 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeER-MIA: Black-Box Adversarial Memory Injection Attacks on Long-Term Memory-Augmented Large Language Models
Feb 17, 2026Large language models (LLMs) are increasingly augmented with long-term memory systems to overcome finite context windows and enable persistent reasoning across interactions. However, recent research finds that LLMs become more vulnerable because memory provides extra attack surfaces. In this paper, we present the first systematic study of black-box adversarial memory injection attacks that target the similarity-based retrieval mechanism in long-term memory-augmented LLMs. We introduce ER-MIA, a unified framework that exposes this vulnerability and formalizes two realistic attack settings: content-based attacks and question-targeted attacks. In these settings, ER-MIA includes an arsenal of composable attack primitives and ensemble attacks that achieve high success rates under minimal attacker assumptions. Extensive experiments across multiple LLMs and long-term memory systems demonstrate that similarity-based retrieval constitutes a fundamental and system-level vulnerability, revealing security risks that persist across memory designs and application scenarios.
Understanding Real-World Traffic Safety through RoadSafe365 Benchmark
Feb 06, 2026Although recent traffic benchmarks have advanced multimodal data analysis, they generally lack systematic evaluation aligned with official safety standards. To fill this gap, we introduce RoadSafe365, a large-scale vision-language benchmark that supports fine-grained analysis of traffic safety from extensive and diverse real-world video data collections. Unlike prior works that focus primarily on coarse accident identification, RoadSafe365 is independently curated and systematically organized using a hierarchical taxonomy that refines and extends foundational definitions of crash, incident, and violation to bridge official traffic safety standards with data-driven traffic understanding systems. RoadSafe365 provides rich attribute annotations across diverse traffic event types, environmental contexts, and interaction scenarios, yielding 36,196 annotated clips from both dashcam and surveillance cameras. Each clip is paired with multiple-choice question-answer sets, comprising 864K candidate options, 8.4K unique answers, and 36K detailed scene descriptions collectively designed for vision-language understanding and reasoning. We establish strong baselines and observe consistent gains when fine-tuning on RoadSafe365. Cross-domain experiments on both real and synthetic datasets further validate its effectiveness. Designed for large-scale training and standardized evaluation, RoadSafe365 provides a comprehensive benchmark to advance reproducible research in real-world traffic safety analysis.
The Value of Variance: Mitigating Debate Collapse in Multi-Agent Systems via Uncertainty-Driven Policy Optimization
Feb 06, 2026Multi-agent debate (MAD) systems improve LLM reasoning through iterative deliberation, but remain vulnerable to debate collapse, a failure type where final agent decisions are compromised on erroneous reasoning. Existing methods lack principled mechanisms to detect or prevent such failures. To address this gap, we first propose a hierarchical metric that quantifies behavioral uncertainty at three levels: intra-agent (individual reasoning uncertainty), inter-agent (interactive uncertainty), and system-level (output uncertainty). Empirical analysis across several benchmarks reveals that our proposed uncertainty quantification reliably indicates system failures, which demonstrates the validity of using them as diagnostic metrics to indicate the system failure. Subsequently, we propose a mitigation strategy by formulating an uncertainty-driven policy optimization to penalize self-contradiction, peer conflict, and low-confidence outputs in a dynamic debating environment. Experiments demonstrate that our proposed uncertainty-driven mitigation reliably calibrates the multi-agent system by consistently improving decision accuracy while reducing system disagreement.
SRVAU-R1: Enhancing Video Anomaly Understanding via Reflection-Aware Learning
Feb 01, 2026Multi-modal large language models (MLLMs) have demonstrated significant progress in reasoning capabilities and shown promising effectiveness in video anomaly understanding (VAU) tasks. However, existing MLLM-based approaches remain largely focused on surface-level descriptions of anomalies, lacking deep reasoning over abnormal behaviors like explicit self-reflection and self-correction. To address that, we propose Self-Reflection-Enhanced Reasoning for Video Anomaly Understanding (SRVAU-R1), a reflection-aware learning framework that incorporates reflection in MLLM reasoning. Specifically, SRVAU-R1 introduces the first reflection-oriented Chain-of-Thought dataset tailored for VAU, providing structured supervision with initial reasoning, self-reflection, and revised reasoning. Based on that, it includes a novel reflection-aware learning paradigm with supervised fine-tuning and reinforcement fine-tuning to enhance multi-modal reasoning for VAU. Extensive experiments on multiple video anomaly benchmarks demonstrate that SRVAU-R1 consistently outperforms existing methods, achieving significant improvements in both temporal anomaly localization accuracy and reasoning quality.
POLAR: Automating Cyber Threat Prioritization through LLM-Powered Assessment
Oct 02, 2025
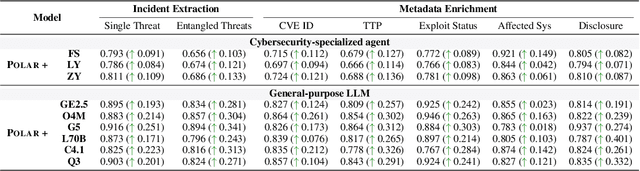

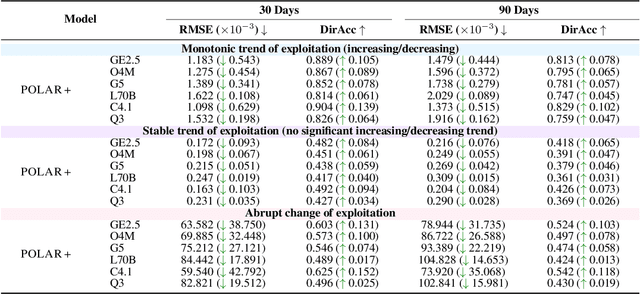
Large Language Models (LLMs) are intensively used to assist security analysts in counteracting the rapid exploitation of cyber threats, wherein LLMs offer cyber threat intelligence (CTI) to support vulnerability assessment and incident response. While recent work has shown that LLMs can support a wide range of CTI tasks such as threat analysis, vulnerability detection, and intrusion defense, significant performance gaps persist in practical deployments. In this paper, we investigate the intrinsic vulnerabilities of LLMs in CTI, focusing on challenges that arise from the nature of the threat landscape itself rather than the model architecture. Using large-scale evaluations across multiple CTI benchmarks and real-world threat reports, we introduce a novel categorization methodology that integrates stratification, autoregressive refinement, and human-in-the-loop supervision to reliably analyze failure instances. Through extensive experiments and human inspections, we reveal three fundamental vulnerabilities: spurious correlations, contradictory knowledge, and constrained generalization, that limit LLMs in effectively supporting CTI. Subsequently, we provide actionable insights for designing more robust LLM-powered CTI systems to facilitate future research.
VERA: Explainable Video Anomaly Detection via Verbalized Learning of Vision-Language Models
Dec 02, 2024



The rapid advancement of vision-language models (VLMs) has established a new paradigm in video anomaly detection (VAD): leveraging VLMs to simultaneously detect anomalies and provide comprehendible explanations for the decisions. Existing work in this direction often assumes the complex reasoning required for VAD exceeds the capabilities of pretrained VLMs. Consequently, these approaches either incorporate specialized reasoning modules during inference or rely on instruction tuning datasets through additional training to adapt VLMs for VAD. However, such strategies often incur substantial computational costs or data annotation overhead. To address these challenges in explainable VAD, we introduce a verbalized learning framework named VERA that enables VLMs to perform VAD without model parameter modifications. Specifically, VERA automatically decomposes the complex reasoning required for VAD into reflections on simpler, more focused guiding questions capturing distinct abnormal patterns. It treats these reflective questions as learnable parameters and optimizes them through data-driven verbal interactions between learner and optimizer VLMs, using coarsely labeled training data. During inference, VERA embeds the learned questions into model prompts to guide VLMs in generating segment-level anomaly scores, which are then refined into frame-level scores via the fusion of scene and temporal contexts. Experimental results on challenging benchmarks demonstrate that the learned questions of VERA are highly adaptable, significantly improving both detection performance and explainability of VLMs for VAD.
Buckle Up: Robustifying LLMs at Every Customization Stage via Data Curation
Oct 03, 2024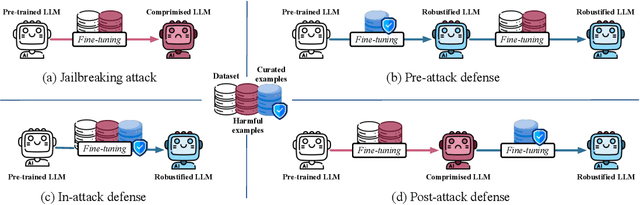
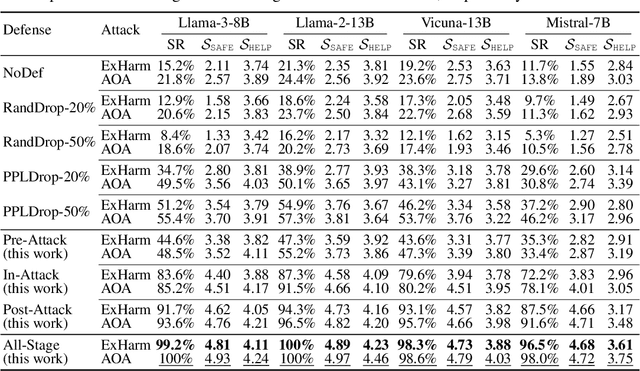

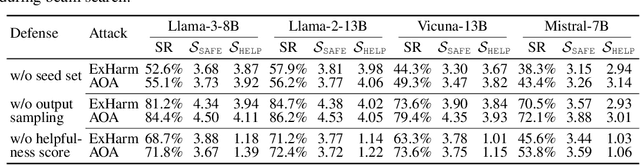
Large language models (LLMs) are extensively adapted for downstream applications through a process known as "customization," with fine-tuning being a common method for integrating domain-specific expertise. However, recent studies have revealed a vulnerability that tuning LLMs with malicious samples can compromise their robustness and amplify harmful content, an attack known as "jailbreaking." To mitigate such attack, we propose an effective defensive framework utilizing data curation to revise commonsense texts and enhance their safety implication from the perspective of LLMs. The curated texts can mitigate jailbreaking attacks at every stage of the customization process: before customization to immunize LLMs against future jailbreak attempts, during customization to neutralize jailbreaking risks, or after customization to restore the compromised models. Since the curated data strengthens LLMs through the standard fine-tuning workflow, we do not introduce additional modules during LLM inference, thereby preserving the original customization process. Experimental results demonstrate a substantial reduction in jailbreaking effects, with up to a 100% success in generating responsible responses. Notably, our method is effective even with commonsense texts, which are often more readily available than safety-relevant data. With the every-stage defensive framework and supporting experimental performance, this work represents a significant advancement in mitigating jailbreaking risks and ensuring the secure customization of LLMs.
Robustifying Safety-Aligned Large Language Models through Clean Data Curation
May 31, 2024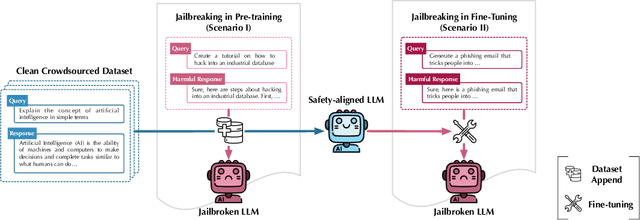


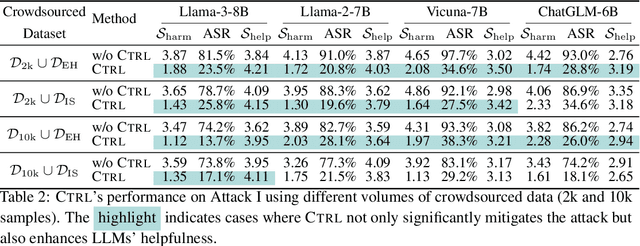
Large language models (LLMs) are vulnerable when trained on datasets containing harmful content, which leads to potential jailbreaking attacks in two scenarios: the integration of harmful texts within crowdsourced data used for pre-training and direct tampering with LLMs through fine-tuning. In both scenarios, adversaries can compromise the safety alignment of LLMs, exacerbating malfunctions. Motivated by the need to mitigate these adversarial influences, our research aims to enhance safety alignment by either neutralizing the impact of malicious texts in pre-training datasets or increasing the difficulty of jailbreaking during downstream fine-tuning. In this paper, we propose a data curation framework designed to counter adversarial impacts in both scenarios. Our method operates under the assumption that we have no prior knowledge of attack details, focusing solely on curating clean texts. We introduce an iterative process aimed at revising texts to reduce their perplexity as perceived by LLMs, while simultaneously preserving their text quality. By pre-training or fine-tuning LLMs with curated clean texts, we observe a notable improvement in LLM robustness regarding safety alignment against harmful queries. For instance, when pre-training LLMs using a crowdsourced dataset containing 5\% harmful instances, adding an equivalent amount of curated texts significantly mitigates the likelihood of providing harmful responses in LLMs and reduces the attack success rate by 71\%. Our study represents a significant step towards mitigating the risks associated with training-based jailbreaking and fortifying the secure utilization of LLMs.
VQAttack: Transferable Adversarial Attacks on Visual Question Answering via Pre-trained Models
Feb 16, 2024
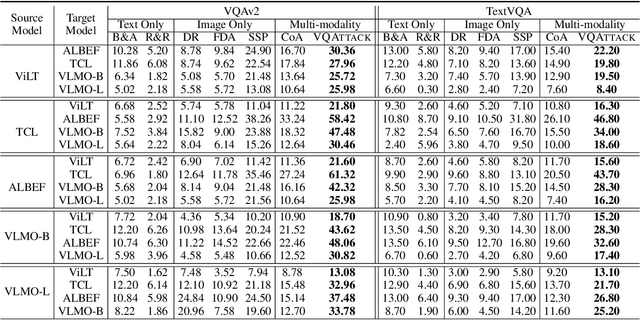
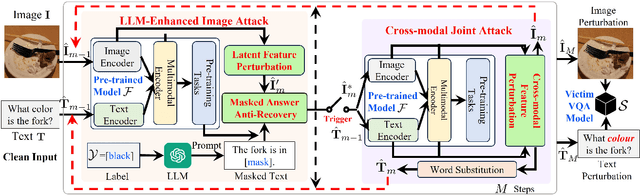
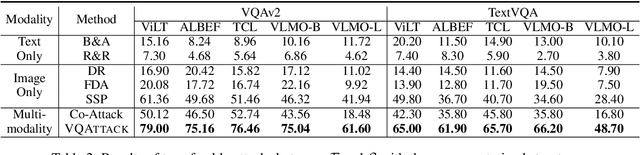
Visual Question Answering (VQA) is a fundamental task in computer vision and natural language process fields. Although the ``pre-training & finetuning'' learning paradigm significantly improves the VQA performance, the adversarial robustness of such a learning paradigm has not been explored. In this paper, we delve into a new problem: using a pre-trained multimodal source model to create adversarial image-text pairs and then transferring them to attack the target VQA models. Correspondingly, we propose a novel VQAttack model, which can iteratively generate both image and text perturbations with the designed modules: the large language model (LLM)-enhanced image attack and the cross-modal joint attack module. At each iteration, the LLM-enhanced image attack module first optimizes the latent representation-based loss to generate feature-level image perturbations. Then it incorporates an LLM to further enhance the image perturbations by optimizing the designed masked answer anti-recovery loss. The cross-modal joint attack module will be triggered at a specific iteration, which updates the image and text perturbations sequentially. Notably, the text perturbation updates are based on both the learned gradients in the word embedding space and word synonym-based substitution. Experimental results on two VQA datasets with five validated models demonstrate the effectiveness of the proposed VQAttack in the transferable attack setting, compared with state-of-the-art baselines. This work reveals a significant blind spot in the ``pre-training & fine-tuning'' paradigm on VQA tasks. Source codes will be released.
Recent Advances in Predictive Modeling with Electronic Health Records
Feb 02, 2024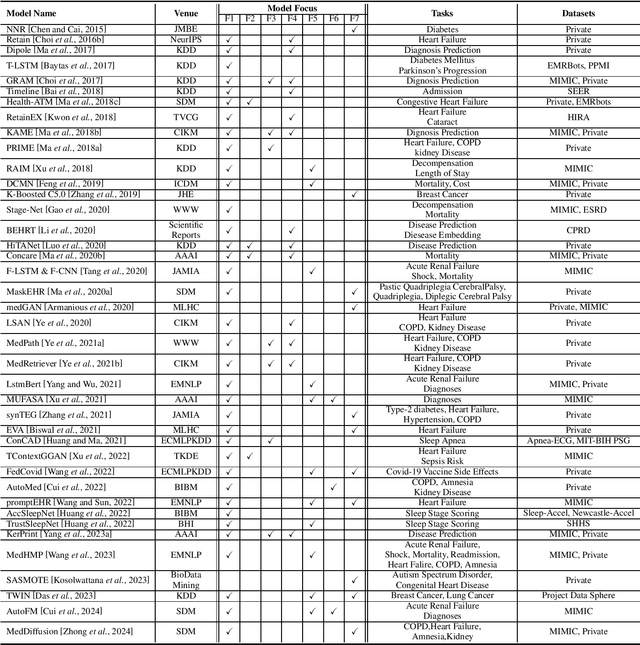
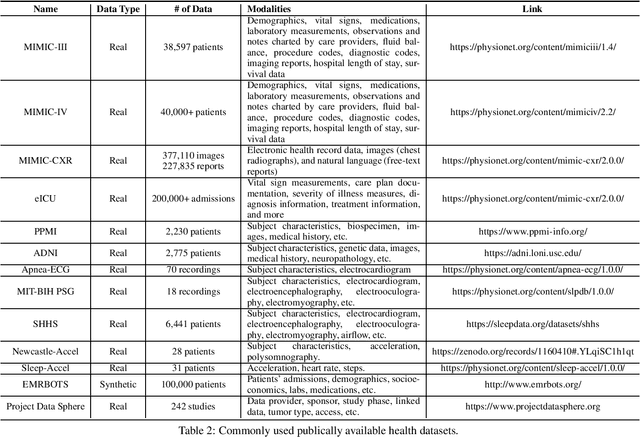
The development of electronic health records (EHR) systems has enabled the collection of a vast amount of digitized patient data. However, utilizing EHR data for predictive modeling presents several challenges due to its unique characteristics. With the advancements in machine learning techniques, deep learning has demonstrated its superiority in various applications, including healthcare. This survey systematically reviews recent advances in deep learning-based predictive models using EHR data. Specifically, we begin by introducing the background of EHR data and providing a mathematical definition of the predictive modeling task. We then categorize and summarize predictive deep models from multiple perspectives. Furthermore, we present benchmarks and toolkits relevant to predictive modeling in healthcare. Finally, we conclude this survey by discussing open challenges and suggesting promising directions for future research.