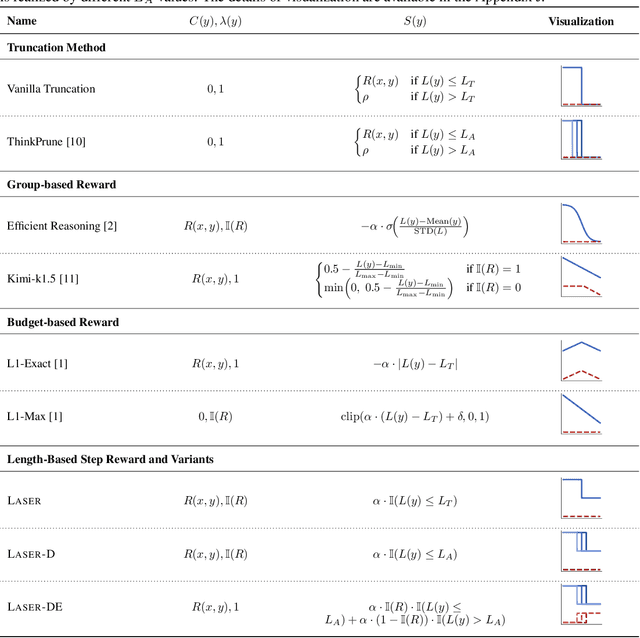
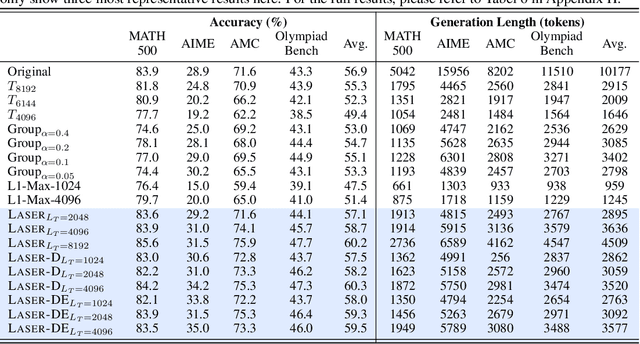
Large Reasoning Models (LRMs) have shown remarkable capabilities in solving complex problems through reinforcement learning (RL), particularly by generating long reasoning traces. However, these extended outputs often exhibit substantial redundancy, which limits the efficiency of LRMs. In this paper, we investigate RL-based approaches to promote reasoning efficiency. Specifically, we first present a unified framework that formulates various efficient reasoning methods through the lens of length-based reward shaping. Building on this perspective, we propose a novel Length-bAsed StEp Reward shaping method (LASER), which employs a step function as the reward, controlled by a target length. LASER surpasses previous methods, achieving a superior Pareto-optimal balance between performance and efficiency. Next, we further extend LASER based on two key intuitions: (1) The reasoning behavior of the model evolves during training, necessitating reward specifications that are also adaptive and dynamic; (2) Rather than uniformly encouraging shorter or longer chains of thought (CoT), we posit that length-based reward shaping should be difficulty-aware i.e., it should penalize lengthy CoTs more for easy queries. This approach is expected to facilitate a combination of fast and slow thinking, leading to a better overall tradeoff. The resulting method is termed LASER-D (Dynamic and Difficulty-aware). Experiments on DeepSeek-R1-Distill-Qwen-1.5B, DeepSeek-R1-Distill-Qwen-7B, and DeepSeek-R1-Distill-Qwen-32B show that our approach significantly enhances both reasoning performance and response length efficiency. For instance, LASER-D and its variant achieve a +6.1 improvement on AIME2024 while reducing token usage by 63%. Further analysis reveals our RL-based compression produces more concise reasoning patterns with less redundant "self-reflections". Resources are at https://github.com/hkust-nlp/Laser.
On the Universal Truthfulness Hyperplane Inside LLMs
Jul 11, 2024



While large language models (LLMs) have demonstrated remarkable abilities across various fields, hallucination remains a significant challenge. Recent studies have explored hallucinations through the lens of internal representations, proposing mechanisms to decipher LLMs' adherence to facts. However, these approaches often fail to generalize to out-of-distribution data, leading to concerns about whether internal representation patterns reflect fundamental factual awareness, or only overfit spurious correlations on the specific datasets. In this work, we investigate whether a universal truthfulness hyperplane that distinguishes the model's factually correct and incorrect outputs exists within the model. To this end, we scale up the number of training datasets and conduct an extensive evaluation -- we train the truthfulness hyperplane on a diverse collection of over 40 datasets and examine its cross-task, cross-domain, and in-domain generalization. Our results indicate that increasing the diversity of the training datasets significantly enhances the performance in all scenarios, while the volume of data samples plays a less critical role. This finding supports the optimistic hypothesis that a universal truthfulness hyperplane may indeed exist within the model, offering promising directions for future research.
In-Context Sharpness as Alerts: An Inner Representation Perspective for Hallucination Mitigation
Mar 12, 2024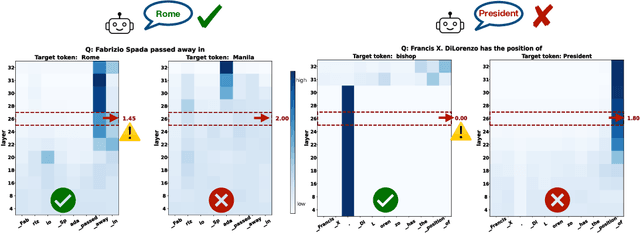
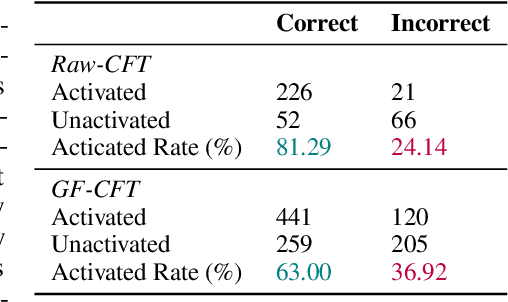
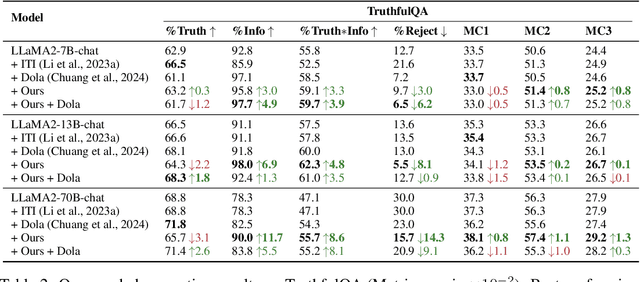
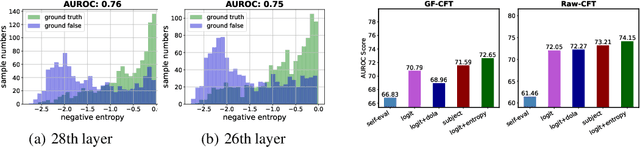
Large language models (LLMs) frequently hallucinate and produce factual errors, yet our understanding of why they make these errors remains limited. In this study, we delve into the underlying mechanisms of LLM hallucinations from the perspective of inner representations, and discover a salient pattern associated with hallucinations: correct generations tend to have sharper context activations in the hidden states of the in-context tokens, compared to the incorrect ones. Leveraging this insight, we propose an entropy-based metric to quantify the ``sharpness'' among the in-context hidden states and incorporate it into the decoding process to formulate a constrained decoding approach. Experiments on various knowledge-seeking and hallucination benchmarks demonstrate our approach's consistent effectiveness, for example, achieving up to an 8.6 point improvement on TruthfulQA. We believe this study can improve our understanding of hallucinations and serve as a practical solution for hallucination mitigation.
Composing Parameter-Efficient Modules with Arithmetic Operations
Jun 26, 2023As an efficient alternative to conventional full finetuning, parameter-efficient finetuning (PEFT) is becoming the prevailing method to adapt pretrained language models. In PEFT, a lightweight module is learned on each dataset while the underlying pretrained language model remains unchanged, resulting in multiple compact modules representing diverse skills when applied to various domains and tasks. In this paper, we propose to compose these parameter-efficient modules through linear arithmetic operations in the weight space, thereby integrating different module capabilities. Specifically, we first define addition and negation operators for the module, and then further compose these two basic operators to perform flexible arithmetic. Our approach requires \emph{no additional training} and enables highly flexible module composition. We apply different arithmetic operations to compose the parameter-efficient modules for (1) distribution generalization, (2) multi-tasking, (3) unlearning, and (4) domain transfer. Additionally, we extend our approach to detoxify Alpaca-LoRA, the latest instruction-tuned large language model based on LLaMA. Empirical results demonstrate that our approach produces new and effective parameter-efficient modules that significantly outperform existing ones across all settings.
C-Eval: A Multi-Level Multi-Discipline Chinese Evaluation Suite for Foundation Models
May 17, 2023



New NLP benchmarks are urgently needed to align with the rapid development of large language models (LLMs). We present C-Eval, the first comprehensive Chinese evaluation suite designed to assess advanced knowledge and reasoning abilities of foundation models in a Chinese context. C-Eval comprises multiple-choice questions across four difficulty levels: middle school, high school, college, and professional. The questions span 52 diverse disciplines, ranging from humanities to science and engineering. C-Eval is accompanied by C-Eval Hard, a subset of very challenging subjects in C-Eval that requires advanced reasoning abilities to solve. We conduct a comprehensive evaluation of the most advanced LLMs on C-Eval, including both English- and Chinese-oriented models. Results indicate that only GPT-4 could achieve an average accuracy of over 60%, suggesting that there is still significant room for improvement for current LLMs. We anticipate C-Eval will help analyze important strengths and shortcomings of foundation models, and foster their development and growth for Chinese users.