 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhyAVBench: A Challenging Audio Physics-Sensitivity Benchmark for Physically Grounded Text-to-Audio-Video Generation
Dec 30, 2025Text-to-audio-video (T2AV) generation underpins a wide range of applications demanding realistic audio-visual content, including virtual reality, world modeling, gaming, and filmmaking. However, existing T2AV models remain incapable of generating physically plausible sounds, primarily due to their limited understanding of physical principles. To situate current research progress, we present PhyAVBench, a challenging audio physics-sensitivity benchmark designed to systematically evaluate the audio physics grounding capabilities of existing T2AV models. PhyAVBench comprises 1,000 groups of paired text prompts with controlled physical variables that implicitly induce sound variations, enabling a fine-grained assessment of models' sensitivity to changes in underlying acoustic conditions. We term this evaluation paradigm the Audio-Physics Sensitivity Test (APST). Unlike prior benchmarks that primarily focus on audio-video synchronization, PhyAVBench explicitly evaluates models' understanding of the physical mechanisms underlying sound generation, covering 6 major audio physics dimensions, 4 daily scenarios (music, sound effects, speech, and their mix), and 50 fine-grained test points, ranging from fundamental aspects such as sound diffraction to more complex phenomena, e.g., Helmholtz resonance. Each test point consists of multiple groups of paired prompts, where each prompt is grounded by at least 20 newly recorded or collected real-world videos, thereby minimizing the risk of data leakage during model pre-training. Both prompts and videos are iteratively refined through rigorous human-involved error correction and quality control to ensure high quality. We argue that only models with a genuine grasp of audio-related physical principles can generate physically consistent audio-visual content. We hope PhyAVBench will stimulate future progress in this critical yet largely unexplored domain.
Towards Underwater Camouflaged Object Tracking: An Experimental Evaluation of SAM and SAM 2
Sep 25, 2024

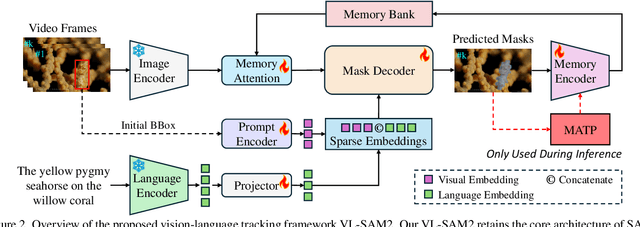
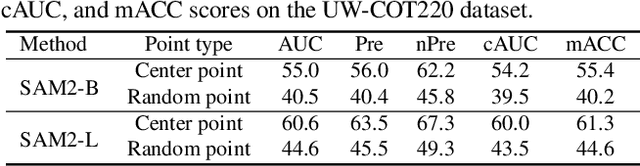
Over the past decade, significant progress has been made in visual object tracking, largely due to the availability of large-scale training datasets. However, existing tracking datasets are primarily focused on open-air scenarios, which greatly limits the development of object tracking in underwater environments. To address this issue, we take a step forward by proposing the first large-scale underwater camouflaged object tracking dataset, namely UW-COT. Based on the proposed dataset, this paper presents an experimental evaluation of several advanced visual object tracking methods and the latest advancements in image and video segmentation. Specifically, we compare the performance of the Segment Anything Model (SAM) and its updated version, SAM 2, in challenging underwater environments. Our findings highlight the improvements in SAM 2 over SAM, demonstrating its enhanced capability to handle the complexities of underwater camouflaged objects. Compared to current advanced visual object tracking methods, the latest video segmentation foundation model SAM 2 also exhibits significant advantages, providing valuable insights into the development of more effective tracking technologies for underwater scenarios. The dataset will be accessible at \color{magenta}{https://github.com/983632847/Awesome-Multimodal-Object-Tracking}.
A Comprehensive Survey on Human Video Generation: Challenges, Methods, and Insights
Jul 11, 2024



Human video generation is a dynamic and rapidly evolving task that aims to synthesize 2D human body video sequences with generative models given control conditions such as text, audio, and pose. With the potential for wide-ranging applications in film, gaming, and virtual communication, the ability to generate natural and realistic human video is critical. Recent advancements in generative models have laid a solid foundation for the growing interest in this area. Despite the significant progress, the task of human video generation remains challenging due to the consistency of characters, the complexity of human motion, and difficulties in their relationship with the environment. This survey provides a comprehensive review of the current state of human video generation, marking, to the best of our knowledge, the first extensive literature review in this domain. We start with an introduction to the fundamentals of human video generation and the evolution of generative models that have facilitated the field's growth. We then examine the main methods employed for three key sub-tasks within human video generation: text-driven, audio-driven, and pose-driven motion generation. These areas are explored concerning the conditions that guide the generation process. Furthermore, we offer a collection of the most commonly utilized datasets and the evaluation metrics that are crucial in assessing the quality and realism of generated videos. The survey concludes with a discussion of the current challenges in the field and suggests possible directions for future research. The goal of this survey is to offer the research community a clear and holistic view of the advancements in human video generation, highlighting the milestones achieved and the challenges that lie ahead.
WebUOT-1M: Advancing Deep Underwater Object Tracking with A Million-Scale Benchmark
May 30, 2024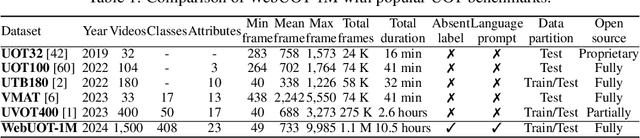

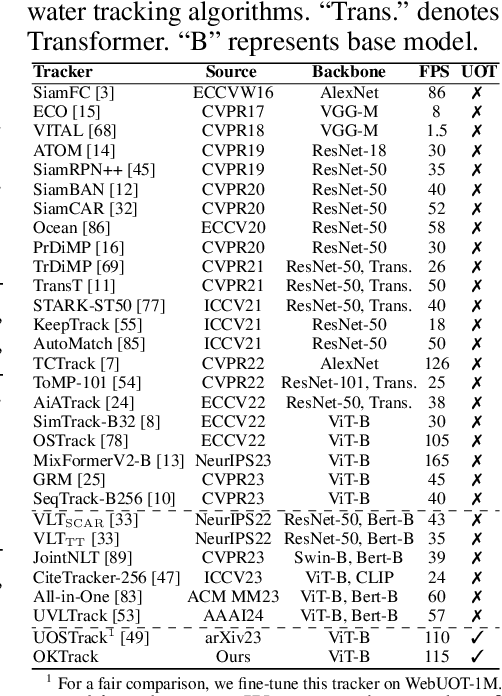

Underwater object tracking (UOT) is a foundational task for identifying and tracing submerged entities in underwater video sequences. However, current UOT datasets suffer from limitations in scale, diversity of target categories and scenarios covered, hindering the training and evaluation of modern tracking algorithms. To bridge this gap, we take the first step and introduce WebUOT-1M, \ie, the largest public UOT benchmark to date, sourced from complex and realistic underwater environments. It comprises 1.1 million frames across 1,500 video clips filtered from 408 target categories, largely surpassing previous UOT datasets, \eg, UVOT400. Through meticulous manual annotation and verification, we provide high-quality bounding boxes for underwater targets. Additionally, WebUOT-1M includes language prompts for video sequences, expanding its application areas, \eg, underwater vision-language tracking. Most existing trackers are tailored for open-air environments, leading to performance degradation when applied to UOT due to domain gaps. Retraining and fine-tuning these trackers are challenging due to sample imbalances and limited real-world underwater datasets. To tackle these challenges, we propose a novel omni-knowledge distillation framework based on WebUOT-1M, incorporating various strategies to guide the learning of the student Transformer. To the best of our knowledge, this framework is the first to effectively transfer open-air domain knowledge to the UOT model through knowledge distillation, as demonstrated by results on both existing UOT datasets and the newly proposed WebUOT-1M. Furthermore, we comprehensively evaluate WebUOT-1M using 30 deep trackers, showcasing its value as a benchmark for UOT research by presenting new challenges and opportunities for future studies. The complete dataset, codes and tracking results, will be made publicly available.
Recent Advances in Predictive Modeling with Electronic Health Records
Feb 02, 2024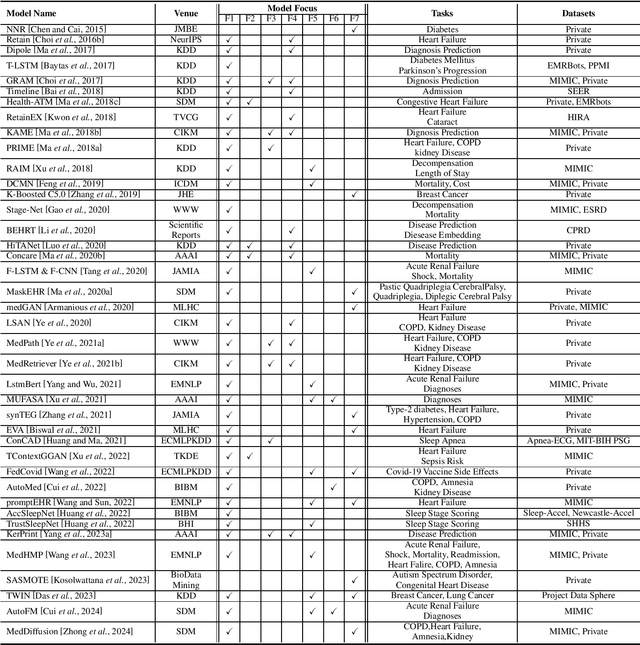
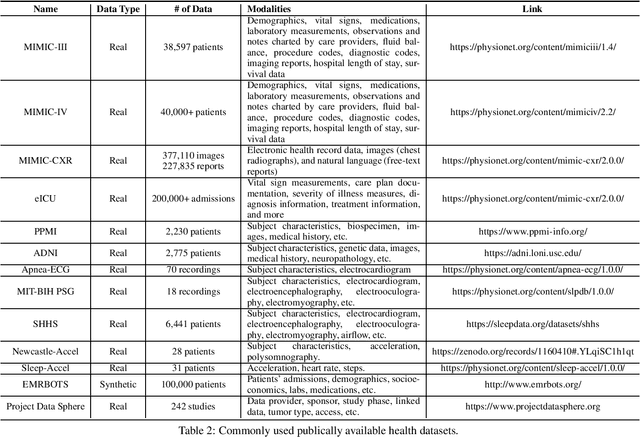
The development of electronic health records (EHR) systems has enabled the collection of a vast amount of digitized patient data. However, utilizing EHR data for predictive modeling presents several challenges due to its unique characteristics. With the advancements in machine learning techniques, deep learning has demonstrated its superiority in various applications, including healthcare. This survey systematically reviews recent advances in deep learning-based predictive models using EHR data. Specifically, we begin by introducing the background of EHR data and providing a mathematical definition of the predictive modeling task. We then categorize and summarize predictive deep models from multiple perspectives. Furthermore, we present benchmarks and toolkits relevant to predictive modeling in healthcare. Finally, we conclude this survey by discussing open challenges and suggesting promising directions for future research.
A Comprehensive Survey on Segment Anything Model for Vision and Beyond
May 19, 2023



Artificial intelligence (AI) is evolving towards artificial general intelligence, which refers to the ability of an AI system to perform a wide range of tasks and exhibit a level of intelligence similar to that of a human being. This is in contrast to narrow or specialized AI, which is designed to perform specific tasks with a high degree of efficiency. Therefore, it is urgent to design a general class of models, which we term foundation models, trained on broad data that can be adapted to various downstream tasks. The recently proposed segment anything model (SAM) has made significant progress in breaking the boundaries of segmentation, greatly promoting the development of foundation models for computer vision. To fully comprehend SAM, we conduct a survey study. As the first to comprehensively review the progress of segmenting anything task for vision and beyond based on the foundation model of SAM, this work focuses on its applications to various tasks and data types by discussing its historical development, recent progress, and profound impact on broad applications. We first introduce the background and terminology for foundation models including SAM, as well as state-of-the-art methods contemporaneous with SAM that are significant for segmenting anything task. Then, we analyze and summarize the advantages and limitations of SAM across various image processing applications, including software scenes, real-world scenes, and complex scenes. Importantly, many insights are drawn to guide future research to develop more versatile foundation models and improve the architecture of SAM. We also summarize massive other amazing applications of SAM in vision and beyond. Finally, we maintain a continuously updated paper list and an open-source project summary for foundation model SAM at \href{https://github.com/liliu-avril/Awesome-Segment-Anything}{\color{magenta}{here}}.
WebUAV-3M: A Benchmark Unveiling the Power of Million-Scale Deep UAV Tracking
Jan 24, 2022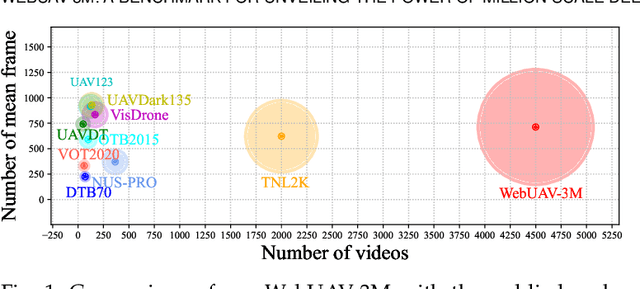
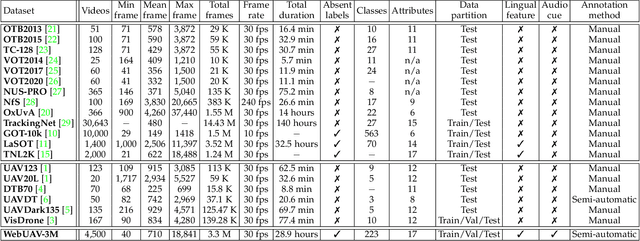

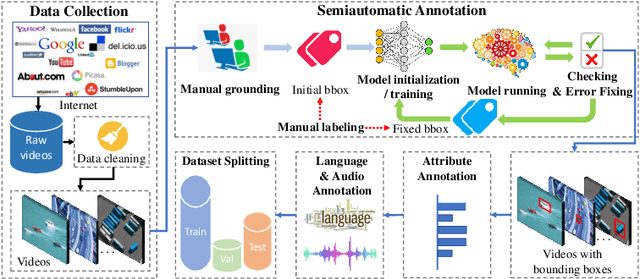
In this work, we contribute a new million-scale Unmanned Aerial Vehicle (UAV) tracking benchmark, called WebUAV-3M. Firstly, we collect 4,485 videos with more than 3M frames from the Internet. Then, an efficient and scalable Semi-Automatic Target Annotation (SATA) pipeline is devised to label the tremendous WebUAV-3M in every frame. To the best of our knowledge, the densely bounding box annotated WebUAV-3M is by far the largest public UAV tracking benchmark. We expect to pave the way for the follow-up study in the UAV tracking by establishing a million-scale annotated benchmark covering a wide range of target categories. Moreover, considering the close connections among visual appearance, natural language and audio, we enrich WebUAV-3M by providing natural language specification and audio description, encouraging the exploration of natural language features and audio cues for UAV tracking. Equipped with this benchmark, we delve into million-scale deep UAV tracking problems, aiming to provide the community with a dedicated large-scale benchmark for training deep UAV trackers and evaluating UAV tracking approaches. Extensive experiments on WebUAV-3M demonstrate that there is still a big room for robust deep UAV tracking improvements. The dataset, toolkits and baseline results will be available at \url{https://github.com/983632847/WebUAV-3M}.
Unified Style Transfer
Oct 20, 2021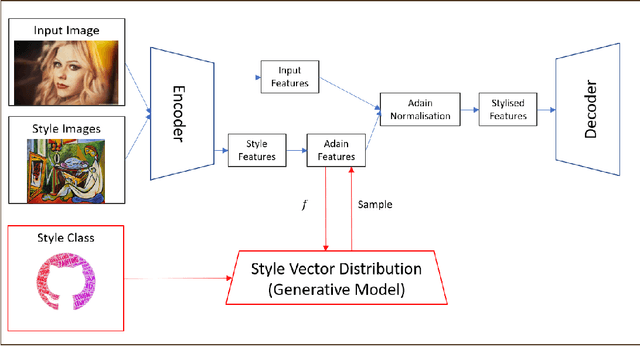
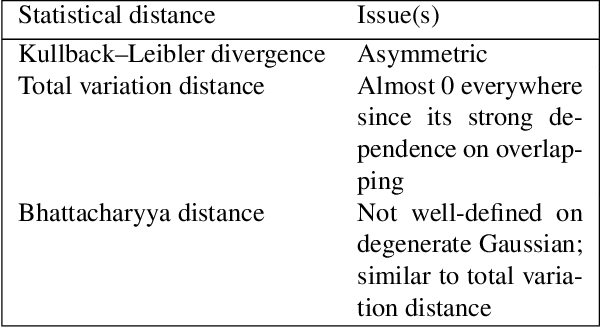
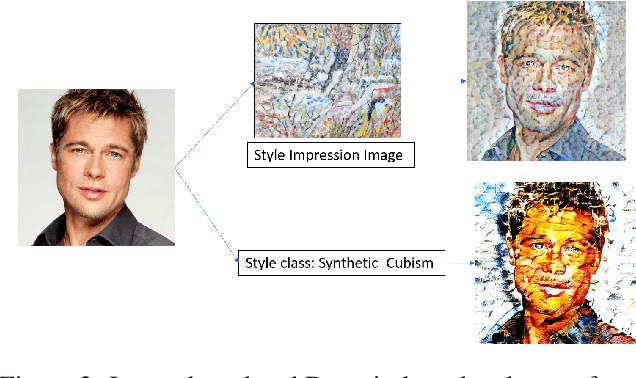

Currently, it is hard to compare and evaluate different style transfer algorithms due to chaotic definitions of style and the absence of agreed objective validation methods in the study of style transfer. In this paper, a novel approach, the Unified Style Transfer (UST) model, is proposed. With the introduction of a generative model for internal style representation, UST can transfer images in two approaches, i.e., Domain-based and Image-based, simultaneously. At the same time, a new philosophy based on the human sense of art and style distributions for evaluating the transfer model is presented and demonstrated, called Statistical Style Analysis. It provides a new path to validate style transfer models' feasibility by validating the general consistency between internal style representation and art facts. Besides, the translation-invariance of AdaIN features is also discussed.
ConCAD: Contrastive Learning-based Cross Attention for Sleep Apnea Detection
May 07, 2021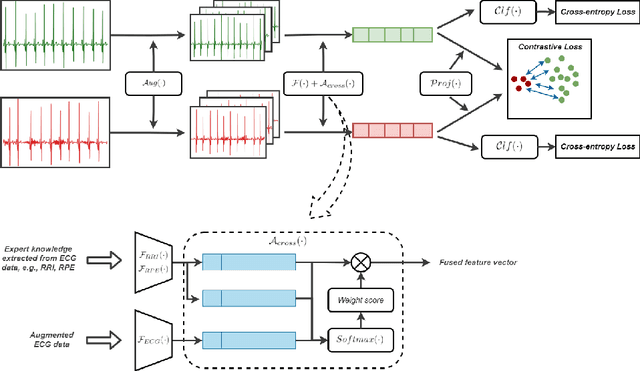
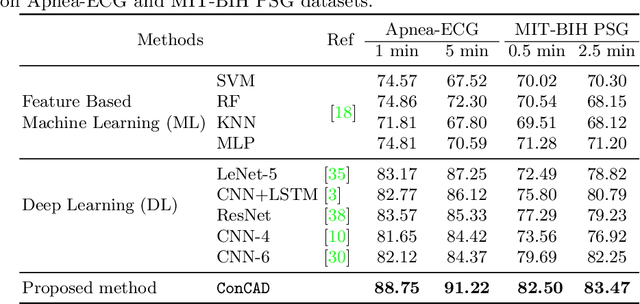
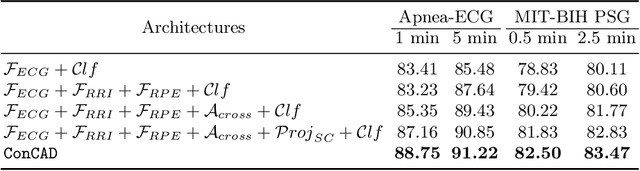

With recent advancements in deep learning methods, automatically learning deep features from the original data is becoming an effective and widespread approach. However, the hand-crafted expert knowledge-based features are still insightful. These expert-curated features can increase the model's generalization and remind the model of some data characteristics, such as the time interval between two patterns. It is particularly advantageous in tasks with the clinically-relevant data, where the data are usually limited and complex. To keep both implicit deep features and expert-curated explicit features together, an effective fusion strategy is becoming indispensable. In this work, we focus on a specific clinical application, i.e., sleep apnea detection. In this context, we propose a contrastive learning-based cross attention framework for sleep apnea detection (named ConCAD). The cross attention mechanism can fuse the deep and expert features by automatically assigning attention weights based on their importance. Contrastive learning can learn better representations by keeping the instances of each class closer and pushing away instances from different classes in the embedding space concurrently. Furthermore, a new hybrid loss is designed to simultaneously conduct contrastive learning and classification by integrating a supervised contrastive loss with a cross-entropy loss. Our proposed framework can be easily integrated into standard deep learning models to utilize expert knowledge and contrastive learning to boost performance. As demonstrated on two public ECG dataset with sleep apnea annotation, ConCAD significantly improves the detection performance and outperforms state-of-art benchmark methods.
Hippocampus-heuristic Character Recognition Network for Zero-shot Learning
Apr 06, 2021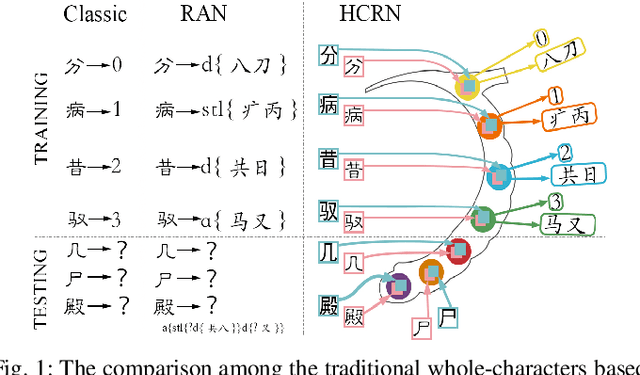
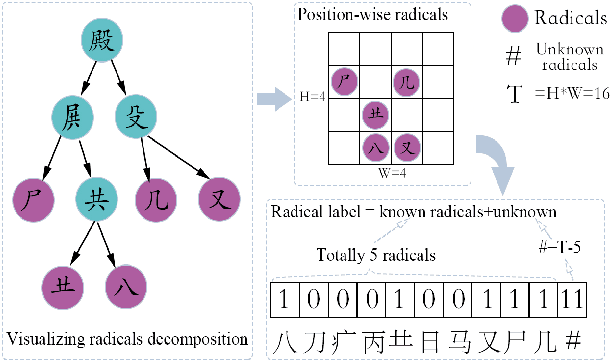
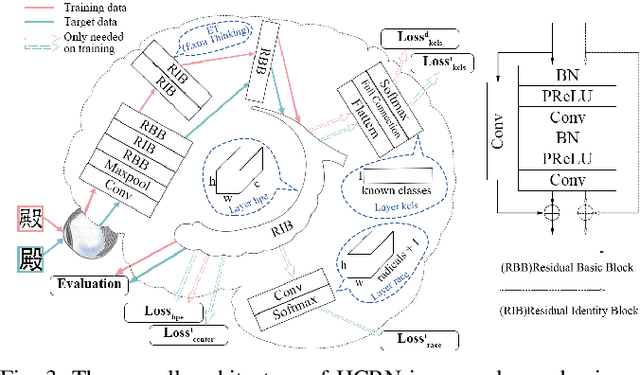
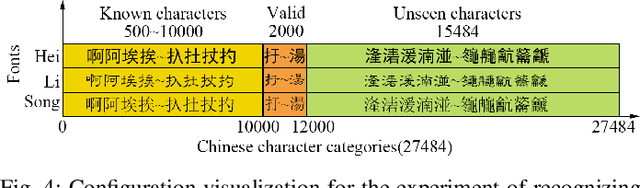
The recognition of Chinese characters has always been a challenging task due to their huge variety and complex structures. The latest research proves that such an enormous character set can be decomposed into a collection of about 500 fundamental Chinese radicals, and based on which this problem can be solved effectively. While with the constant advent of novel Chinese characters, the number of basic radicals is also expanding. The current methods that entirely rely on existing radicals are not flexible for identifying these novel characters and fail to recognize these Chinese characters without learning all of their radicals in the training stage. To this end, this paper proposes a novel Hippocampus-heuristic Character Recognition Network (HCRN), which references the way of hippocampus thinking, and can recognize unseen Chinese characters (namely zero-shot learning) only by training part of radicals. More specifically, the network architecture of HCRN is a new pseudo-siamese network designed by us, which can learn features from pairs of input training character samples and use them to predict unseen Chinese characters. The experimental results show that HCRN is robust and effective. It can accurately predict about 16,330 unseen testing Chinese characters relied on only 500 trained Chinese characters. The recognition accuracy of HCRN outperforms the state-of-the-art Chinese radical recognition approach by 15% (from 85.1% to 99.9%) for recognizing unseen Chinese characters.