 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Sampling-Gaussian for stereo matching
Oct 09, 2024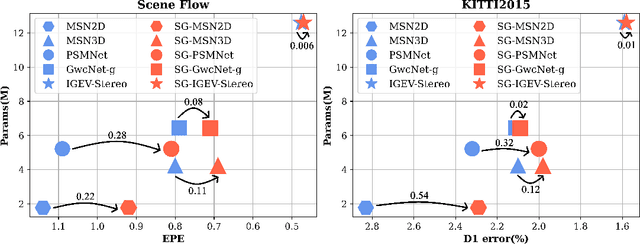

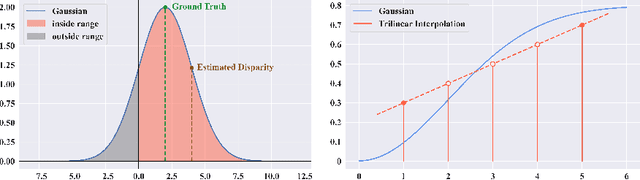
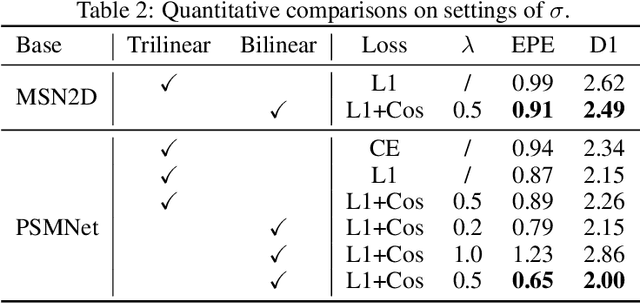
The soft-argmax operation is widely adopted in neural network-based stereo matching methods to enable differentiable regression of disparity. However, network trained with soft-argmax is prone to being multimodal due to absence of explicit constraint to the shape of the probability distribution. Previous methods leverages Laplacian distribution and cross-entropy for training but failed to effectively improve the accuracy and even compromises the efficiency of the network. In this paper, we conduct a detailed analysis of the previous distribution-based methods and propose a novel supervision method for stereo matching, Sampling-Gaussian. We sample from the Gaussian distribution for supervision. Moreover, we interpret the training as minimizing the distance in vector space and propose a combined loss of L1 loss and cosine similarity loss. Additionally, we leveraged bilinear interpolation to upsample the cost volume. Our method can be directly applied to any soft-argmax-based stereo matching method without a reduction in efficiency. We have conducted comprehensive experiments to demonstrate the superior performance of our Sampling-Gaussian. The experimental results prove that we have achieved better accuracy on five baseline methods and two datasets. Our method is easy to implement, and the code is available online.
NoMAD-Attention: Efficient LLM Inference on CPUs Through Multiply-add-free Attention
Mar 02, 2024



Large language model inference on Central Processing Units (CPU) is challenging due to the vast quantities of expensive Multiply-Add (MAD) matrix operations in the attention computations. In this paper, we argue that there is a rare gem in modern CPUs, Single-Instruction-Multiple-Data (SIMD) registers, which allow for ultra-low-latency lookups in batch. We leverage this unique capability of CPUs to propose NoMAD-Attention, an efficient attention algorithm that replaces MAD operations with in-register lookups. Through hardware-aware algorithmic designs, NoMAD-Attention achieves the computation of attention scores using repeated fast accesses to SIMD registers despite their highly limited sizes. Moreover, NoMAD-Attention works with pre-trained attention-based LLMs without model finetuning. Empirical evaluations demonstrate that NoMAD-Attention maintains the quality of the original LLMs well, and speeds up the 4-bit quantized LLaMA-7B-based model by up to 2$\times$ at 16k context length. Our results are reproducible at https://github.com/tonyzhang617/nomad-dist.