 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBaguan-TS: A Sequence-Native In-Context Learning Model for Time Series Forecasting with Covariates
Mar 18, 2026Transformers enable in-context learning (ICL) for rapid, gradient-free adaptation in time series forecasting, yet most ICL-style approaches rely on tabularized, hand-crafted features, while end-to-end sequence models lack inference-time adaptation. We bridge this gap with a unified framework, Baguan-TS, which integrates the raw-sequence representation learning with ICL, instantiated by a 3D Transformer that attends jointly over temporal, variable, and context axes. To make this high-capacity model practical, we tackle two key hurdles: (i) calibration and training stability, improved with a feature-agnostic, target-space retrieval-based local calibration; and (ii) output oversmoothing, mitigated via context-overfitting strategy. On public benchmark with covariates, Baguan-TS consistently outperforms established baselines, achieving the highest win rate and significant reductions in both point and probabilistic forecasting metrics. Further evaluations across diverse real-world energy datasets demonstrate its robustness, yielding substantial improvements.
MH-pFLGB: Model Heterogeneous personalized Federated Learning via Global Bypass for Medical Image Analysis
Jun 29, 2024In the evolving application of medical artificial intelligence, federated learning is notable for its ability to protect training data privacy. Federated learning facilitates collaborative model development without the need to share local data from healthcare institutions. Yet, the statistical and system heterogeneity among these institutions poses substantial challenges, which affects the effectiveness of federated learning and hampers the exchange of information between clients. To address these issues, we introduce a novel approach, MH-pFLGB, which employs a global bypass strategy to mitigate the reliance on public datasets and navigate the complexities of non-IID data distributions. Our method enhances traditional federated learning by integrating a global bypass model, which would share the information among the clients, but also serves as part of the network to enhance the performance on each client. Additionally, MH-pFLGB provides a feature fusion module to better combine the local and global features. We validate \model{}'s effectiveness and adaptability through extensive testing on different medical tasks, demonstrating superior performance compared to existing state-of-the-art methods.
Learning Scene-specific Object Detectors Based on a Generative-Discriminative Model with Minimal Supervision
Mar 13, 2018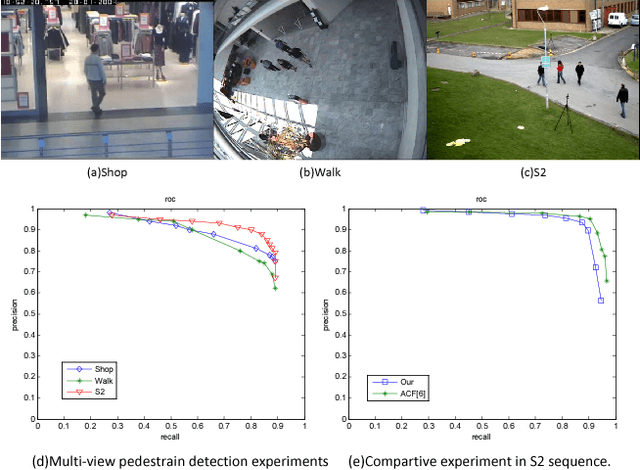
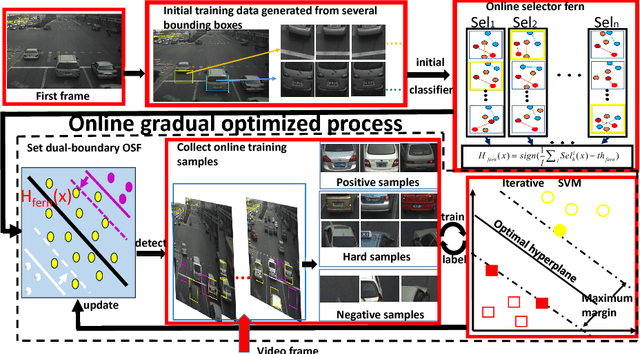

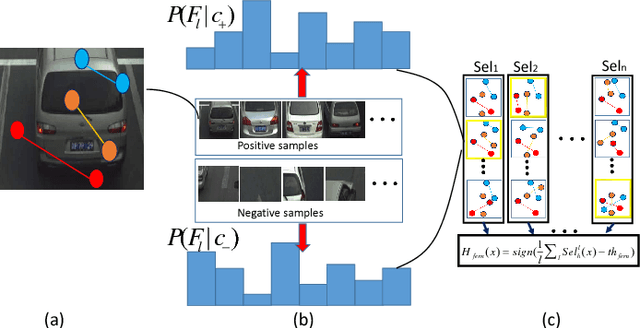
One object class may show large variations due to diverse illuminations, backgrounds and camera viewpoints. Traditional object detection methods often perform worse under unconstrained video environments. To address this problem, many modern approaches model deep hierarchical appearance representations for object detection. Most of these methods require a timeconsuming training process on large manual labelling sample set. In this paper, the proposed framework takes a remarkably different direction to resolve the multi-scene detection problem in a bottom-up fashion. First, a scene-specific objector is obtained from a fully autonomous learning process triggered by marking several bounding boxes around the object in the first video frame via a mouse. Here the human labeled training data or a generic detector are not needed. Second, this learning process is conveniently replicated many times in different surveillance scenes and results in particular detectors under various camera viewpoints. Thus, the proposed framework can be employed in multi-scene object detection applications with minimal supervision. Obviously, the initial scene-specific detector, initialized by several bounding boxes, exhibits poor detection performance and is difficult to improve with traditional online learning algorithm. Consequently, we propose Generative-Discriminative model to partition detection response space and assign each partition an individual descriptor that progressively achieves high classification accuracy. A novel online gradual optimized process is proposed to optimize the Generative-Discriminative model and focus on the hard samples.Experimental results on six video datasets show our approach achieves comparable performance to robust supervised methods, and outperforms the state of the art self-learning methods under varying imaging conditions.