 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlasticine: A Traceable Diffusion Model for Medical Image Translation
Dec 20, 2025Domain gaps arising from variations in imaging devices and population distributions pose significant challenges for machine learning in medical image analysis. Existing image-to-image translation methods primarily aim to learn mappings between domains, often generating diverse synthetic data with variations in anatomical scale and shape, but they usually overlook spatial correspondence during the translation process. For clinical applications, traceability, defined as the ability to provide pixel-level correspondences between original and translated images, is equally important. This property enhances clinical interpretability but has been largely overlooked in previous approaches. To address this gap, we propose Plasticine, which is, to the best of our knowledge, the first end-to-end image-to-image translation framework explicitly designed with traceability as a core objective. Our method combines intensity translation and spatial transformation within a denoising diffusion framework. This design enables the generation of synthetic images with interpretable intensity transitions and spatially coherent deformations, supporting pixel-wise traceability throughout the translation process.
Heterogeneous Complementary Distillation
Nov 14, 2025Knowledge distillation (KD)transfers the dark knowledge from a complex teacher to a compact student. However, heterogeneous architecture distillation, such as Vision Transformer (ViT) to ResNet18, faces challenges due to differences in spatial feature representations.Traditional KD methods are mostly designed for homogeneous architectures and hence struggle to effectively address the disparity. Although heterogeneous KD approaches have been developed recently to solve these issues, they often incur high computational costs and complex designs, or overly rely on logit alignment, which limits their ability to leverage the complementary features. To overcome these limitations, we propose Heterogeneous Complementary Distillation (HCD),a simple yet effective framework that integrates complementary teacher and student features to align representations in shared logits.These logits are decomposed and constrained to facilitate diverse knowledge transfer to the student. Specifically, HCD processes the student's intermediate features through convolutional projector and adaptive pooling, concatenates them with teacher's feature from the penultimate layer and then maps them via the Complementary Feature Mapper (CFM) module, comprising fully connected layer,to produce shared logits.We further introduce Sub-logit Decoupled Distillation (SDD) that partitions the shared logits into n sub-logits, which are fused with teacher's logits to rectify classification.To ensure sub-logit diversity and reduce redundant knowledge transfer, we propose an Orthogonality Loss (OL).By preserving student-specific strengths and leveraging teacher knowledge,HCD enhances robustness and generalization in students.Extensive experiments on the CIFAR-100, Fine-grained (e.g., CUB200)and ImageNet-1K datasets demonstrate that HCD outperforms state-of-the-art KD methods,establishing it as an effective solution for heterogeneous KD.
Integrating SAM Supervision for 3D Weakly Supervised Point Cloud Segmentation
Aug 27, 2025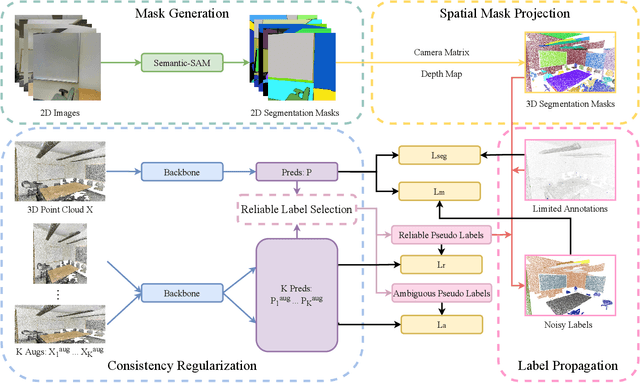
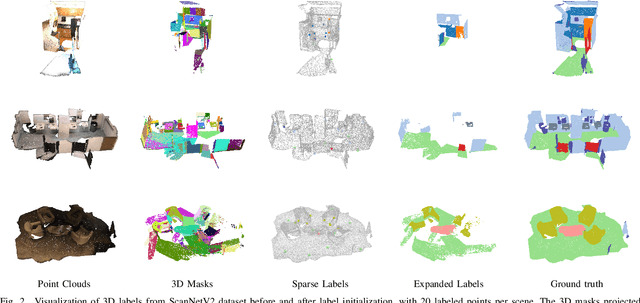


Current methods for 3D semantic segmentation propose training models with limited annotations to address the difficulty of annotating large, irregular, and unordered 3D point cloud data. They usually focus on the 3D domain only, without leveraging the complementary nature of 2D and 3D data. Besides, some methods extend original labels or generate pseudo labels to guide the training, but they often fail to fully use these labels or address the noise within them. Meanwhile, the emergence of comprehensive and adaptable foundation models has offered effective solutions for segmenting 2D data. Leveraging this advancement, we present a novel approach that maximizes the utility of sparsely available 3D annotations by incorporating segmentation masks generated by 2D foundation models. We further propagate the 2D segmentation masks into the 3D space by establishing geometric correspondences between 3D scenes and 2D views. We extend the highly sparse annotations to encompass the areas delineated by 3D masks, thereby substantially augmenting the pool of available labels. Furthermore, we apply confidence- and uncertainty-based consistency regularization on augmentations of the 3D point cloud and select the reliable pseudo labels, which are further spread on the 3D masks to generate more labels. This innovative strategy bridges the gap between limited 3D annotations and the powerful capabilities of 2D foundation models, ultimately improving the performance of 3D weakly supervised segmentation.
Modality-Aware Feature Matching: A Comprehensive Review of Single- and Cross-Modality Techniques
Jul 30, 2025



Feature matching is a cornerstone task in computer vision, essential for applications such as image retrieval, stereo matching, 3D reconstruction, and SLAM. This survey comprehensively reviews modality-based feature matching, exploring traditional handcrafted methods and emphasizing contemporary deep learning approaches across various modalities, including RGB images, depth images, 3D point clouds, LiDAR scans, medical images, and vision-language interactions. Traditional methods, leveraging detectors like Harris corners and descriptors such as SIFT and ORB, demonstrate robustness under moderate intra-modality variations but struggle with significant modality gaps. Contemporary deep learning-based methods, exemplified by detector-free strategies like CNN-based SuperPoint and transformer-based LoFTR, substantially improve robustness and adaptability across modalities. We highlight modality-aware advancements, such as geometric and depth-specific descriptors for depth images, sparse and dense learning methods for 3D point clouds, attention-enhanced neural networks for LiDAR scans, and specialized solutions like the MIND descriptor for complex medical image matching. Cross-modal applications, particularly in medical image registration and vision-language tasks, underscore the evolution of feature matching to handle increasingly diverse data interactions.
HMAD: Advancing E2E Driving with Anchored Offset Proposals and Simulation-Supervised Multi-target Scoring
May 29, 2025End-to-end autonomous driving faces persistent challenges in both generating diverse, rule-compliant trajectories and robustly selecting the optimal path from these options via learned, multi-faceted evaluation. To address these challenges, we introduce HMAD, a framework integrating a distinctive Bird's-Eye-View (BEV) based trajectory proposal mechanism with learned multi-criteria scoring. HMAD leverages BEVFormer and employs learnable anchored queries, initialized from a trajectory dictionary and refined via iterative offset decoding (inspired by DiffusionDrive), to produce numerous diverse and stable candidate trajectories. A key innovation, our simulation-supervised scorer module, then evaluates these proposals against critical metrics including no at-fault collisions, drivable area compliance, comfortableness, and overall driving quality (i.e., extended PDM score). Demonstrating its efficacy, HMAD achieves a 44.5% driving score on the CVPR 2025 private test set. This work highlights the benefits of effectively decoupling robust trajectory generation from comprehensive, safety-aware learned scoring for advanced autonomous driving.
LiftFeat: 3D Geometry-Aware Local Feature Matching
May 06, 2025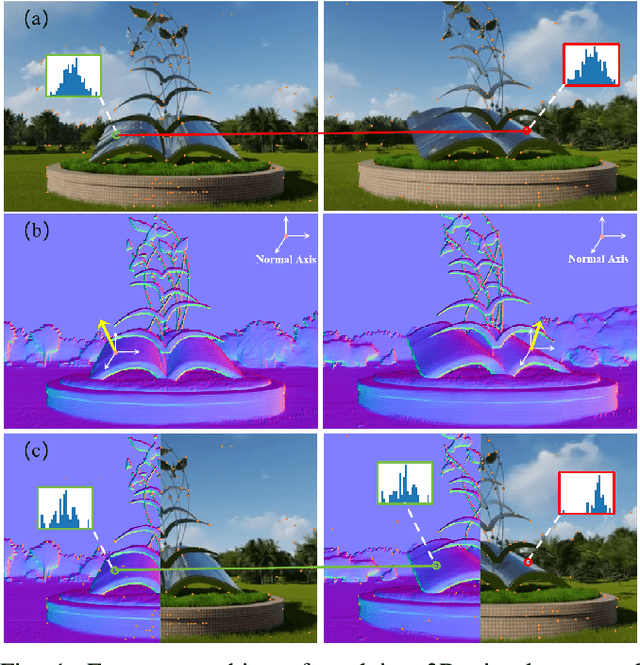
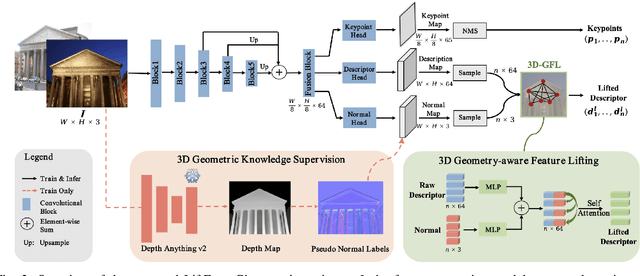

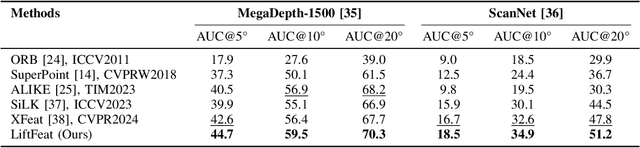
Robust and efficient local feature matching plays a crucial role in applications such as SLAM and visual localization for robotics. Despite great progress, it is still very challenging to extract robust and discriminative visual features in scenarios with drastic lighting changes, low texture areas, or repetitive patterns. In this paper, we propose a new lightweight network called \textit{LiftFeat}, which lifts the robustness of raw descriptor by aggregating 3D geometric feature. Specifically, we first adopt a pre-trained monocular depth estimation model to generate pseudo surface normal label, supervising the extraction of 3D geometric feature in terms of predicted surface normal. We then design a 3D geometry-aware feature lifting module to fuse surface normal feature with raw 2D descriptor feature. Integrating such 3D geometric feature enhances the discriminative ability of 2D feature description in extreme conditions. Extensive experimental results on relative pose estimation, homography estimation, and visual localization tasks, demonstrate that our LiftFeat outperforms some lightweight state-of-the-art methods. Code will be released at : https://github.com/lyp-deeplearning/LiftFeat.
The Tenth NTIRE 2025 Image Denoising Challenge Report
Apr 16, 2025



This paper presents an overview of the NTIRE 2025 Image Denoising Challenge ({\sigma} = 50), highlighting the proposed methodologies and corresponding results. The primary objective is to develop a network architecture capable of achieving high-quality denoising performance, quantitatively evaluated using PSNR, without constraints on computational complexity or model size. The task assumes independent additive white Gaussian noise (AWGN) with a fixed noise level of 50. A total of 290 participants registered for the challenge, with 20 teams successfully submitting valid results, providing insights into the current state-of-the-art in image denoising.
UCS: A Universal Model for Curvilinear Structure Segmentation
Apr 05, 2025



Curvilinear structure segmentation (CSS) is vital in various domains, including medical imaging, landscape analysis, industrial surface inspection, and plant analysis. While existing methods achieve high performance within specific domains, their generalizability is limited. On the other hand, large-scale models such as Segment Anything Model (SAM) exhibit strong generalization but are not optimized for curvilinear structures. Existing adaptations of SAM primarily focus on general object segmentation and lack specialized design for CSS tasks. To bridge this gap, we propose the Universal Curvilinear structure Segmentation (\textit{UCS}) model, which adapts SAM to CSS tasks while enhancing its generalization. \textit{UCS} features a novel encoder architecture integrating a pretrained SAM encoder with two innovations: a Sparse Adapter, strategically inserted to inherit the pre-trained SAM encoder's generalization capability while minimizing the number of fine-tuning parameters, and a Prompt Generation module, which leverages Fast Fourier Transform with a high-pass filter to generate curve-specific prompts. Furthermore, the \textit{UCS} incorporates a mask decoder that eliminates reliance on manual interaction through a dual-compression module: a Hierarchical Feature Compression module, which aggregates the outputs of the sampled encoder to enhance detail preservation, and a Guidance Feature Compression module, which extracts and compresses image-driven guidance features. Evaluated on a comprehensive multi-domain dataset, including an in-house dataset covering eight natural curvilinear structures, \textit{UCS} demonstrates state-of-the-art generalization and open-set segmentation performance across medical, engineering, natural, and plant imagery, establishing a new benchmark for universal CSS.
Beyond Existance: Fulfill 3D Reconstructed Scenes with Pseudo Details
Mar 06, 2025The emergence of 3D Gaussian Splatting (3D-GS) has significantly advanced 3D reconstruction by providing high fidelity and fast training speeds across various scenarios. While recent efforts have mainly focused on improving model structures to compress data volume or reduce artifacts during zoom-in and zoom-out operations, they often overlook an underlying issue: training sampling deficiency. In zoomed-in views, Gaussian primitives can appear unregulated and distorted due to their dilation limitations and the insufficient availability of scale-specific training samples. Consequently, incorporating pseudo-details that ensure the completeness and alignment of the scene becomes essential. In this paper, we introduce a new training method that integrates diffusion models and multi-scale training using pseudo-ground-truth data. This approach not only notably mitigates the dilation and zoomed-in artifacts but also enriches reconstructed scenes with precise details out of existing scenarios. Our method achieves state-of-the-art performance across various benchmarks and extends the capabilities of 3D reconstruction beyond training datasets.
MIFNet: Learning Modality-Invariant Features for Generalizable Multimodal Image Matching
Jan 20, 2025



Many keypoint detection and description methods have been proposed for image matching or registration. While these methods demonstrate promising performance for single-modality image matching, they often struggle with multimodal data because the descriptors trained on single-modality data tend to lack robustness against the non-linear variations present in multimodal data. Extending such methods to multimodal image matching often requires well-aligned multimodal data to learn modality-invariant descriptors. However, acquiring such data is often costly and impractical in many real-world scenarios. To address this challenge, we propose a modality-invariant feature learning network (MIFNet) to compute modality-invariant features for keypoint descriptions in multimodal image matching using only single-modality training data. Specifically, we propose a novel latent feature aggregation module and a cumulative hybrid aggregation module to enhance the base keypoint descriptors trained on single-modality data by leveraging pre-trained features from Stable Diffusion models. We validate our method with recent keypoint detection and description methods in three multimodal retinal image datasets (CF-FA, CF-OCT, EMA-OCTA) and two remote sensing datasets (Optical-SAR and Optical-NIR). Extensive experiments demonstrate that the proposed MIFNet is able to learn modality-invariant feature for multimodal image matching without accessing the targeted modality and has good zero-shot generalization ability. The source code will be made publicly available.