 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
The Tool Decathlon: Benchmarking Language Agents for Diverse, Realistic, and Long-Horizon Task Execution
Oct 29, 2025Real-world language agents must handle complex, multi-step workflows across diverse Apps. For instance, an agent may manage emails by coordinating with calendars and file systems, or monitor a production database to detect anomalies and generate reports following an operating manual. However, existing language agent benchmarks often focus on narrow domains or simplified tasks that lack the diversity, realism, and long-horizon complexity required to evaluate agents' real-world performance. To address this gap, we introduce the Tool Decathlon (dubbed as Toolathlon), a benchmark for language agents offering diverse Apps and tools, realistic environment setup, and reliable execution-based evaluation. Toolathlon spans 32 software applications and 604 tools, ranging from everyday platforms such as Google Calendar and Notion to professional ones like WooCommerce, Kubernetes, and BigQuery. Most of the tools are based on a high-quality set of Model Context Protocol (MCP) servers that we may have revised or implemented ourselves. Unlike prior works, which primarily ensure functional realism but offer limited environment state diversity, we provide realistic initial environment states from real software, such as Canvas courses with dozens of students or real financial spreadsheets. This benchmark includes 108 manually sourced or crafted tasks in total, requiring interacting with multiple Apps over around 20 turns on average to complete. Each task is strictly verifiable through dedicated evaluation scripts. Comprehensive evaluation of SOTA models highlights their significant shortcomings: the best-performing model, Claude-4.5-Sonnet, achieves only a 38.6% success rate with 20.2 tool calling turns on average, while the top open-weights model DeepSeek-V3.2-Exp reaches 20.1%. We expect Toolathlon to drive the development of more capable language agents for real-world, long-horizon task execution.
SwinSRGAN: Swin Transformer-based Generative Adversarial Network for High-Fidelity Speech Super-Resolution
Sep 04, 2025Speech super-resolution (SR) reconstructs high-frequency content from low-resolution speech signals. Existing systems often suffer from representation mismatch in two-stage mel-vocoder pipelines and from over-smoothing of hallucinated high-band content by CNN-only generators. Diffusion and flow models are computationally expensive, and their robustness across domains and sampling rates remains limited. We propose SwinSRGAN, an end-to-end framework operating on Modified Discrete Cosine Transform (MDCT) magnitudes. It is a Swin Transformer-based U-Net that captures long-range spectro-temporal dependencies with a hybrid adversarial scheme combines time-domain MPD/MSD discriminators with a multi-band MDCT discriminator specialized for the high-frequency band. We employs a sparse-aware regularizer on arcsinh-compressed MDCT to better preserve transient components. The system upsamples inputs at various sampling rates to 48 kHz in a single pass and operates in real time. On standard benchmarks, SwinSRGAN reduces objective error and improves ABX preference scores. In zero-shot tests on HiFi-TTS without fine-tuning, it outperforms NVSR and mdctGAN, demonstrating strong generalization across datasets
MEDMKG: Benchmarking Medical Knowledge Exploitation with Multimodal Knowledge Graph
May 22, 2025Medical deep learning models depend heavily on domain-specific knowledge to perform well on knowledge-intensive clinical tasks. Prior work has primarily leveraged unimodal knowledge graphs, such as the Unified Medical Language System (UMLS), to enhance model performance. However, integrating multimodal medical knowledge graphs remains largely underexplored, mainly due to the lack of resources linking imaging data with clinical concepts. To address this gap, we propose MEDMKG, a Medical Multimodal Knowledge Graph that unifies visual and textual medical information through a multi-stage construction pipeline. MEDMKG fuses the rich multimodal data from MIMIC-CXR with the structured clinical knowledge from UMLS, utilizing both rule-based tools and large language models for accurate concept extraction and relationship modeling. To ensure graph quality and compactness, we introduce Neighbor-aware Filtering (NaF), a novel filtering algorithm tailored for multimodal knowledge graphs. We evaluate MEDMKG across three tasks under two experimental settings, benchmarking twenty-four baseline methods and four state-of-the-art vision-language backbones on six datasets. Results show that MEDMKG not only improves performance in downstream medical tasks but also offers a strong foundation for developing adaptive and robust strategies for multimodal knowledge integration in medical artificial intelligence.
EventVAD: Training-Free Event-Aware Video Anomaly Detection
Apr 17, 2025Video Anomaly Detection~(VAD) focuses on identifying anomalies within videos. Supervised methods require an amount of in-domain training data and often struggle to generalize to unseen anomalies. In contrast, training-free methods leverage the intrinsic world knowledge of large language models (LLMs) to detect anomalies but face challenges in localizing fine-grained visual transitions and diverse events. Therefore, we propose EventVAD, an event-aware video anomaly detection framework that combines tailored dynamic graph architectures and multimodal LLMs through temporal-event reasoning. Specifically, EventVAD first employs dynamic spatiotemporal graph modeling with time-decay constraints to capture event-aware video features. Then, it performs adaptive noise filtering and uses signal ratio thresholding to detect event boundaries via unsupervised statistical features. The statistical boundary detection module reduces the complexity of processing long videos for MLLMs and improves their temporal reasoning through event consistency. Finally, it utilizes a hierarchical prompting strategy to guide MLLMs in performing reasoning before determining final decisions. We conducted extensive experiments on the UCF-Crime and XD-Violence datasets. The results demonstrate that EventVAD with a 7B MLLM achieves state-of-the-art (SOTA) in training-free settings, outperforming strong baselines that use 7B or larger MLLMs.
AdaMMS: Model Merging for Heterogeneous Multimodal Large Language Models with Unsupervised Coefficient Optimization
Mar 31, 2025Recently, model merging methods have demonstrated powerful strengths in combining abilities on various tasks from multiple Large Language Models (LLMs). While previous model merging methods mainly focus on merging homogeneous models with identical architecture, they meet challenges when dealing with Multimodal Large Language Models (MLLMs) with inherent heterogeneous property, including differences in model architecture and the asymmetry in the parameter space. In this work, we propose AdaMMS, a novel model merging method tailored for heterogeneous MLLMs. Our method tackles the challenges in three steps: mapping, merging and searching. Specifically, we first design mapping function between models to apply model merging on MLLMs with different architecture. Then we apply linear interpolation on model weights to actively adapt the asymmetry in the heterogeneous MLLMs. Finally in the hyper-parameter searching step, we propose an unsupervised hyper-parameter selection method for model merging. As the first model merging method capable of merging heterogeneous MLLMs without labeled data, extensive experiments on various model combinations demonstrated that AdaMMS outperforms previous model merging methods on various vision-language benchmarks.
Beyond Single Frames: Can LMMs Comprehend Temporal and Contextual Narratives in Image Sequences?
Feb 19, 2025Large Multimodal Models (LMMs) have achieved remarkable success across various visual-language tasks. However, existing benchmarks predominantly focus on single-image understanding, leaving the analysis of image sequences largely unexplored. To address this limitation, we introduce StripCipher, a comprehensive benchmark designed to evaluate capabilities of LMMs to comprehend and reason over sequential images. StripCipher comprises a human-annotated dataset and three challenging subtasks: visual narrative comprehension, contextual frame prediction, and temporal narrative reordering. Our evaluation of $16$ state-of-the-art LMMs, including GPT-4o and Qwen2.5VL, reveals a significant performance gap compared to human capabilities, particularly in tasks that require reordering shuffled sequential images. For instance, GPT-4o achieves only 23.93% accuracy in the reordering subtask, which is 56.07% lower than human performance. Further quantitative analysis discuss several factors, such as input format of images, affecting the performance of LLMs in sequential understanding, underscoring the fundamental challenges that remain in the development of LMMs.
SG-FSM: A Self-Guiding Zero-Shot Prompting Paradigm for Multi-Hop Question Answering Based on Finite State Machine
Oct 22, 2024



Large Language Models with chain-of-thought prompting, such as OpenAI-o1, have shown impressive capabilities in natural language inference tasks. However, Multi-hop Question Answering (MHQA) remains challenging for many existing models due to issues like hallucination, error propagation, and limited context length. To address these challenges and enhance LLMs' performance on MHQA, we propose the Self-Guiding prompting Finite State Machine (SG-FSM), designed to strengthen multi-hop reasoning abilities. Unlike traditional chain-of-thought methods, SG-FSM tackles MHQA by iteratively breaking down complex questions into sub-questions, correcting itself to improve accuracy. It processes one sub-question at a time, dynamically deciding the next step based on the current context and results, functioning much like an automaton. Experiments across various benchmarks demonstrate the effectiveness of our approach, outperforming strong baselines on challenging datasets such as Musique. SG-FSM reduces hallucination, enabling recovery of the correct final answer despite intermediate errors. It also improves adherence to specified output formats, simplifying evaluation significantly.
FEDKIM: Adaptive Federated Knowledge Injection into Medical Foundation Models
Aug 17, 2024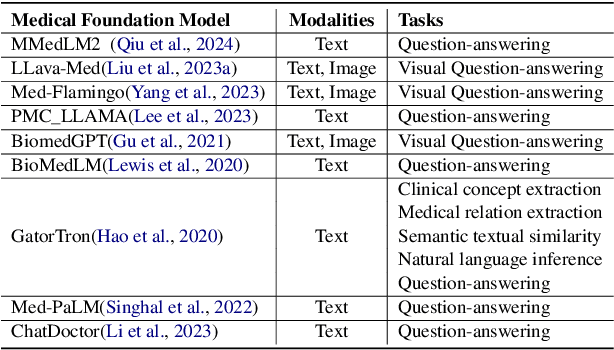
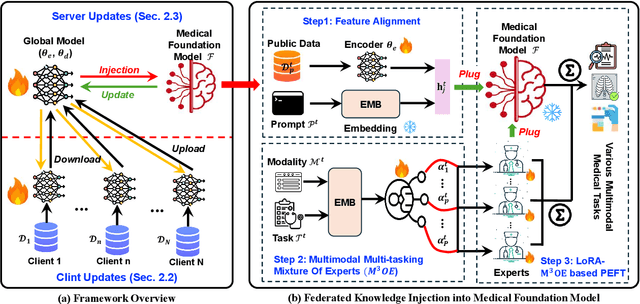
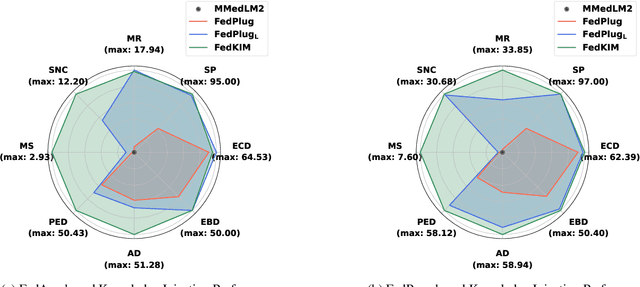
Foundation models have demonstrated remarkable capabilities in handling diverse modalities and tasks, outperforming conventional artificial intelligence (AI) approaches that are highly task-specific and modality-reliant. In the medical domain, however, the development of comprehensive foundation models is constrained by limited access to diverse modalities and stringent privacy regulations. To address these constraints, this study introduces a novel knowledge injection approach, FedKIM, designed to scale the medical foundation model within a federated learning framework. FedKIM leverages lightweight local models to extract healthcare knowledge from private data and integrates this knowledge into a centralized foundation model using a designed adaptive Multitask Multimodal Mixture Of Experts (M3OE) module. This method not only preserves privacy but also enhances the model's ability to handle complex medical tasks involving multiple modalities. Our extensive experiments across twelve tasks in seven modalities demonstrate the effectiveness of FedKIM in various settings, highlighting its potential to scale medical foundation models without direct access to sensitive data.
FEDMEKI: A Benchmark for Scaling Medical Foundation Models via Federated Knowledge Injection
Aug 17, 2024
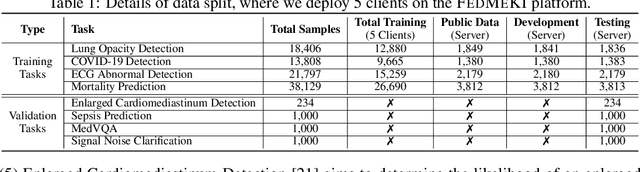
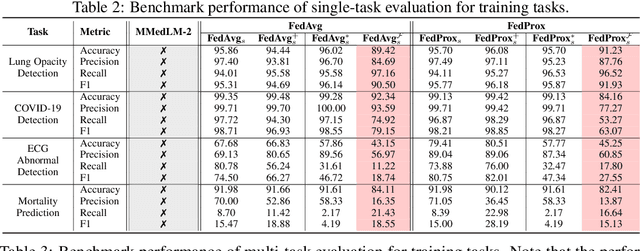

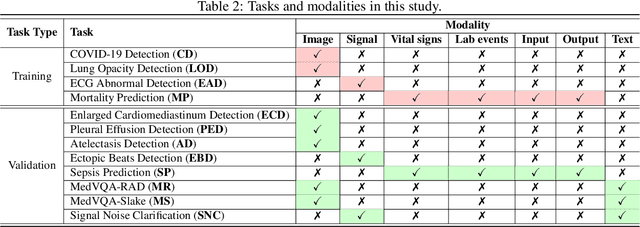
This study introduces the Federated Medical Knowledge Injection (FEDMEKI) platform, a new benchmark designed to address the unique challenges of integrating medical knowledge into foundation models under privacy constraints. By leveraging a cross-silo federated learning approach, FEDMEKI circumvents the issues associated with centralized data collection, which is often prohibited under health regulations like the Health Insurance Portability and Accountability Act (HIPAA) in the USA. The platform is meticulously designed to handle multi-site, multi-modal, and multi-task medical data, which includes 7 medical modalities, including images, signals, texts, laboratory test results, vital signs, input variables, and output variables. The curated dataset to validate FEDMEKI covers 8 medical tasks, including 6 classification tasks (lung opacity detection, COVID-19 detection, electrocardiogram (ECG) abnormal detection, mortality prediction, sepsis prediction, and enlarged cardiomediastinum detection) and 2 generation tasks (medical visual question answering (MedVQA) and ECG noise clarification). This comprehensive dataset is partitioned across several clients to facilitate the decentralized training process under 16 benchmark approaches. FEDMEKI not only preserves data privacy but also enhances the capability of medical foundation models by allowing them to learn from a broader spectrum of medical knowledge without direct data exposure, thereby setting a new benchmark in the application of foundation models within the healthcare sector.