 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Information Seeking Agent Consolidation
Jan 31, 2026Information-seeking agents have emerged as a powerful paradigm for solving knowledge-intensive tasks. Existing information-seeking agents are typically specialized for open web, documents, or local knowledge bases, which constrains scalability and cross-domain generalization. In this work, we investigate how to consolidate heterogeneous information-seeking agents into a single foundation agentic model. We study two complementary consolidation strategies: data-level consolidation, which jointly trains a unified model on a mixture of domain-specific datasets, and parameter-level consolidation, which merges independently trained agent models at the parameter level. Our analysis compares these approaches in terms of performance retention, cross-domain generalization, and interference across information-seeking behaviors. Our results show that data-level consolidation remains a strong and stable baseline, while parameter-level consolidation offers a promising, efficient alternative but suffers from interference and robustness challenges. We further identify key design factors for effective agent consolidation at the parameter level, including fine-grained merging granularity, awareness of task heterogeneity, and principled consensus strategy.
DiffBench Meets DiffAgent: End-to-End LLM-Driven Diffusion Acceleration Code Generation
Jan 06, 2026Diffusion models have achieved remarkable success in image and video generation. However, their inherently multiple step inference process imposes substantial computational overhead, hindering real-world deployment. Accelerating diffusion models is therefore essential, yet determining how to combine multiple model acceleration techniques remains a significant challenge. To address this issue, we introduce a framework driven by large language models (LLMs) for automated acceleration code generation and evaluation. First, we present DiffBench, a comprehensive benchmark that implements a three stage automated evaluation pipeline across diverse diffusion architectures, optimization combinations and deployment scenarios. Second, we propose DiffAgent, an agent that generates optimal acceleration strategies and codes for arbitrary diffusion models. DiffAgent employs a closed-loop workflow in which a planning component and a debugging component iteratively refine the output of a code generation component, while a genetic algorithm extracts performance feedback from the execution environment to guide subsequent code refinements. We provide a detailed explanation of the DiffBench construction and the design principles underlying DiffAgent. Extensive experiments show that DiffBench offers a thorough evaluation of generated codes and that DiffAgent significantly outperforms existing LLMs in producing effective diffusion acceleration strategies.
FedSRD: Sparsify-Reconstruct-Decompose for Communication-Efficient Federated Large Language Models Fine-Tuning
Oct 06, 2025



The current paradigm of training large language models (LLMs) on publicly available Web data is becoming unsustainable, with high-quality data sources in specialized domains nearing exhaustion. Federated Learning (FL) emerges as a practical solution for the next generation of AI on a decentralized Web, enabling privacy-preserving collaborative fine-tuning by leveraging private data distributed across a global client base. While Low-Rank Adaptation (LoRA) is the standard for efficient fine-tuning, its application in federated settings presents a critical challenge: communication overhead remains a significant bottleneck across the Web's heterogeneous network conditions. The structural redundancy within LoRA parameters not only incurs a heavy communication burden but also introduces conflicts when aggregating client updates. To address this, we propose FedSRD, a Sparsify-Reconstruct-Decompose framework designed for communication-efficient FL. We first introduce an importance-aware sparsification method that preserves the structural integrity of LoRA updates to reduce the uploaded parameter count. The server then reconstructs and aggregates these updates in a full-rank space to mitigate conflicts. Finally, it decomposes the global update into a sparse low-rank format for broadcast, ensuring a symmetrically efficient cycle. We also propose an efficient variant, FedSRD-e, to reduce computational overhead. Experimental results on 10 benchmarks demonstrate that our framework significantly reduces communication costs by up to 90\% while even improving model performance on heterogeneous client data.
dFLMoE: Decentralized Federated Learning via Mixture of Experts for Medical Data Analysis
Mar 13, 2025Federated learning has wide applications in the medical field. It enables knowledge sharing among different healthcare institutes while protecting patients' privacy. However, existing federated learning systems are typically centralized, requiring clients to upload client-specific knowledge to a central server for aggregation. This centralized approach would integrate the knowledge from each client into a centralized server, and the knowledge would be already undermined during the centralized integration before it reaches back to each client. Besides, the centralized approach also creates a dependency on the central server, which may affect training stability if the server malfunctions or connections are unstable. To address these issues, we propose a decentralized federated learning framework named dFLMoE. In our framework, clients directly exchange lightweight head models with each other. After exchanging, each client treats both local and received head models as individual experts, and utilizes a client-specific Mixture of Experts (MoE) approach to make collective decisions. This design not only reduces the knowledge damage with client-specific aggregations but also removes the dependency on the central server to enhance the robustness of the framework. We validate our framework on multiple medical tasks, demonstrating that our method evidently outperforms state-of-the-art approaches under both model homogeneity and heterogeneity settings.
FedVCK: Non-IID Robust and Communication-Efficient Federated Learning via Valuable Condensed Knowledge for Medical Image Analysis
Dec 24, 2024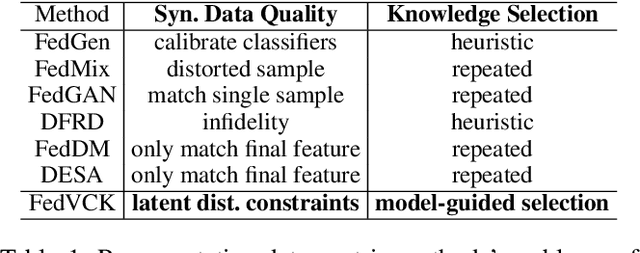
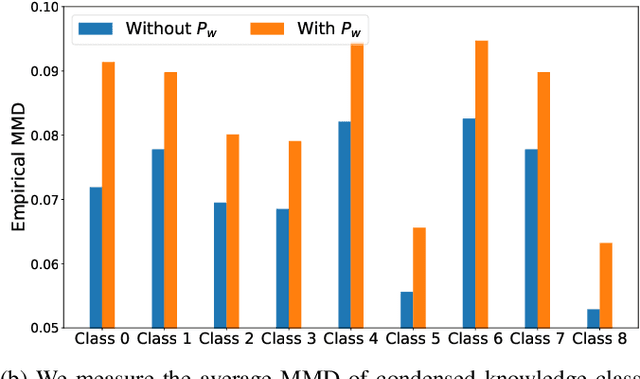
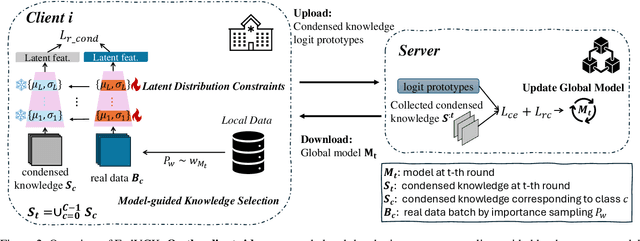
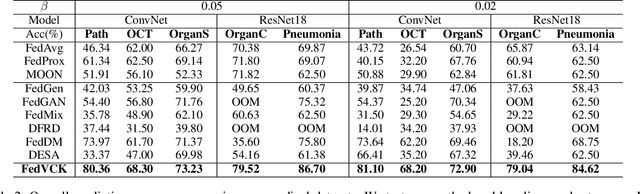
Federated learning has become a promising solution for collaboration among medical institutions. However, data owned by each institution would be highly heterogeneous and the distribution is always non-independent and identical distribution (non-IID), resulting in client drift and unsatisfactory performance. Despite existing federated learning methods attempting to solve the non-IID problems, they still show marginal advantages but rely on frequent communication which would incur high costs and privacy concerns. In this paper, we propose a novel federated learning method: \textbf{Fed}erated learning via \textbf{V}aluable \textbf{C}ondensed \textbf{K}nowledge (FedVCK). We enhance the quality of condensed knowledge and select the most necessary knowledge guided by models, to tackle the non-IID problem within limited communication budgets effectively. Specifically, on the client side, we condense the knowledge of each client into a small dataset and further enhance the condensation procedure with latent distribution constraints, facilitating the effective capture of high-quality knowledge. During each round, we specifically target and condense knowledge that has not been assimilated by the current model, thereby preventing unnecessary repetition of homogeneous knowledge and minimizing the frequency of communications required. On the server side, we propose relational supervised contrastive learning to provide more supervision signals to aid the global model updating. Comprehensive experiments across various medical tasks show that FedVCK can outperform state-of-the-art methods, demonstrating that it's non-IID robust and communication-efficient.
Toward Personalized Federated Node Classification in One-shot Communication
Nov 18, 2024



Federated Graph Learning (FGL) has become a promising paradigm for collaborative training with distributed and private graph data. One-shot Federated Learning (OFL) enables collaboration in a single communication round to largely reduce communication costs and potential security concerns. However, existing OFL methods are not designed for graph data and existing FGL methods are ineffective within one communication round under both data and model heterogeneity. To mitigate this gap, we are the first to propose a one-shot personalized federated graph learning method for node classification, which is also compatible with the Secure Aggregation scheme. We estimate and aggregate the statistics of class-wise feature distribution to generate a global pseudo-graph on the server, which could be used to train a global graph model. Furthermore, We reveal the under-explored problem of existing personalized FGL methods that their personalized models are biased and neglect the ability to generalize to minorities. To achieve better personalization and generalization simultaneously, we propose a two-stage personalized training to adaptively utilize the personal information from local data and global information from the global pseudo-graph. Comprehensive experiments on 8 multi-scale graph datasets under different partitions with various settings demonstrate our superior performance over state-of-the-art baselines.
pFLFE: Cross-silo Personalized Federated Learning via Feature Enhancement on Medical Image Segmentation
Jun 29, 2024



In medical image segmentation, personalized cross-silo federated learning (FL) is becoming popular for utilizing varied data across healthcare settings to overcome data scarcity and privacy concerns. However, existing methods often suffer from client drift, leading to inconsistent performance and delayed training. We propose a new framework, Personalized Federated Learning via Feature Enhancement (pFLFE), designed to mitigate these challenges. pFLFE consists of two main stages: feature enhancement and supervised learning. The first stage improves differentiation between foreground and background features, and the second uses these enhanced features for learning from segmentation masks. We also design an alternative training approach that requires fewer communication rounds without compromising segmentation quality, even with limited communication resources. Through experiments on three medical segmentation tasks, we demonstrate that pFLFE outperforms the state-of-the-art methods.
MH-pFLGB: Model Heterogeneous personalized Federated Learning via Global Bypass for Medical Image Analysis
Jun 29, 2024In the evolving application of medical artificial intelligence, federated learning is notable for its ability to protect training data privacy. Federated learning facilitates collaborative model development without the need to share local data from healthcare institutions. Yet, the statistical and system heterogeneity among these institutions poses substantial challenges, which affects the effectiveness of federated learning and hampers the exchange of information between clients. To address these issues, we introduce a novel approach, MH-pFLGB, which employs a global bypass strategy to mitigate the reliance on public datasets and navigate the complexities of non-IID data distributions. Our method enhances traditional federated learning by integrating a global bypass model, which would share the information among the clients, but also serves as part of the network to enhance the performance on each client. Additionally, MH-pFLGB provides a feature fusion module to better combine the local and global features. We validate \model{}'s effectiveness and adaptability through extensive testing on different medical tasks, demonstrating superior performance compared to existing state-of-the-art methods.
MH-pFLID: Model Heterogeneous personalized Federated Learning via Injection and Distillation for Medical Data Analysis
May 10, 2024



Federated learning is widely used in medical applications for training global models without needing local data access. However, varying computational capabilities and network architectures (system heterogeneity), across clients pose significant challenges in effectively aggregating information from non-independently and identically distributed (non-IID) data. Current federated learning methods using knowledge distillation require public datasets, raising privacy and data collection issues. Additionally, these datasets require additional local computing and storage resources, which is a burden for medical institutions with limited hardware conditions. In this paper, we introduce a novel federated learning paradigm, named Model Heterogeneous personalized Federated Learning via Injection and Distillation (MH-pFLID). Our framework leverages a lightweight messenger model that carries concentrated information to collect the information from each client. We also develop a set of receiver and transmitter modules to receive and send information from the messenger model, so that the information could be injected and distilled with efficiency.
Learning to Check: Unleashing Potentials for Self-Correction in Large Language Models
Feb 23, 2024



Large language models (LLMs) have made significant strides in reasoning capabilities, with ongoing efforts to refine their reasoning through self-correction. However, recent studies suggest that self-correction can be limited or even counterproductive without external accurate knowledge, raising questions about the limits and effectiveness of self-correction. In this paper, we aim to enhance LLM's self-checking capabilities by meticulously designing training data, thereby improving the accuracy of self-correction. We conduct a detailed analysis of error types in mathematical reasoning and develop a tailored prompt, termed "Step CoT Check". Then we construct a checking-correction dataset for training models. After integrating the original CoT data and checking-correction data for training, we observe that models could improve their self-checking capabilities, thereby enhancing their self-correction capacity and eliminating the need for external feedback or ground truth labels to ascertain the endpoint of correction. We compare the performance of models fine-tuned with the "Step CoT Check" prompt against those refined using other promps within the context of checking-correction data. The "Step CoT Check" outperforms the other two check formats in model with lager parameters, providing more precise feedback thus achieving a higher rate of correctness. For reproducibility, all the datasets and codes are provided in https://github.com/bammt/Learn-to-check.