 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Progressive Visual-Logic-Aligned Framework for Ride-Hailing Adjudication
Mar 18, 2026The efficient adjudication of responsibility disputes is pivotal for maintaining marketplace fairness. However, the exponential surge in ride-hailing volume renders manual review intractable, while conventional automated methods lack the reasoning transparency required for quasi-judicial decisions. Although Multimodal LLMs offer a promising paradigm, they fundamentally struggle to bridge the gap between general visual semantics and rigorous evidentiary protocols, often leading to perceptual hallucinations and logical looseness. To address these systemic misalignments, we introduce RideJudge, a Progressive Visual-Logic-Aligned Framework. Instead of relying on generic pre-training, we bridge the semantic gap via SynTraj, a synthesis engine that grounds abstract liability concepts into concrete trajectory patterns. To resolve the conflict between massive regulation volume and limited context windows, we propose an Adaptive Context Optimization strategy that distills expert knowledge, coupled with a Chain-of-Adjudication mechanism to enforce active evidentiary inquiry. Furthermore, addressing the inadequacy of sparse binary feedback for complex liability assessment, we implement a novel Ordinal-Sensitive Reinforcement Learning mechanism that calibrates decision boundaries against hierarchical severity. Extensive experiments show that our RideJudge-8B achieves 88.41\% accuracy, surpassing 32B-scale baselines and establishing a new standard for interpretable adjudication.
MANSION: Multi-floor lANguage-to-3D Scene generatIOn for loNg-horizon tasks
Mar 12, 2026Real-world robotic tasks are long-horizon and often span multiple floors, demanding rich spatial reasoning. However, existing embodied benchmarks are largely confined to single-floor in-house environments, failing to reflect the complexity of real-world tasks. We introduce MANSION, the first language-driven framework for generating building-scale, multi-floor 3D environments. Being aware of vertical structural constraints, MANSION generates realistic, navigable whole-building structures with diverse, human-friendly scenes, enabling the development and evaluation of cross-floor long-horizon tasks. Building on this framework, we release MansionWorld, a dataset of over 1,000 diverse buildings ranging from hospitals to offices, alongside a Task-Semantic Scene Editing Agent that customizes these environments using open-vocabulary commands to meet specific user needs. Benchmarking reveals that state-of-the-art agents degrade sharply in our settings, establishing MANSION as a critical testbed for the next generation of spatial reasoning and planning.
STEP: Warm-Started Visuomotor Policies with Spatiotemporal Consistency Prediction
Feb 09, 2026Diffusion policies have recently emerged as a powerful paradigm for visuomotor control in robotic manipulation due to their ability to model the distribution of action sequences and capture multimodality. However, iterative denoising leads to substantial inference latency, limiting control frequency in real-time closed-loop systems. Existing acceleration methods either reduce sampling steps, bypass diffusion through direct prediction, or reuse past actions, but often struggle to jointly preserve action quality and achieve consistently low latency. In this work, we propose STEP, a lightweight spatiotemporal consistency prediction mechanism to construct high-quality warm-start actions that are both distributionally close to the target action and temporally consistent, without compromising the generative capability of the original diffusion policy. Then, we propose a velocity-aware perturbation injection mechanism that adaptively modulates actuation excitation based on temporal action variation to prevent execution stall especially for real-world tasks. We further provide a theoretical analysis showing that the proposed prediction induces a locally contractive mapping, ensuring convergence of action errors during diffusion refinement. We conduct extensive evaluations on nine simulated benchmarks and two real-world tasks. Notably, STEP with 2 steps can achieve an average 21.6% and 27.5% higher success rate than BRIDGER and DDIM on the RoboMimic benchmark and real-world tasks, respectively. These results demonstrate that STEP consistently advances the Pareto frontier of inference latency and success rate over existing methods.
ARC: Active and Reflection-driven Context Management for Long-Horizon Information Seeking Agents
Jan 17, 2026Large language models are increasingly deployed as research agents for deep search and long-horizon information seeking, yet their performance often degrades as interaction histories grow. This degradation, known as context rot, reflects a failure to maintain coherent and task-relevant internal states over extended reasoning horizons. Existing approaches primarily manage context through raw accumulation or passive summarization, treating it as a static artifact and allowing early errors or misplaced emphasis to persist. Motivated by this perspective, we propose ARC, which is the first framework to systematically formulate context management as an active, reflection-driven process that treats context as a dynamic internal reasoning state during execution. ARC operationalizes this view through reflection-driven monitoring and revision, allowing agents to actively reorganize their working context when misalignment or degradation is detected. Experiments on challenging long-horizon information-seeking benchmarks show that ARC consistently outperforms passive context compression methods, achieving up to an 11% absolute improvement in accuracy on BrowseComp-ZH with Qwen2.5-32B-Instruct.
Effective Code Membership Inference for Code Completion Models via Adversarial Prompts
Nov 19, 2025Membership inference attacks (MIAs) on code completion models offer an effective way to assess privacy risks by inferring whether a given code snippet was part of the training data. Existing black- and gray-box MIAs rely on expensive surrogate models or manually crafted heuristic rules, which limit their ability to capture the nuanced memorization patterns exhibited by over-parameterized code language models. To address these challenges, we propose AdvPrompt-MIA, a method specifically designed for code completion models, combining code-specific adversarial perturbations with deep learning. The core novelty of our method lies in designing a series of adversarial prompts that induce variations in the victim code model's output. By comparing these outputs with the ground-truth completion, we construct feature vectors to train a classifier that automatically distinguishes member from non-member samples. This design allows our method to capture richer memorization patterns and accurately infer training set membership. We conduct comprehensive evaluations on widely adopted models, such as Code Llama 7B, over the APPS and HumanEval benchmarks. The results show that our approach consistently outperforms state-of-the-art baselines, with AUC gains of up to 102%. In addition, our method exhibits strong transferability across different models and datasets, underscoring its practical utility and generalizability.
Speculative Decoding for Verilog: Speed and Quality, All in One
Mar 18, 2025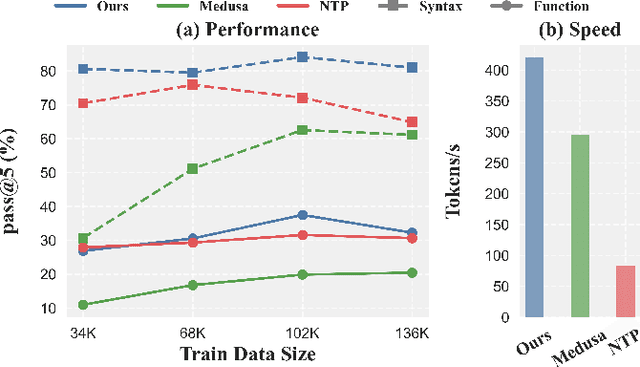
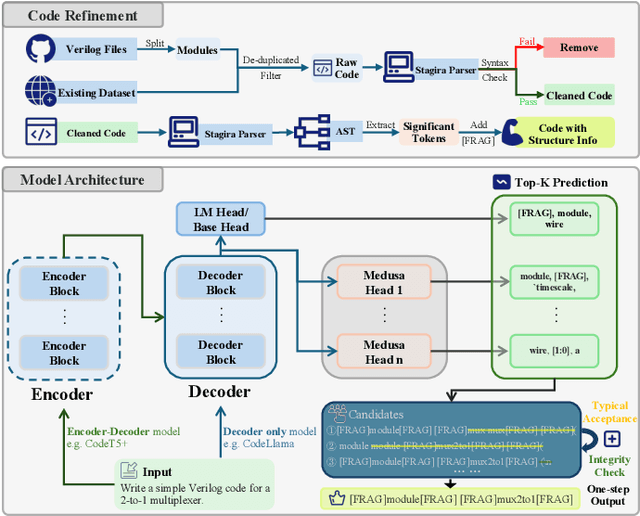
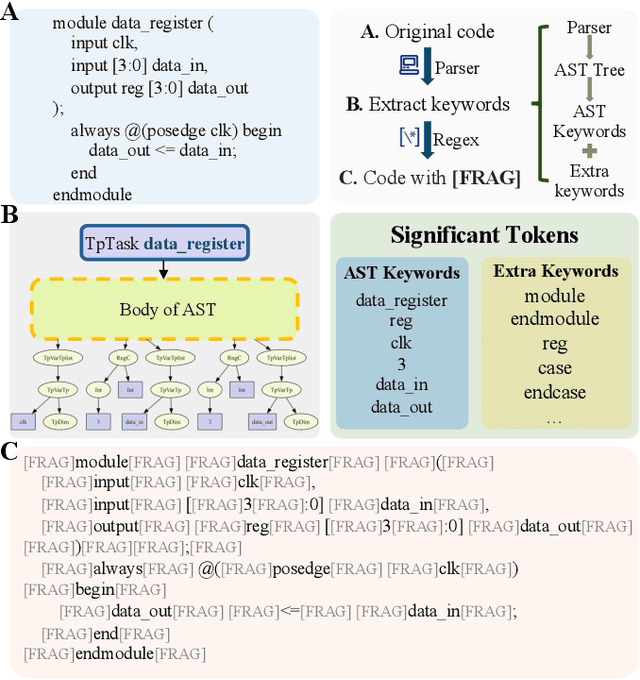
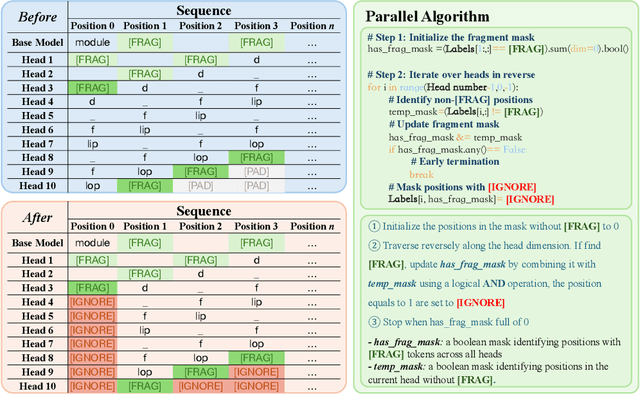
The rapid advancement of large language models (LLMs) has revolutionized code generation tasks across various programming languages. However, the unique characteristics of programming languages, particularly those like Verilog with specific syntax and lower representation in training datasets, pose significant challenges for conventional tokenization and decoding approaches. In this paper, we introduce a novel application of speculative decoding for Verilog code generation, showing that it can improve both inference speed and output quality, effectively achieving speed and quality all in one. Unlike standard LLM tokenization schemes, which often fragment meaningful code structures, our approach aligns decoding stops with syntactically significant tokens, making it easier for models to learn the token distribution. This refinement addresses inherent tokenization issues and enhances the model's ability to capture Verilog's logical constructs more effectively. Our experimental results show that our method achieves up to a 5.05x speedup in Verilog code generation and increases pass@10 functional accuracy on RTLLM by up to 17.19% compared to conventional training strategies. These findings highlight speculative decoding as a promising approach to bridge the quality gap in code generation for specialized programming languages.
Enhancing High-Quality Code Generation in Large Language Models with Comparative Prefix-Tuning
Mar 12, 2025Large Language Models (LLMs) have been widely adopted in commercial code completion engines, significantly enhancing coding efficiency and productivity. However, LLMs may generate code with quality issues that violate coding standards and best practices, such as poor code style and maintainability, even when the code is functionally correct. This necessitates additional effort from developers to improve the code, potentially negating the efficiency gains provided by LLMs. To address this problem, we propose a novel comparative prefix-tuning method for controllable high-quality code generation. Our method introduces a single, property-specific prefix that is prepended to the activations of the LLM, serving as a lightweight alternative to fine-tuning. Unlike existing methods that require training multiple prefixes, our approach trains only one prefix and leverages pairs of high-quality and low-quality code samples, introducing a sequence-level ranking loss to guide the model's training. This comparative approach enables the model to better understand the differences between high-quality and low-quality code, focusing on aspects that impact code quality. Additionally, we design a data construction pipeline to collect and annotate pairs of high-quality and low-quality code, facilitating effective training. Extensive experiments on the Code Llama 7B model demonstrate that our method improves code quality by over 100% in certain task categories, while maintaining functional correctness. We also conduct ablation studies and generalization experiments, confirming the effectiveness of our method's components and its strong generalization capability.
Large Language Model Inference Acceleration: A Comprehensive Hardware Perspective
Oct 06, 2024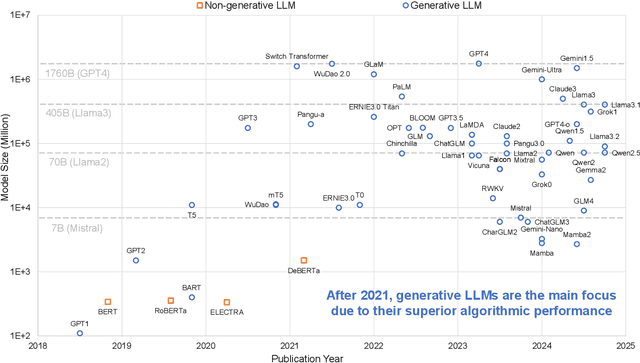
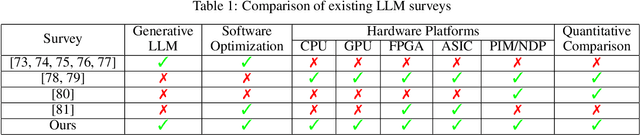
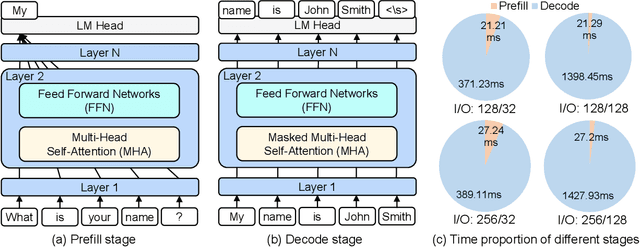
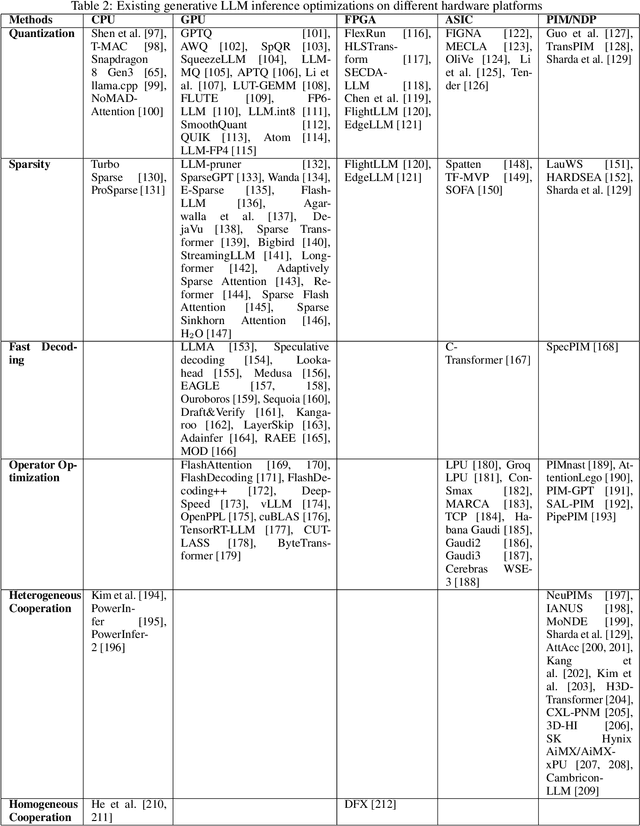
Large Language Models (LLMs) have demonstrated remarkable capabilities across various fields, from natural language understanding to text generation. Compared to non-generative LLMs like BERT and DeBERTa, generative LLMs like GPT series and Llama series are currently the main focus due to their superior algorithmic performance. The advancements in generative LLMs are closely intertwined with the development of hardware capabilities. Various hardware platforms exhibit distinct hardware characteristics, which can help improve LLM inference performance. Therefore, this paper comprehensively surveys efficient generative LLM inference on different hardware platforms. First, we provide an overview of the algorithm architecture of mainstream generative LLMs and delve into the inference process. Then, we summarize different optimization methods for different platforms such as CPU, GPU, FPGA, ASIC, and PIM/NDP, and provide inference results for generative LLMs. Furthermore, we perform a qualitative and quantitative comparison of inference performance with batch sizes 1 and 8 on different hardware platforms by considering hardware power consumption, absolute inference speed (tokens/s), and energy efficiency (tokens/J). We compare the performance of the same optimization methods across different hardware platforms, the performance across different hardware platforms, and the performance of different methods on the same hardware platform. This provides a systematic and comprehensive summary of existing inference acceleration work by integrating software optimization methods and hardware platforms, which can point to the future trends and potential developments of generative LLMs and hardware technology for edge-side scenarios.
MARCA: Mamba Accelerator with ReConfigurable Architecture
Sep 16, 2024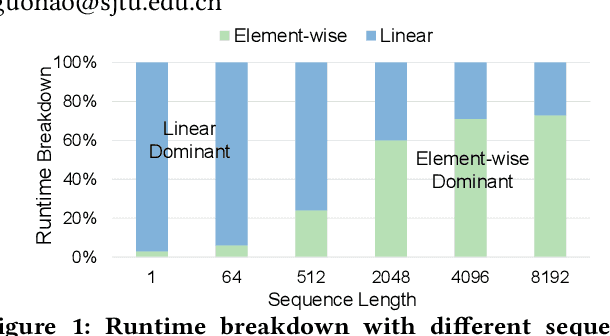
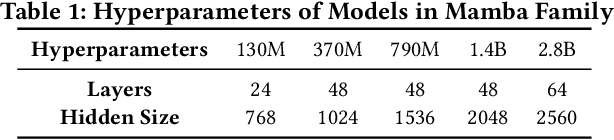

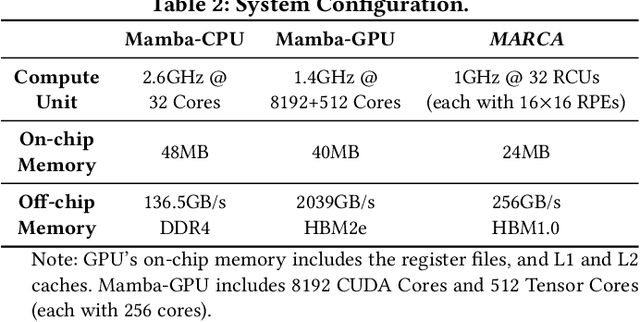
We propose a Mamba accelerator with reconfigurable architecture, MARCA.We propose three novel approaches in this paper. (1) Reduction alternative PE array architecture for both linear and element-wise operations. For linear operations, the reduction tree connected to PE arrays is enabled and executes the reduction operation. For element-wise operations, the reduction tree is disabled and the output bypasses. (2) Reusable nonlinear function unit based on the reconfigurable PE. We decompose the exponential function into element-wise operations and a shift operation by a fast biased exponential algorithm, and the activation function (SiLU) into a range detection and element-wise operations by a piecewise approximation algorithm. Thus, the reconfigurable PEs are reused to execute nonlinear functions with negligible accuracy loss.(3) Intra-operation and inter-operation buffer management strategy. We propose intra-operation buffer management strategy to maximize input data sharing for linear operations within operations, and inter-operation strategy for element-wise operations between operations. We conduct extensive experiments on Mamba model families with different sizes.MARCA achieves up to 463.22$\times$/11.66$\times$ speedup and up to 9761.42$\times$/242.52$\times$ energy efficiency compared to Intel Xeon 8358P CPU and NVIDIA Tesla A100 GPU implementations, respectively.
Enabling Fast 2-bit LLM on GPUs: Memory Alignment, Sparse Outlier, and Asynchronous Dequantization
Nov 28, 2023Large language models (LLMs) have demonstrated impressive abilities in various domains while the inference cost is expensive. The state-of-the-art methods use 2-bit quantization for mainstream LLMs. However, challenges still exist: (1) Nonnegligible accuracy loss for 2-bit quantization. Weights are quantized by groups, while the ranges of weights are large in some groups, resulting in large quantization errors and nonnegligible accuracy loss (e.g. >3% for Llama2-7b with 2-bit quantization in GPTQ and Greenbit). (2) Limited accuracy improvement by adding 4-bit weights. Increasing 10% extra average bit more 4-bit weights only leads to <0.5% accuracy improvement on a quantized Llama2-7b. (3) Time-consuming dequantization operations on GPUs. The dequantization operations lead to >50% execution time, hindering the potential of reducing LLM inference cost. To tackle these challenges, we propose the following techniques: (1) We only quantize a small fraction of groups with the larger range using 4-bit with memory alignment consideration on GPUs. (2) We point out that the distribution of the sparse outliers with larger weights is different in 2-bit and 4-bit groups, and only a small fraction of outliers require 16-bit quantization. Such design leads to >0.5% accuracy improvement with <3% average increased bit for Llama2-7b. (3) We design the asynchronous dequantization on GPUs, leading to up to 3.92X speedup. We conduct extensive experiments on different model families and model sizes. We achieve 2.85-bit for each weight and the end-to-end speedup for Llama2-7b is 1.74X over the original model, and we reduce both runtime cost and hardware cost by up to 2.70X and 2.81X with less GPU requirements.