 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFEDKIM: Adaptive Federated Knowledge Injection into Medical Foundation Models
Aug 17, 2024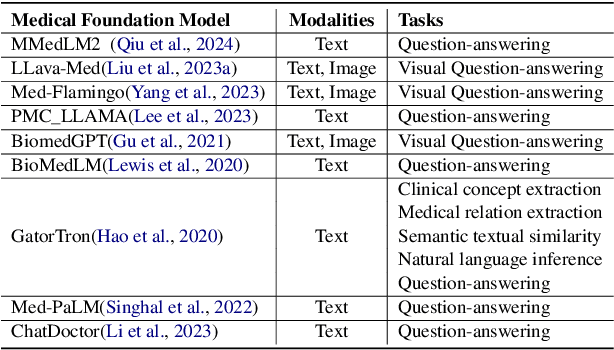
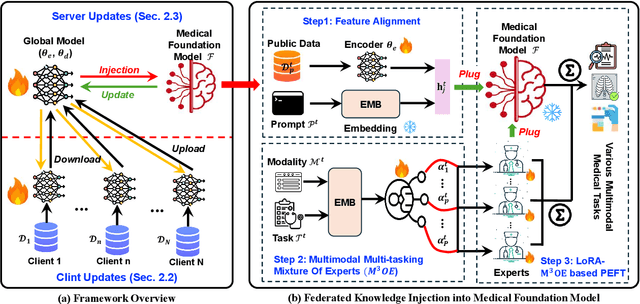
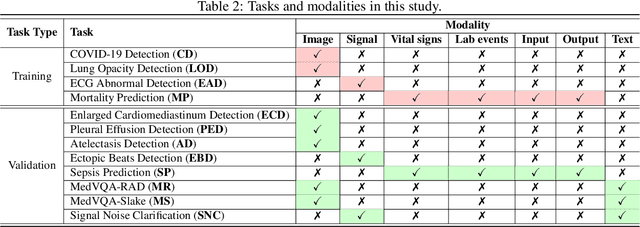
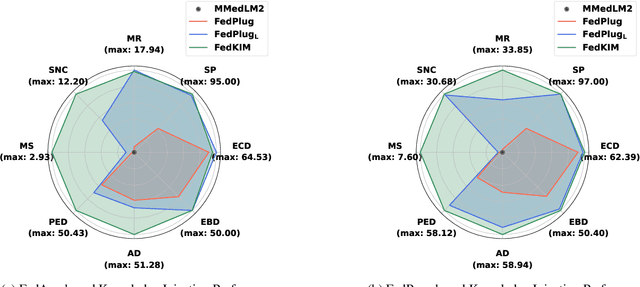
Foundation models have demonstrated remarkable capabilities in handling diverse modalities and tasks, outperforming conventional artificial intelligence (AI) approaches that are highly task-specific and modality-reliant. In the medical domain, however, the development of comprehensive foundation models is constrained by limited access to diverse modalities and stringent privacy regulations. To address these constraints, this study introduces a novel knowledge injection approach, FedKIM, designed to scale the medical foundation model within a federated learning framework. FedKIM leverages lightweight local models to extract healthcare knowledge from private data and integrates this knowledge into a centralized foundation model using a designed adaptive Multitask Multimodal Mixture Of Experts (M3OE) module. This method not only preserves privacy but also enhances the model's ability to handle complex medical tasks involving multiple modalities. Our extensive experiments across twelve tasks in seven modalities demonstrate the effectiveness of FedKIM in various settings, highlighting its potential to scale medical foundation models without direct access to sensitive data.
MedDiffusion: Boosting Health Risk Prediction via Diffusion-based Data Augmentation
Oct 05, 2023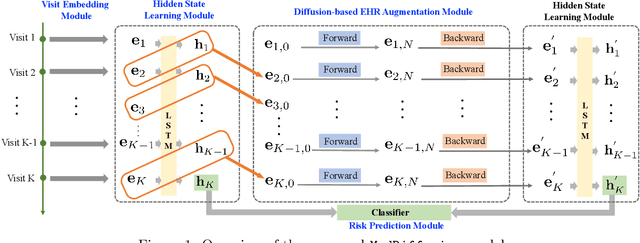
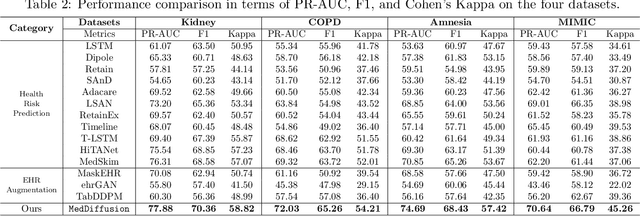
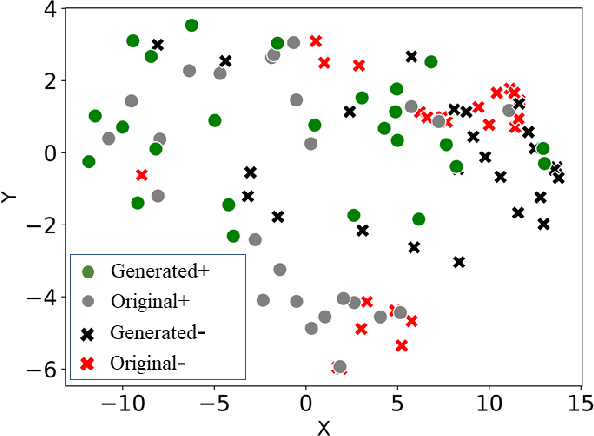
Health risk prediction is one of the fundamental tasks under predictive modeling in the medical domain, which aims to forecast the potential health risks that patients may face in the future using their historical Electronic Health Records (EHR). Researchers have developed several risk prediction models to handle the unique challenges of EHR data, such as its sequential nature, high dimensionality, and inherent noise. These models have yielded impressive results. Nonetheless, a key issue undermining their effectiveness is data insufficiency. A variety of data generation and augmentation methods have been introduced to mitigate this issue by expanding the size of the training data set through the learning of underlying data distributions. However, the performance of these methods is often limited due to their task-unrelated design. To address these shortcomings, this paper introduces a novel, end-to-end diffusion-based risk prediction model, named MedDiffusion. It enhances risk prediction performance by creating synthetic patient data during training to enlarge sample space. Furthermore, MedDiffusion discerns hidden relationships between patient visits using a step-wise attention mechanism, enabling the model to automatically retain the most vital information for generating high-quality data. Experimental evaluation on four real-world medical datasets demonstrates that MedDiffusion outperforms 14 cutting-edge baselines in terms of PR-AUC, F1, and Cohen's Kappa. We also conduct ablation studies and benchmark our model against GAN-based alternatives to further validate the rationality and adaptability of our model design. Additionally, we analyze generated data to offer fresh insights into the model's interpretability.
Knowledge-Enhanced Semi-Supervised Federated Learning for Aggregating Heterogeneous Lightweight Clients in IoT
Mar 05, 2023



Federated learning (FL) enables multiple clients to train models collaboratively without sharing local data, which has achieved promising results in different areas, including the Internet of Things (IoT). However, end IoT devices do not have abilities to automatically annotate their collected data, which leads to the label shortage issue at the client side. To collaboratively train an FL model, we can only use a small number of labeled data stored on the server. This is a new yet practical scenario in federated learning, i.e., labels-at-server semi-supervised federated learning (SemiFL). Although several SemiFL approaches have been proposed recently, none of them can focus on the personalization issue in their model design. IoT environments make SemiFL more challenging, as we need to take device computational constraints and communication cost into consideration simultaneously. To tackle these new challenges together, we propose a novel SemiFL framework named pFedKnow. pFedKnow generates lightweight personalized client models via neural network pruning techniques to reduce communication cost. Moreover, it incorporates pretrained large models as prior knowledge to guide the aggregation of personalized client models and further enhance the framework performance. Experiment results on both image and text datasets show that the proposed pFedKnow outperforms state-of-the-art baselines as well as reducing considerable communication cost. The source code of the proposed pFedKnow is available at https://github.com/JackqqWang/pfedknow/tree/master.
FedTriNet: A Pseudo Labeling Method with Three Players for Federated Semi-supervised Learning
Sep 12, 2021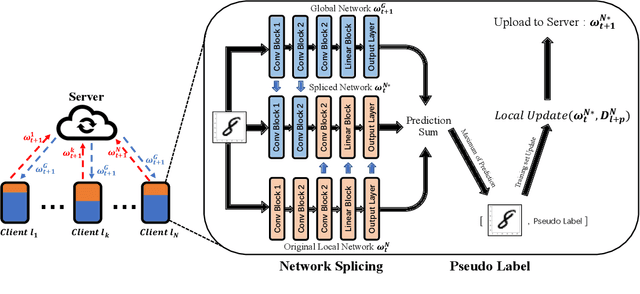
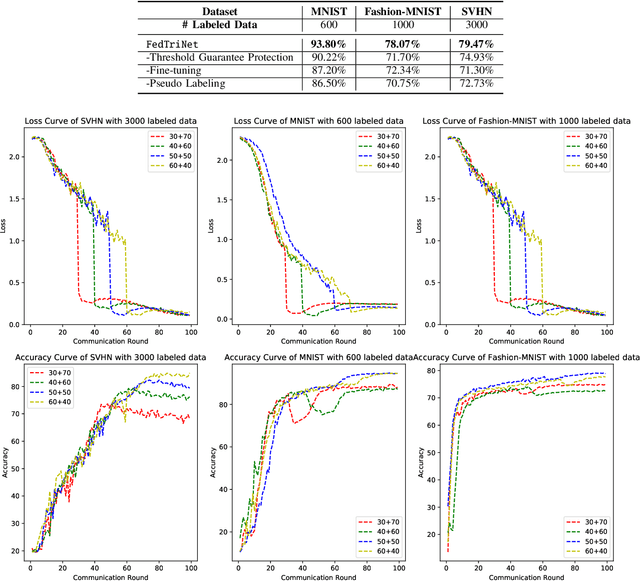
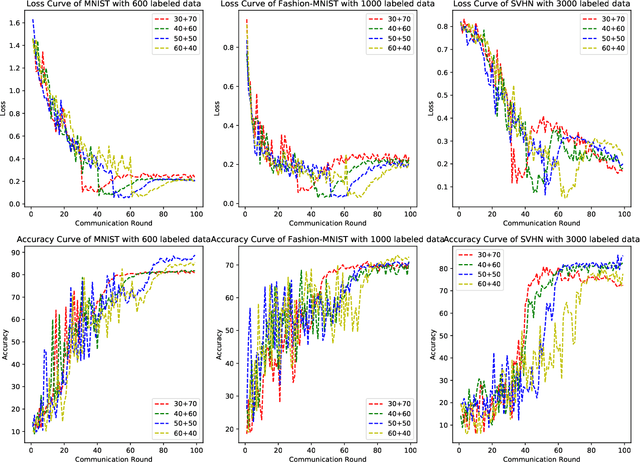

Federated Learning has shown great potentials for the distributed data utilization and privacy protection. Most existing federated learning approaches focus on the supervised setting, which means all the data stored in each client has labels. However, in real-world applications, the client data are impossible to be fully labeled. Thus, how to exploit the unlabeled data should be a new challenge for federated learning. Although a few studies are attempting to overcome this challenge, they may suffer from information leakage or misleading information usage problems. To tackle these issues, in this paper, we propose a novel federated semi-supervised learning method named FedTriNet, which consists of two learning phases. In the first phase, we pre-train FedTriNet using labeled data with FedAvg. In the second phase, we aim to make most of the unlabeled data to help model learning. In particular, we propose to use three networks and a dynamic quality control mechanism to generate high-quality pseudo labels for unlabeled data, which are added to the training set. Finally, FedTriNet uses the new training set to retrain the model. Experimental results on three publicly available datasets show that the proposed FedTriNet outperforms state-of-the-art baselines under both IID and Non-IID settings.
FedCon: A Contrastive Framework for Federated Semi-Supervised Learning
Sep 09, 2021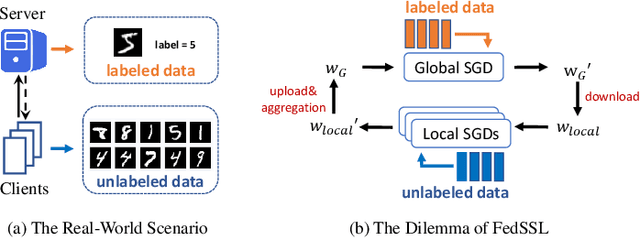
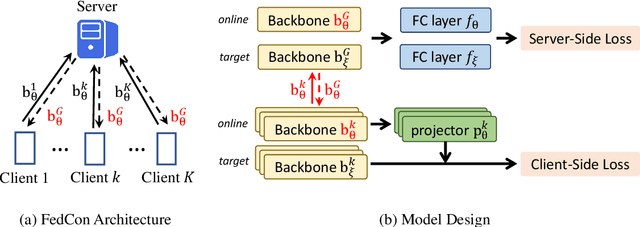
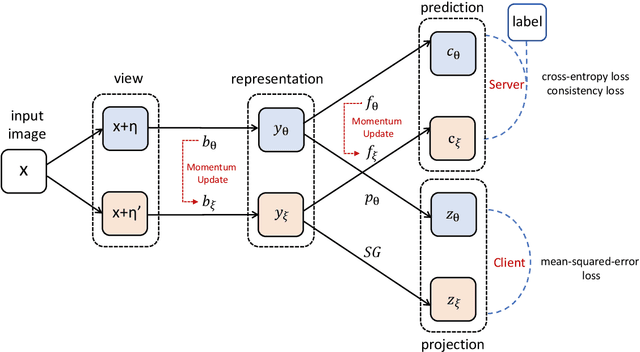
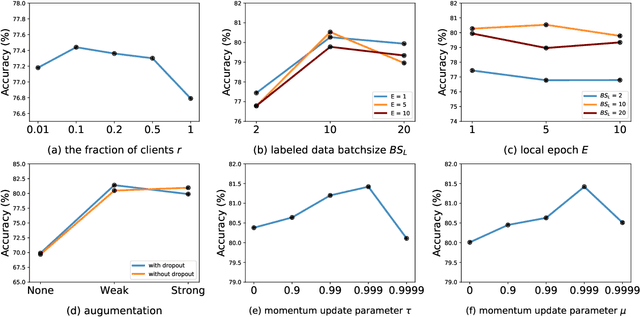
Federated Semi-Supervised Learning (FedSSL) has gained rising attention from both academic and industrial researchers, due to its unique characteristics of co-training machine learning models with isolated yet unlabeled data. Most existing FedSSL methods focus on the classical scenario, i.e, the labeled and unlabeled data are stored at the client side. However, in real world applications, client users may not provide labels without any incentive. Thus, the scenario of labels at the server side is more practical. Since unlabeled data and labeled data are decoupled, most existing FedSSL approaches may fail to deal with such a scenario. To overcome this problem, in this paper, we propose FedCon, which introduces a new learning paradigm, i.e., contractive learning, to FedSSL. Experimental results on three datasets show that FedCon achieves the best performance with the contractive framework compared with state-of-the-art baselines under both IID and Non-IID settings. Besides, ablation studies demonstrate the characteristics of the proposed FedCon framework.
FedSemi: An Adaptive Federated Semi-Supervised Learning Framework
Dec 06, 2020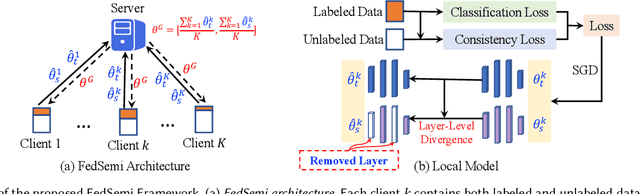
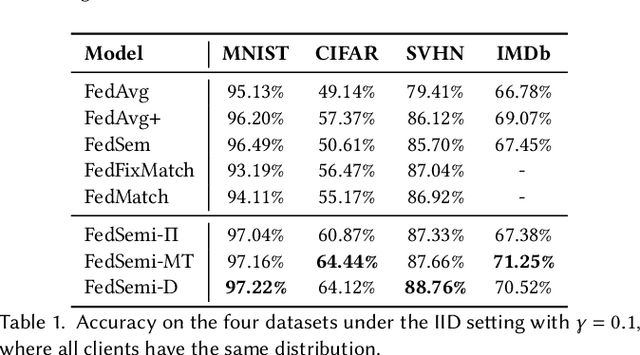
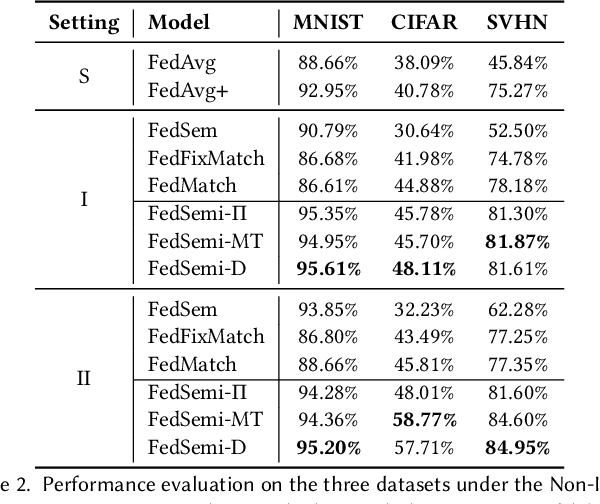
Federated learning (FL) has emerged as an effective technique to co-training machine learning models without actually sharing data and leaking privacy. However, most existing FL methods focus on the supervised setting and ignore the utilization of unlabeled data. Although there are a few existing studies trying to incorporate unlabeled data into FL, they all fail to maintain performance guarantees or generalization ability in various settings. In this paper, we tackle the federated semi-supervised learning problem from the insight of data regularization and analyze the new-raised difficulties. We propose FedSemi, a novel, adaptive, and general framework, which firstly introduces the consistency regularization into FL using a teacher-student model. We further propose a new metric to measure the divergence of local model layers. Based on the divergence, FedSemi can automatically select layer-level parameters to be uploaded to the server in an adaptive manner. Through extensive experimental validation of our method in four datasets, we show that our method achieves performance gain under the IID setting and three Non-IID settings compared to state-of-the-art baselines.
Towards Differentially Private Truth Discovery for Crowd Sensing Systems
Oct 10, 2018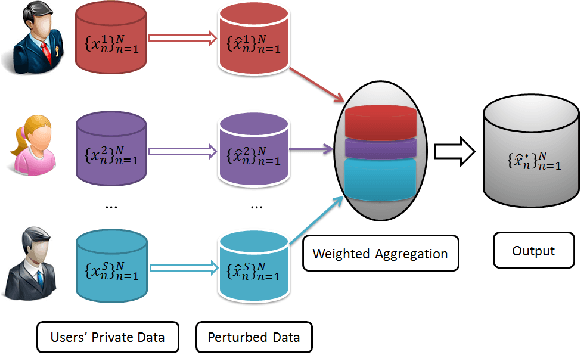
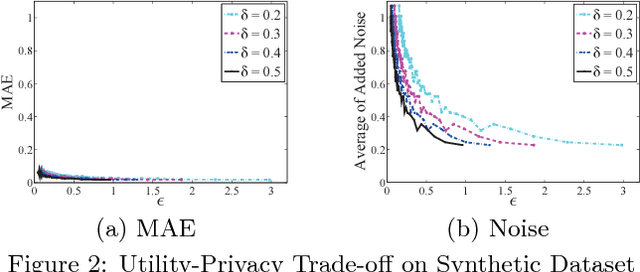
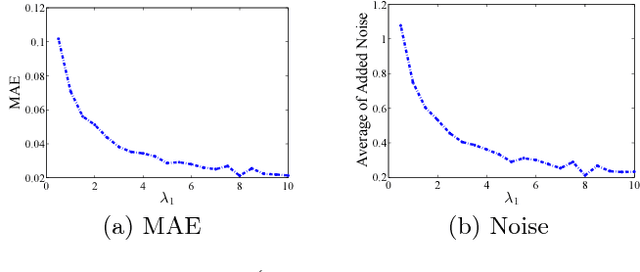
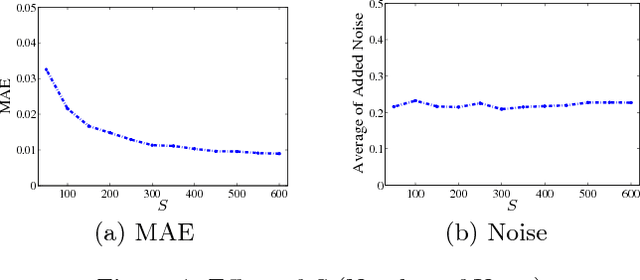
Nowadays, crowd sensing becomes increasingly more popular due to the ubiquitous usage of mobile devices. However, the quality of such human-generated sensory data varies significantly among different users. To better utilize sensory data, the problem of truth discovery, whose goal is to estimate user quality and infer reliable aggregated results through quality-aware data aggregation, has emerged as a hot topic. Although the existing truth discovery approaches can provide reliable aggregated results, they fail to protect the private information of individual users. Moreover, crowd sensing systems typically involve a large number of participants, making encryption or secure multi-party computation based solutions difficult to deploy. To address these challenges, in this paper, we propose an efficient privacy-preserving truth discovery mechanism with theoretical guarantees of both utility and privacy. The key idea of the proposed mechanism is to perturb data from each user independently and then conduct weighted aggregation among users' perturbed data. The proposed approach is able to assign user weights based on information quality, and thus the aggregated results will not deviate much from the true results even when large noise is added. We adapt local differential privacy definition to this privacy-preserving task and demonstrate the proposed mechanism can satisfy local differential privacy while preserving high aggregation accuracy. We formally quantify utility and privacy trade-off and further verify the claim by experiments on both synthetic data and a real-world crowd sensing system.
Developing Synthesis Flows Without Human Knowledge
Apr 23, 2018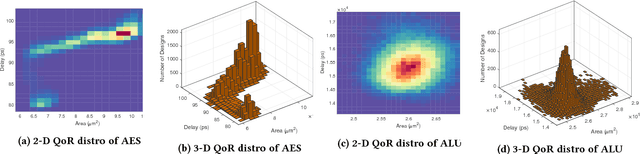

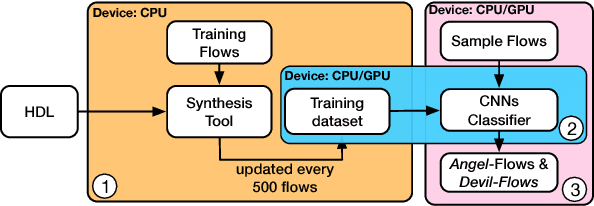
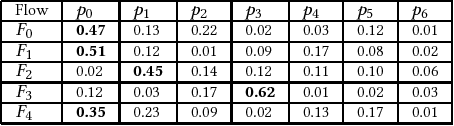
Design flows are the explicit combinations of design transformations, primarily involved in synthesis, placement and routing processes, to accomplish the design of Integrated Circuits (ICs) and System-on-Chip (SoC). Mostly, the flows are developed based on the knowledge of the experts. However, due to the large search space of design flows and the increasing design complexity, developing Intellectual Property (IP)-specific synthesis flows providing high Quality of Result (QoR) is extremely challenging. This work presents a fully autonomous framework that artificially produces design-specific synthesis flows without human guidance and baseline flows, using Convolutional Neural Network (CNN). The demonstrations are made by successfully designing logic synthesis flows of three large scaled designs.