 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Prompt Matters: State-Adaptive Optimization for Robust Fine-Tuning
Jun 01, 2026While prompt engineering is instrumental in maximizing the capabilities of Large Language Models (LLMs) during inference, the role of prompts during training remains critically underexplored. Prevailing fine-tuning paradigms typically treat training prompts as mere surface forms, assuming that semantically equivalent instructions yield identical learning outcomes. However, we reveal that this equivalence is deceptive: while paraphrased prompts often lead to comparable in-task performance, they induce drastically different cross-task impacts regarding catastrophic forgetting and generalization. Crucially, these impacts are positively correlated across tasks, indicating the existence of superior prompts that consistently yield better performance. Furthermore, we discover that these superior prompts can be robustly identified by task loss prior to learning. Leveraging these insights, we introduce State-Adaptive Prompt Optimization (SAPO), a lightweight yet effective training strategy that shifts task formulation from a static input to a dynamic, state-adaptive variable. Comprehensive experiments on diverse benchmarks confirm its effectiveness, which significantly mitigates forgetting while improving generalization, achieving substantial performance gains over state-of-the-art methods. These results provide insights into how training prompts shape learning dynamics and offer a practical recipe for robust fine-tuning. Our code is available at https://github.com/Eric8932/SAPO.
Scaling Agentic Capabilities via Grounded Interaction Synthesis
Jun 01, 2026General agentic intelligence hinges on the ability to interact with diverse real-world tools to complete complex tasks, a capability fundamentally tied to the quality of interaction data. To bypass the prohibitive costs of human annotation, prevailing paradigms depend entirely on Large Language Models (LLMs) to scale the synthesis of agentic environments and tasks. However, such unconstrained generation often degenerates into biased random sampling of LLMs' internal priors, failing to capture the diversity and difficulty of real-world domains or construct high-fidelity, long-horizon tasks. In this work, we introduce Grounded Agentic Interaction Synthesis (GAIS), a framework that automates the scalable construction of diverse environments and complex tasks via a two-phase grounding mechanism. Specifically, we construct protocol-anchored environments derived from real-world Model Context Protocol (MCP) servers to ensure functional diversity and difficulty. Subsequently, we employ structure-guided planning to navigate these environments, actively enforcing logical dependencies and adversarial policies to generate complex tasks. Experiments on BFCL, $τ^2$-Bench, and ACEBench demonstrate that GAIS-synthesized data significantly outperforms state-of-the-art baselines, enabling base models to match or even surpass their official instruction-tuned counterparts. Furthermore, GAIS exhibits superior data efficiency and scalability, achieving exceptional capabilities with significantly less data while maintaining continuous growth where baselines stagnate. Our code and dataset are publicly available at https://github.com/Eric8932/GAIS.
Joint Knowledge Editing for Information Enrichment and Probability Promotion
Dec 22, 2024Knowledge stored in large language models requires timely updates to reflect the dynamic nature of real-world information. To update the knowledge, most knowledge editing methods focus on the low layers, since recent probes into the knowledge recall process reveal that the answer information is enriched in low layers. However, these probes only and could only reveal critical recall stages for the original answers, while the goal of editing is to rectify model's prediction for the target answers. This inconsistency indicates that both the probe approaches and the associated editing methods are deficient. To mitigate the inconsistency and identify critical editing regions, we propose a contrast-based probe approach, and locate two crucial stages where the model behavior diverges between the original and target answers: Information Enrichment in low layers and Probability Promotion in high layers. Building upon the insights, we develop the Joint knowledge Editing for information Enrichment and probability Promotion (JEEP) method, which jointly edits both the low and high layers to modify the two critical recall stages. Considering the mutual interference and growing forgetting due to dual modifications, JEEP is designed to ensure that updates to distinct regions share the same objectives and are complementary. We rigorously evaluate JEEP by editing up to thousands of facts on various models, i.e., GPT-J (6B) and LLaMA (7B), and addressing diverse editing objectives, i.e., adding factual and counterfactual knowledge. In all tested scenarios, JEEP achieves best performances, validating the effectiveness of the revealings of our probe approach and the designs of our editing method. Our code and data are available at https://github.com/Eric8932/JEEP.
Create and Find Flatness: Building Flat Training Spaces in Advance for Continual Learning
Sep 20, 2023



Catastrophic forgetting remains a critical challenge in the field of continual learning, where neural networks struggle to retain prior knowledge while assimilating new information. Most existing studies emphasize mitigating this issue only when encountering new tasks, overlooking the significance of the pre-task phase. Therefore, we shift the attention to the current task learning stage, presenting a novel framework, C&F (Create and Find Flatness), which builds a flat training space for each task in advance. Specifically, during the learning of the current task, our framework adaptively creates a flat region around the minimum in the loss landscape. Subsequently, it finds the parameters' importance to the current task based on their flatness degrees. When adapting the model to a new task, constraints are applied according to the flatness and a flat space is simultaneously prepared for the impending task. We theoretically demonstrate the consistency between the created and found flatness. In this manner, our framework not only accommodates ample parameter space for learning new tasks but also preserves the preceding knowledge of earlier tasks. Experimental results exhibit C&F's state-of-the-art performance as a standalone continual learning approach and its efficacy as a framework incorporating other methods. Our work is available at https://github.com/Eric8932/Create-and-Find-Flatness.
TencentPretrain: A Scalable and Flexible Toolkit for Pre-training Models of Different Modalities
Dec 13, 2022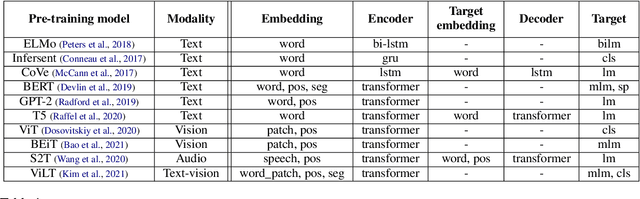
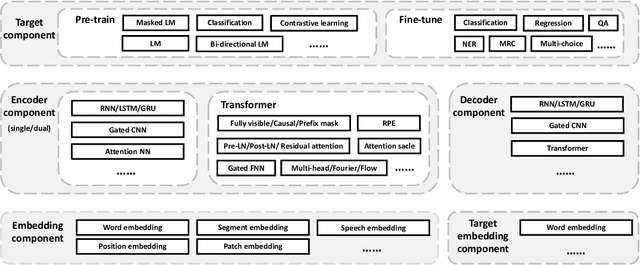
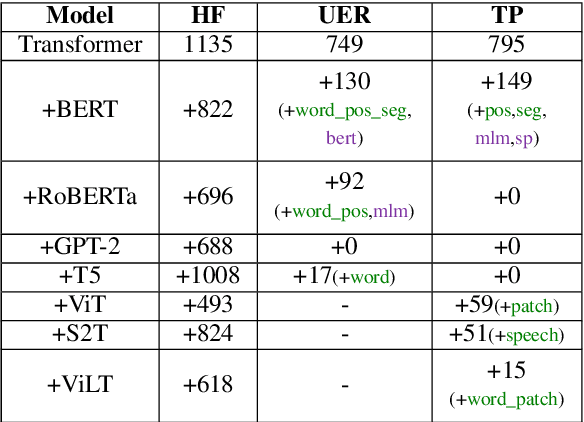
Recently, the success of pre-training in text domain has been fully extended to vision, audio, and cross-modal scenarios. The proposed pre-training models of different modalities are showing a rising trend of homogeneity in their model structures, which brings the opportunity to implement different pre-training models within a uniform framework. In this paper, we present TencentPretrain, a toolkit supporting pre-training models of different modalities. The core feature of TencentPretrain is the modular design. The toolkit uniformly divides pre-training models into 5 components: embedding, encoder, target embedding, decoder, and target. As almost all of common modules are provided in each component, users can choose the desired modules from different components to build a complete pre-training model. The modular design enables users to efficiently reproduce existing pre-training models or build brand-new one. We test the toolkit on text, vision, and audio benchmarks and show that it can match the performance of the original implementations.
A Simple and Effective Method to Improve Zero-Shot Cross-Lingual Transfer Learning
Oct 18, 2022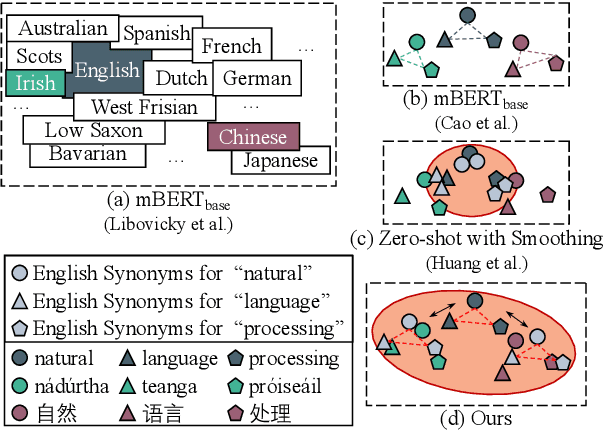
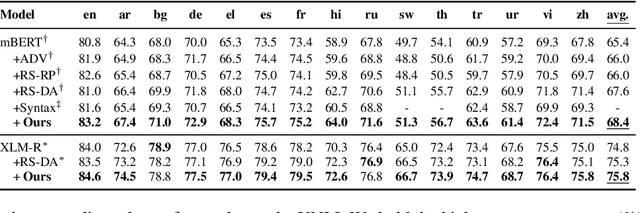
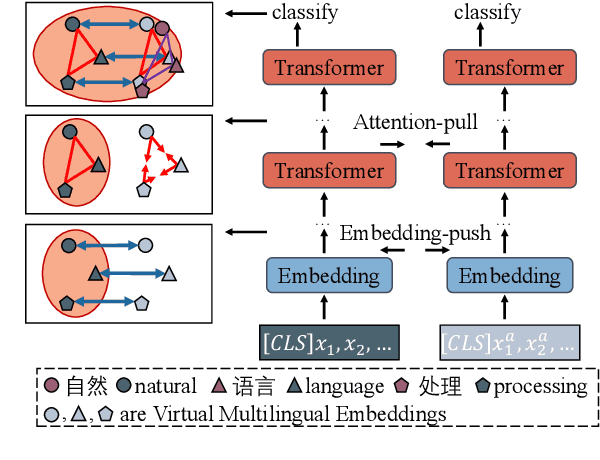
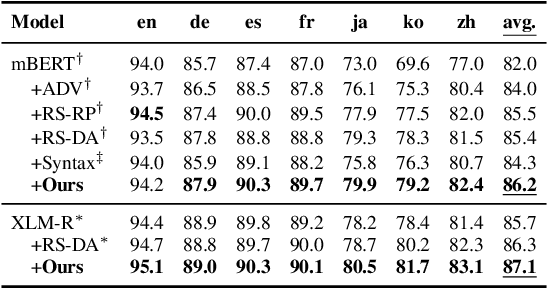
Existing zero-shot cross-lingual transfer methods rely on parallel corpora or bilingual dictionaries, which are expensive and impractical for low-resource languages. To disengage from these dependencies, researchers have explored training multilingual models on English-only resources and transferring them to low-resource languages. However, its effect is limited by the gap between embedding clusters of different languages. To address this issue, we propose Embedding-Push, Attention-Pull, and Robust targets to transfer English embeddings to virtual multilingual embeddings without semantic loss, thereby improving cross-lingual transferability. Experimental results on mBERT and XLM-R demonstrate that our method significantly outperforms previous works on the zero-shot cross-lingual text classification task and can obtain a better multilingual alignment.
Bridging the Gap Between Clean Data Training and Real-World Inference for Spoken Language Understanding
Apr 13, 2021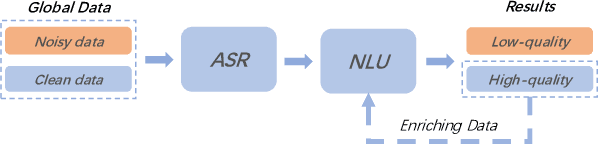
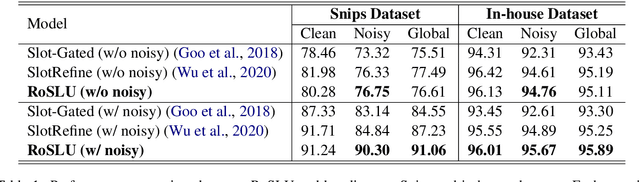
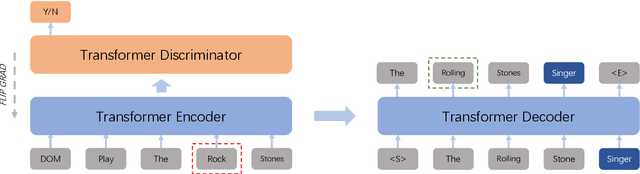
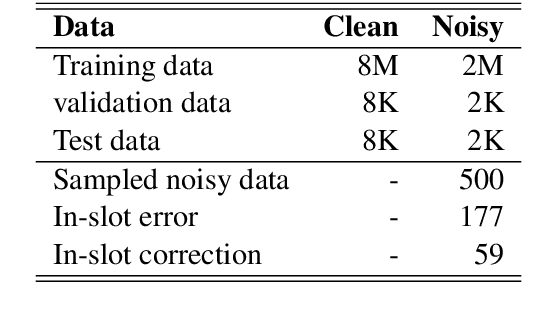
Spoken language understanding (SLU) system usually consists of various pipeline components, where each component heavily relies on the results of its upstream ones. For example, Intent detection (ID), and slot filling (SF) require its upstream automatic speech recognition (ASR) to transform the voice into text. In this case, the upstream perturbations, e.g. ASR errors, environmental noise and careless user speaking, will propagate to the ID and SF models, thus deteriorating the system performance. Therefore, the well-performing SF and ID models are expected to be noise resistant to some extent. However, existing models are trained on clean data, which causes a \textit{gap between clean data training and real-world inference.} To bridge the gap, we propose a method from the perspective of domain adaptation, by which both high- and low-quality samples are embedding into similar vector space. Meanwhile, we design a denoising generation model to reduce the impact of the low-quality samples. Experiments on the widely-used dataset, i.e. Snips, and large scale in-house dataset (10 million training examples) demonstrate that this method not only outperforms the baseline models on real-world (noisy) corpus but also enhances the robustness, that is, it produces high-quality results under a noisy environment. The source code will be released.
Syntax-BERT: Improving Pre-trained Transformers with Syntax Trees
Mar 07, 2021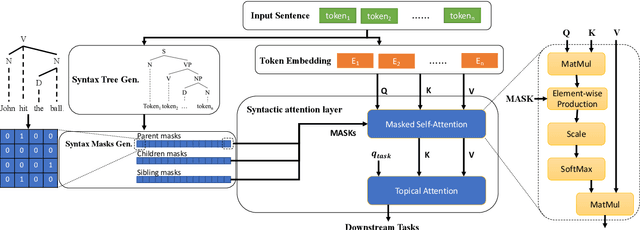

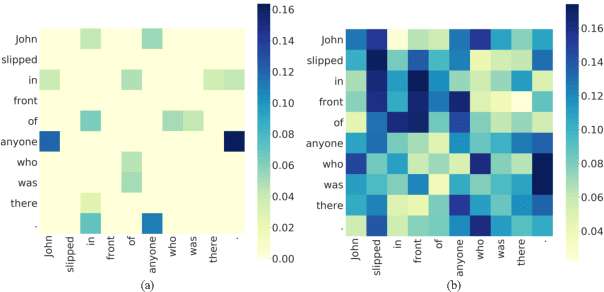
Pre-trained language models like BERT achieve superior performances in various NLP tasks without explicit consideration of syntactic information. Meanwhile, syntactic information has been proved to be crucial for the success of NLP applications. However, how to incorporate the syntax trees effectively and efficiently into pre-trained Transformers is still unsettled. In this paper, we address this problem by proposing a novel framework named Syntax-BERT. This framework works in a plug-and-play mode and is applicable to an arbitrary pre-trained checkpoint based on Transformer architecture. Experiments on various datasets of natural language understanding verify the effectiveness of syntax trees and achieve consistent improvement over multiple pre-trained models, including BERT, RoBERTa, and T5.
AutoADR: Automatic Model Design for Ad Relevance
Oct 14, 2020


Large-scale pre-trained models have attracted extensive attention in the research community and shown promising results on various tasks of natural language processing. However, these pre-trained models are memory and computation intensive, hindering their deployment into industrial online systems like Ad Relevance. Meanwhile, how to design an effective yet efficient model architecture is another challenging problem in online Ad Relevance. Recently, AutoML shed new lights on architecture design, but how to integrate it with pre-trained language models remains unsettled. In this paper, we propose AutoADR (Automatic model design for AD Relevance) -- a novel end-to-end framework to address this challenge, and share our experience to ship these cutting-edge techniques into online Ad Relevance system at Microsoft Bing. Specifically, AutoADR leverages a one-shot neural architecture search algorithm to find a tailored network architecture for Ad Relevance. The search process is simultaneously guided by knowledge distillation from a large pre-trained teacher model (e.g. BERT), while taking the online serving constraints (e.g. memory and latency) into consideration. We add the model designed by AutoADR as a sub-model into the production Ad Relevance model. This additional sub-model improves the Precision-Recall AUC (PR AUC) on top of the original Ad Relevance model by 2.65X of the normalized shipping bar. More importantly, adding this automatically designed sub-model leads to a statistically significant 4.6% Bad-Ad ratio reduction in online A/B testing. This model has been shipped into Microsoft Bing Ad Relevance Production model.
Improving BERT with Self-Supervised Attention
Apr 29, 2020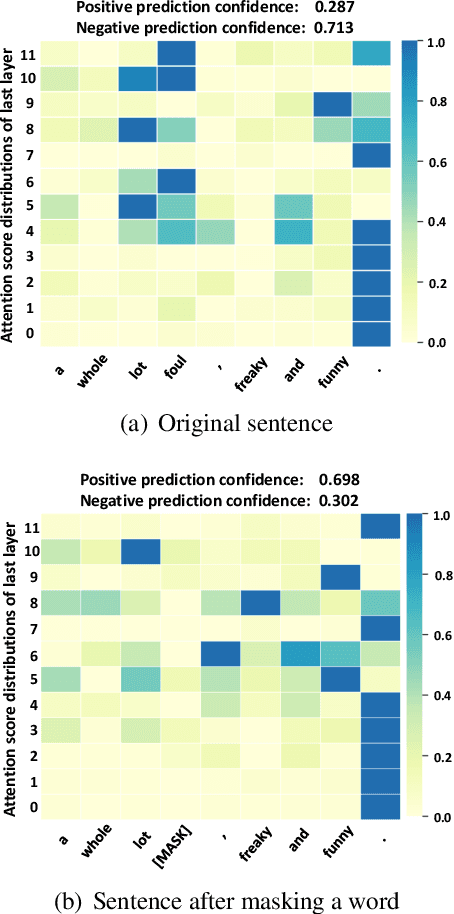
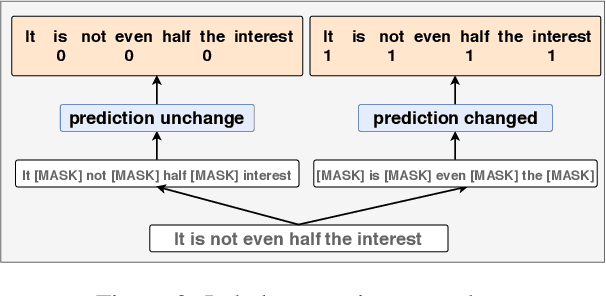

One of the most popular paradigms of applying large, pre-trained NLP models such as BERT is to fine-tune it on a smaller dataset. However, one challenge remains as the fine-tuned model often overfits on smaller datasets. A symptom of this phenomenon is that irrelevant words in the sentences, even when they are obvious to humans, can substantially degrade the performance of these fine-tuned BERT models. In this paper, we propose a novel technique, called Self-Supervised Attention (SSA) to help facilitate this generalization challenge. Specifically, SSA automatically generates weak, token-level attention labels iteratively by "probing" the fine-tuned model from the previous iteration. We investigate two different ways of integrating SSA into BERT and propose a hybrid approach to combine their benefits. Empirically, on a variety of public datasets, we illustrate significant performance improvement using our SSA-enhanced BERT model.