 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge-Enhanced Semi-Supervised Federated Learning for Aggregating Heterogeneous Lightweight Clients in IoT
Mar 05, 2023



Federated learning (FL) enables multiple clients to train models collaboratively without sharing local data, which has achieved promising results in different areas, including the Internet of Things (IoT). However, end IoT devices do not have abilities to automatically annotate their collected data, which leads to the label shortage issue at the client side. To collaboratively train an FL model, we can only use a small number of labeled data stored on the server. This is a new yet practical scenario in federated learning, i.e., labels-at-server semi-supervised federated learning (SemiFL). Although several SemiFL approaches have been proposed recently, none of them can focus on the personalization issue in their model design. IoT environments make SemiFL more challenging, as we need to take device computational constraints and communication cost into consideration simultaneously. To tackle these new challenges together, we propose a novel SemiFL framework named pFedKnow. pFedKnow generates lightweight personalized client models via neural network pruning techniques to reduce communication cost. Moreover, it incorporates pretrained large models as prior knowledge to guide the aggregation of personalized client models and further enhance the framework performance. Experiment results on both image and text datasets show that the proposed pFedKnow outperforms state-of-the-art baselines as well as reducing considerable communication cost. The source code of the proposed pFedKnow is available at https://github.com/JackqqWang/pfedknow/tree/master.
FedTriNet: A Pseudo Labeling Method with Three Players for Federated Semi-supervised Learning
Sep 12, 2021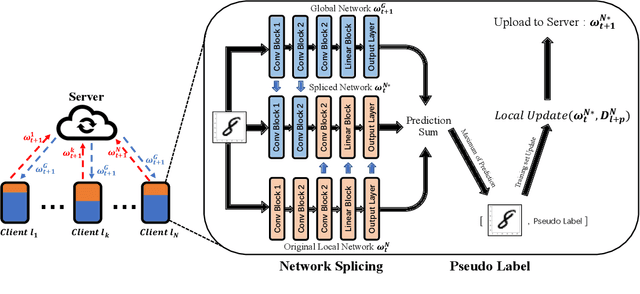
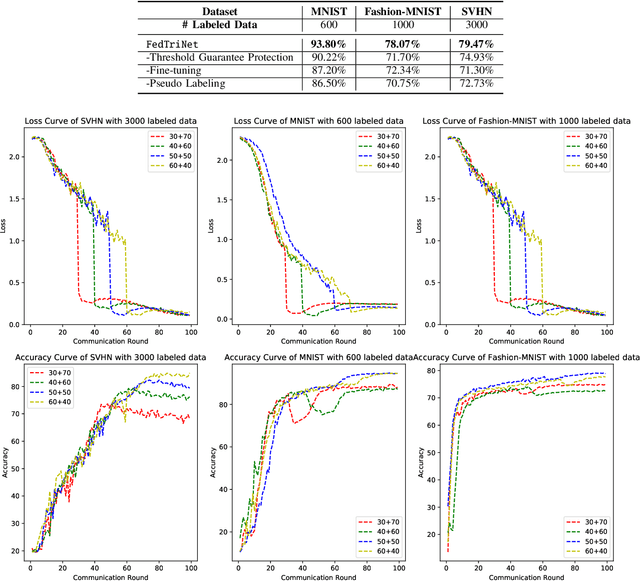

Federated Learning has shown great potentials for the distributed data utilization and privacy protection. Most existing federated learning approaches focus on the supervised setting, which means all the data stored in each client has labels. However, in real-world applications, the client data are impossible to be fully labeled. Thus, how to exploit the unlabeled data should be a new challenge for federated learning. Although a few studies are attempting to overcome this challenge, they may suffer from information leakage or misleading information usage problems. To tackle these issues, in this paper, we propose a novel federated semi-supervised learning method named FedTriNet, which consists of two learning phases. In the first phase, we pre-train FedTriNet using labeled data with FedAvg. In the second phase, we aim to make most of the unlabeled data to help model learning. In particular, we propose to use three networks and a dynamic quality control mechanism to generate high-quality pseudo labels for unlabeled data, which are added to the training set. Finally, FedTriNet uses the new training set to retrain the model. Experimental results on three publicly available datasets show that the proposed FedTriNet outperforms state-of-the-art baselines under both IID and Non-IID settings.
FedCon: A Contrastive Framework for Federated Semi-Supervised Learning
Sep 09, 2021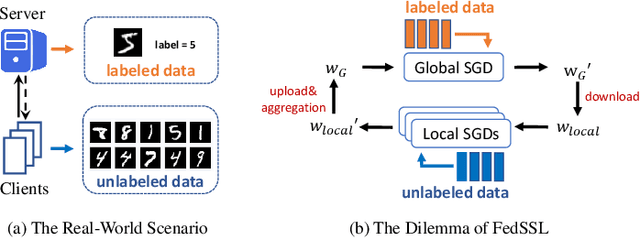
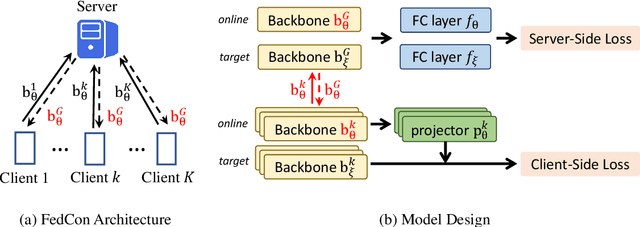
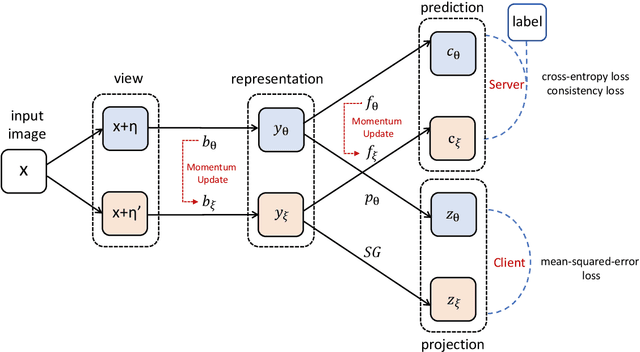
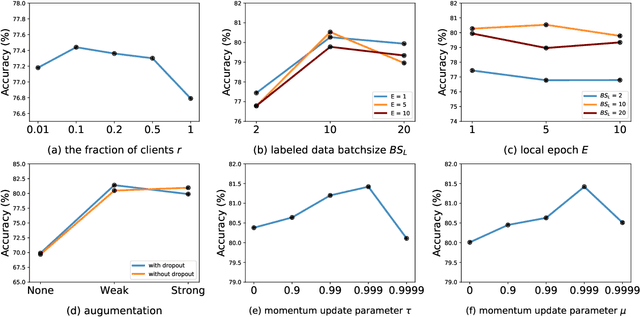
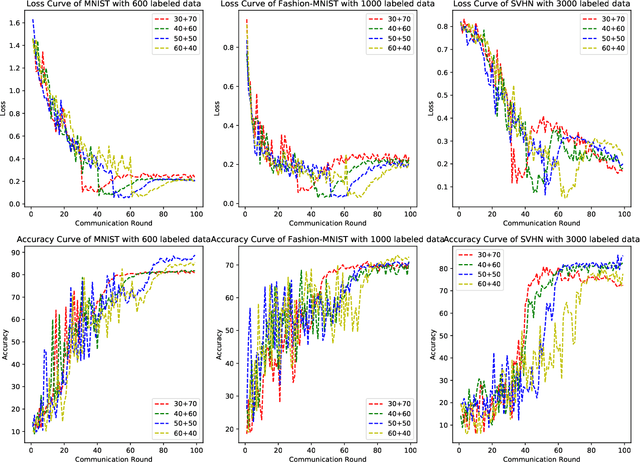
Federated Semi-Supervised Learning (FedSSL) has gained rising attention from both academic and industrial researchers, due to its unique characteristics of co-training machine learning models with isolated yet unlabeled data. Most existing FedSSL methods focus on the classical scenario, i.e, the labeled and unlabeled data are stored at the client side. However, in real world applications, client users may not provide labels without any incentive. Thus, the scenario of labels at the server side is more practical. Since unlabeled data and labeled data are decoupled, most existing FedSSL approaches may fail to deal with such a scenario. To overcome this problem, in this paper, we propose FedCon, which introduces a new learning paradigm, i.e., contractive learning, to FedSSL. Experimental results on three datasets show that FedCon achieves the best performance with the contractive framework compared with state-of-the-art baselines under both IID and Non-IID settings. Besides, ablation studies demonstrate the characteristics of the proposed FedCon framework.
FedSemi: An Adaptive Federated Semi-Supervised Learning Framework
Dec 06, 2020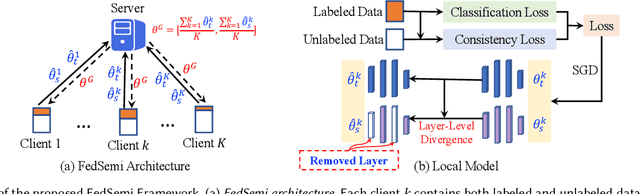
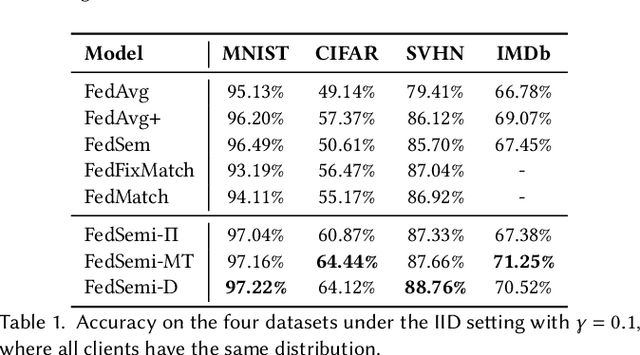
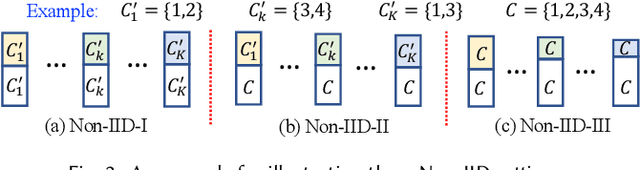
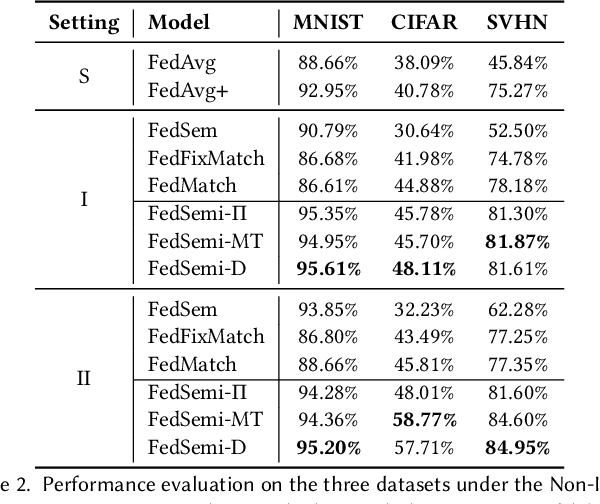
Federated learning (FL) has emerged as an effective technique to co-training machine learning models without actually sharing data and leaking privacy. However, most existing FL methods focus on the supervised setting and ignore the utilization of unlabeled data. Although there are a few existing studies trying to incorporate unlabeled data into FL, they all fail to maintain performance guarantees or generalization ability in various settings. In this paper, we tackle the federated semi-supervised learning problem from the insight of data regularization and analyze the new-raised difficulties. We propose FedSemi, a novel, adaptive, and general framework, which firstly introduces the consistency regularization into FL using a teacher-student model. We further propose a new metric to measure the divergence of local model layers. Based on the divergence, FedSemi can automatically select layer-level parameters to be uploaded to the server in an adaptive manner. Through extensive experimental validation of our method in four datasets, we show that our method achieves performance gain under the IID setting and three Non-IID settings compared to state-of-the-art baselines.