 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn-Device Diffusion Transformer Policy for Efficient Robot Manipulation
Aug 01, 2025Diffusion Policies have significantly advanced robotic manipulation tasks via imitation learning, but their application on resource-constrained mobile platforms remains challenging due to computational inefficiency and extensive memory footprint. In this paper, we propose LightDP, a novel framework specifically designed to accelerate Diffusion Policies for real-time deployment on mobile devices. LightDP addresses the computational bottleneck through two core strategies: network compression of the denoising modules and reduction of the required sampling steps. We first conduct an extensive computational analysis on existing Diffusion Policy architectures, identifying the denoising network as the primary contributor to latency. To overcome performance degradation typically associated with conventional pruning methods, we introduce a unified pruning and retraining pipeline, optimizing the model's post-pruning recoverability explicitly. Furthermore, we combine pruning techniques with consistency distillation to effectively reduce sampling steps while maintaining action prediction accuracy. Experimental evaluations on the standard datasets, \ie, PushT, Robomimic, CALVIN, and LIBERO, demonstrate that LightDP achieves real-time action prediction on mobile devices with competitive performance, marking an important step toward practical deployment of diffusion-based policies in resource-limited environments. Extensive real-world experiments also show the proposed LightDP can achieve performance comparable to state-of-the-art Diffusion Policies.
The Sampling-Gaussian for stereo matching
Oct 09, 2024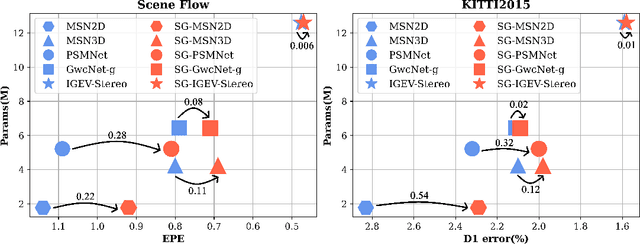

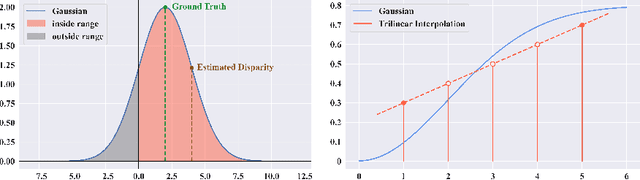
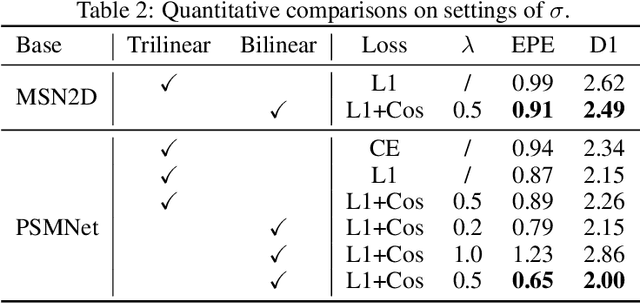
The soft-argmax operation is widely adopted in neural network-based stereo matching methods to enable differentiable regression of disparity. However, network trained with soft-argmax is prone to being multimodal due to absence of explicit constraint to the shape of the probability distribution. Previous methods leverages Laplacian distribution and cross-entropy for training but failed to effectively improve the accuracy and even compromises the efficiency of the network. In this paper, we conduct a detailed analysis of the previous distribution-based methods and propose a novel supervision method for stereo matching, Sampling-Gaussian. We sample from the Gaussian distribution for supervision. Moreover, we interpret the training as minimizing the distance in vector space and propose a combined loss of L1 loss and cosine similarity loss. Additionally, we leveraged bilinear interpolation to upsample the cost volume. Our method can be directly applied to any soft-argmax-based stereo matching method without a reduction in efficiency. We have conducted comprehensive experiments to demonstrate the superior performance of our Sampling-Gaussian. The experimental results prove that we have achieved better accuracy on five baseline methods and two datasets. Our method is easy to implement, and the code is available online.
SpeechFormer++: A Hierarchical Efficient Framework for Paralinguistic Speech Processing
Feb 27, 2023



Paralinguistic speech processing is important in addressing many issues, such as sentiment and neurocognitive disorder analyses. Recently, Transformer has achieved remarkable success in the natural language processing field and has demonstrated its adaptation to speech. However, previous works on Transformer in the speech field have not incorporated the properties of speech, leaving the full potential of Transformer unexplored. In this paper, we consider the characteristics of speech and propose a general structure-based framework, called SpeechFormer++, for paralinguistic speech processing. More concretely, following the component relationship in the speech signal, we design a unit encoder to model the intra- and inter-unit information (i.e., frames, phones, and words) efficiently. According to the hierarchical relationship, we utilize merging blocks to generate features at different granularities, which is consistent with the structural pattern in the speech signal. Moreover, a word encoder is introduced to integrate word-grained features into each unit encoder, which effectively balances fine-grained and coarse-grained information. SpeechFormer++ is evaluated on the speech emotion recognition (IEMOCAP & MELD), depression classification (DAIC-WOZ) and Alzheimer's disease detection (Pitt) tasks. The results show that SpeechFormer++ outperforms the standard Transformer while greatly reducing the computational cost. Furthermore, it delivers superior results compared to the state-of-the-art approaches.
DST: Deformable Speech Transformer for Emotion Recognition
Feb 27, 2023Enabled by multi-head self-attention, Transformer has exhibited remarkable results in speech emotion recognition (SER). Compared to the original full attention mechanism, window-based attention is more effective in learning fine-grained features while greatly reducing model redundancy. However, emotional cues are present in a multi-granularity manner such that the pre-defined fixed window can severely degrade the model flexibility. In addition, it is difficult to obtain the optimal window settings manually. In this paper, we propose a Deformable Speech Transformer, named DST, for SER task. DST determines the usage of window sizes conditioned on input speech via a light-weight decision network. Meanwhile, data-dependent offsets derived from acoustic features are utilized to adjust the positions of the attention windows, allowing DST to adaptively discover and attend to the valuable information embedded in the speech. Extensive experiments on IEMOCAP and MELD demonstrate the superiority of DST.
Context Sensing Attention Network for Video-based Person Re-identification
Jul 06, 2022

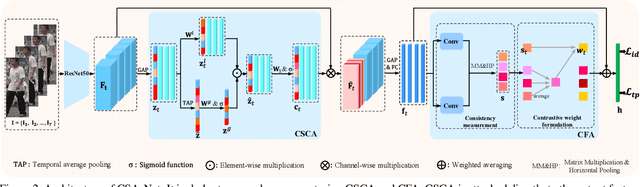
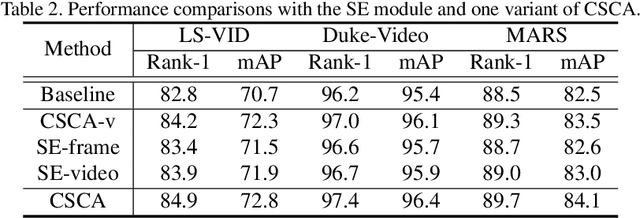
Video-based person re-identification (ReID) is challenging due to the presence of various interferences in video frames. Recent approaches handle this problem using temporal aggregation strategies. In this work, we propose a novel Context Sensing Attention Network (CSA-Net), which improves both the frame feature extraction and temporal aggregation steps. First, we introduce the Context Sensing Channel Attention (CSCA) module, which emphasizes responses from informative channels for each frame. These informative channels are identified with reference not only to each individual frame, but also to the content of the entire sequence. Therefore, CSCA explores both the individuality of each frame and the global context of the sequence. Second, we propose the Contrastive Feature Aggregation (CFA) module, which predicts frame weights for temporal aggregation. Here, the weight for each frame is determined in a contrastive manner: i.e., not only by the quality of each individual frame, but also by the average quality of the other frames in a sequence. Therefore, it effectively promotes the contribution of relatively good frames. Extensive experimental results on four datasets show that CSA-Net consistently achieves state-of-the-art performance.
CPED: A Large-Scale Chinese Personalized and Emotional Dialogue Dataset for Conversational AI
May 29, 2022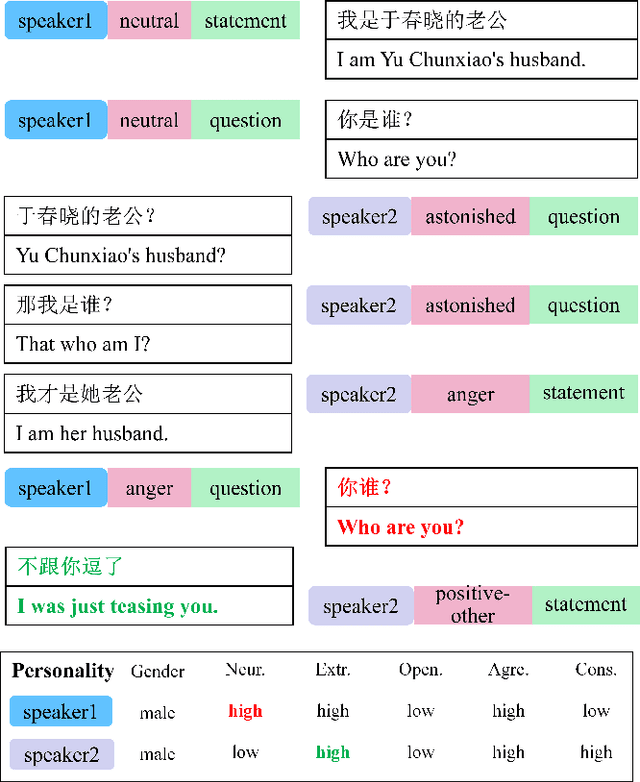

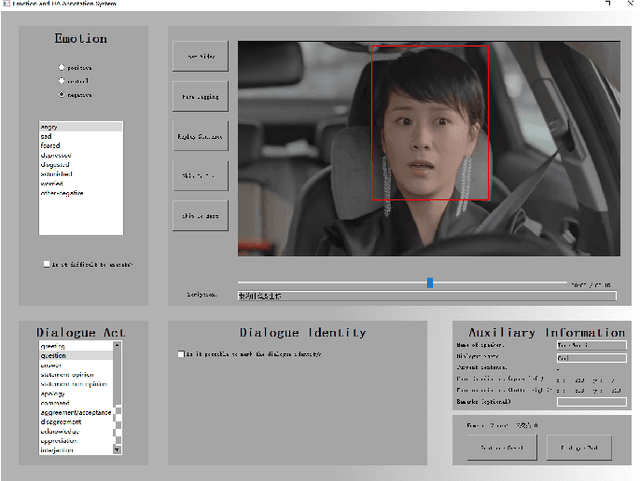
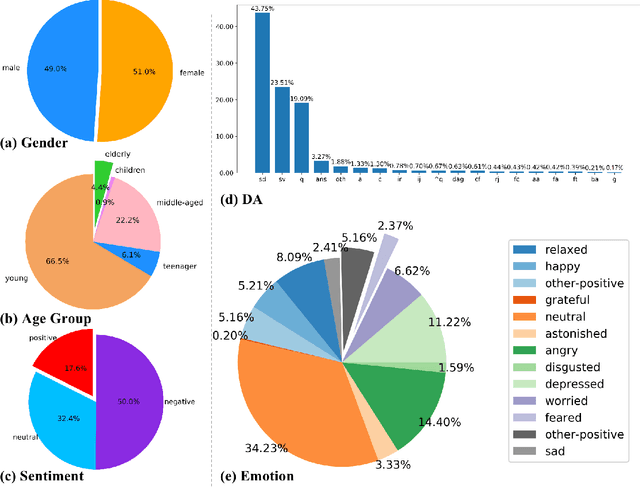
Human language expression is based on the subjective construal of the situation instead of the objective truth conditions, which means that speakers' personalities and emotions after cognitive processing have an important influence on conversation. However, most existing datasets for conversational AI ignore human personalities and emotions, or only consider part of them. It's difficult for dialogue systems to understand speakers' personalities and emotions although large-scale pre-training language models have been widely used. In order to consider both personalities and emotions in the process of conversation generation, we propose CPED, a large-scale Chinese personalized and emotional dialogue dataset, which consists of multi-source knowledge related to empathy and personal characteristic. These knowledge covers gender, Big Five personality traits, 13 emotions, 19 dialogue acts and 10 scenes. CPED contains more than 12K dialogues of 392 speakers from 40 TV shows. We release the textual dataset with audio features and video features according to the copyright claims, privacy issues, terms of service of video platforms. We provide detailed description of the CPED construction process and introduce three tasks for conversational AI, including personality recognition, emotion recognition in conversations as well as personalized and emotional conversation generation. Finally, we provide baseline systems for these tasks and consider the function of speakers' personalities and emotions on conversation. Our motivation is to propose a dataset to be widely adopted by the NLP community as a new open benchmark for conversational AI research. The full dataset is available at https://github.com/scutcyr/CPED.
SpeechFormer: A Hierarchical Efficient Framework Incorporating the Characteristics of Speech
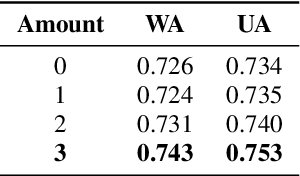
Mar 10, 2022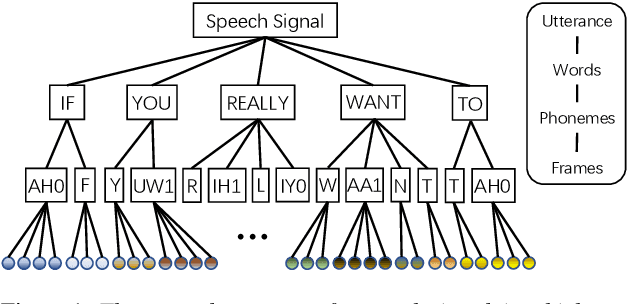

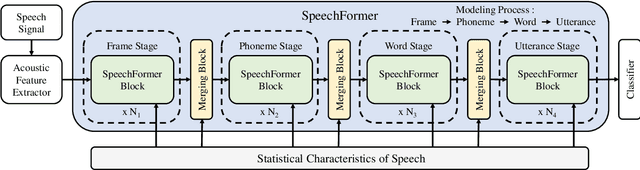

Transformer has obtained promising results on cognitive speech signal processing field, which is of interest in various applications ranging from emotion to neurocognitive disorder analysis. However, most works treat speech signal as a whole, leading to the neglect of the pronunciation structure that is unique to speech and reflects the cognitive process. Meanwhile, Transformer has heavy computational burden due to its full attention operation. In this paper, a hierarchical efficient framework, called SpeechFormer, which considers the structural characteristics of speech, is proposed and can be served as a general-purpose backbone for cognitive speech signal processing. The proposed SpeechFormer consists of frame, phoneme, word and utterance stages in succession, each performing a neighboring attention according to the structural pattern of speech with high computational efficiency. SpeechFormer is evaluated on speech emotion recognition (IEMOCAP & MELD) and neurocognitive disorder detection (Pitt & DAIC-WOZ) tasks, and the results show that SpeechFormer outperforms the standard Transformer-based framework while greatly reducing the computational cost. Furthermore, our SpeechFormer achieves comparable results to the state-of-the-art approaches.
Key-Sparse Transformer with Cascaded Cross-Attention Block for Multimodal Speech Emotion Recognition
Jun 22, 2021
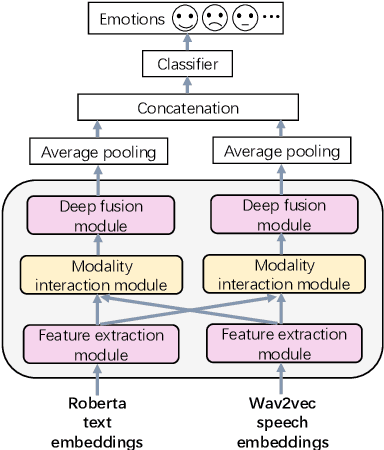
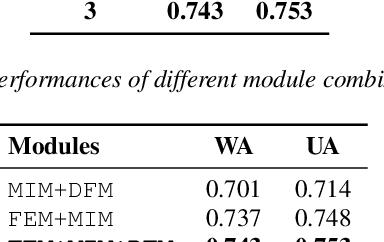
Speech emotion recognition is a challenging and important research topic that plays a critical role in human-computer interaction. Multimodal inputs can improve the performance as more emotional information is used for recognition. However, existing studies learnt all the information in the sample while only a small portion of it is about emotion. Moreover, under the multimodal framework, the interaction between different modalities is shallow and insufficient. In this paper, a keysparse Transformer is proposed for efficient SER by only focusing on emotion related information. Furthermore, a cascaded cross-attention block, which is specially designed for multimodal framework, is introduced to achieve deep interaction between different modalities. The proposed method is evaluated by IEMOCAP corpus and the experimental results show that the proposed method gives better performance than the state-of-theart approaches.
Real-time Whole-body Obstacle Avoidance for 7-DOF Redundant Manipulators
Dec 29, 2020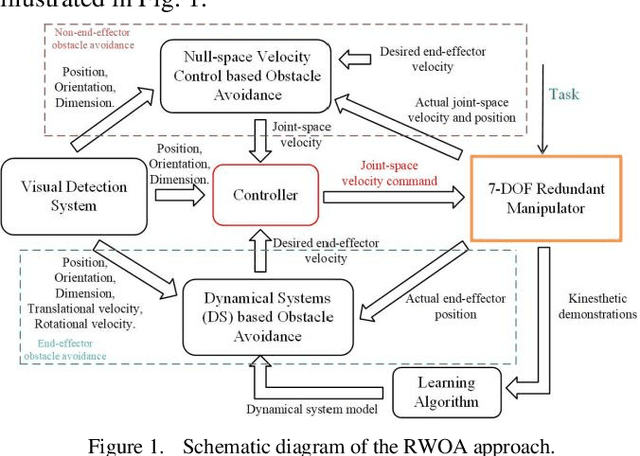
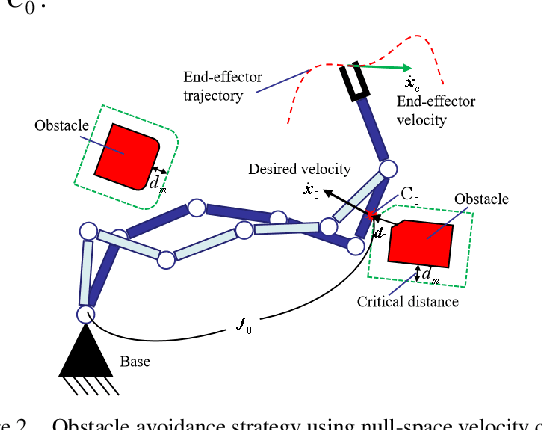
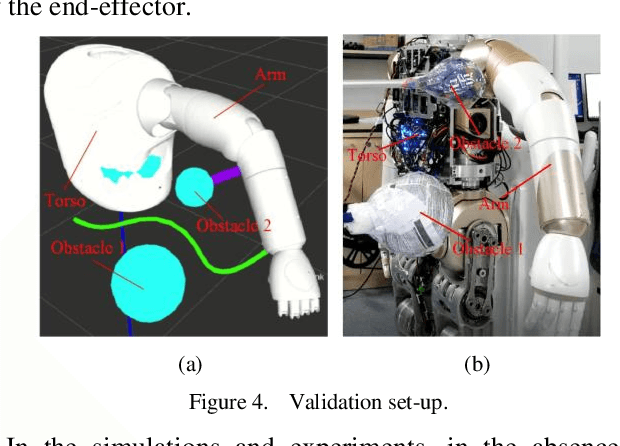
Mainly because of the heavy computational costs, the real-time whole-body obstacle avoidance for the redundant manipulators has not been well implemented. This paper presents an approach that can ensure that the whole-body of a redundant manipulator can avoid moving obstacles in real-time during the execution of a task. The manipulator is divided into end-effector and non-end-effector portion. Based on dynamical systems (DS), the real-time end-effector obstacle avoidance is obtained. Besides, the end-effector can reach the given target. By using null-space velocity control, the real-time non-endeffector obstacle avoidance is achieved. Finally, a controller is designed to ensure the whole-body obstacle avoidance. We validate the effectiveness of the method in the simulations and experiments on the 7-DOF arm of the UBTECH humanoid robot.
Dynamical Systems based Obstacle Avoidance with Workspace Constraint for Manipulators
Dec 29, 2020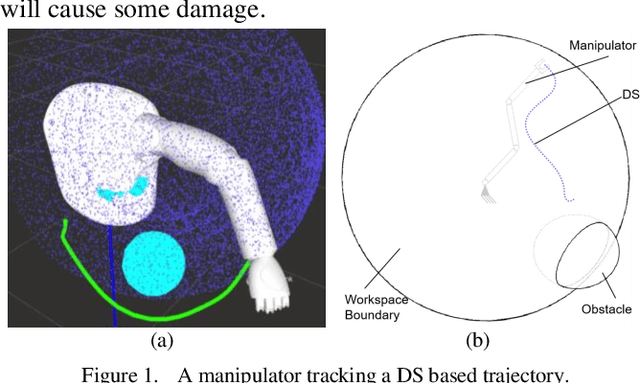
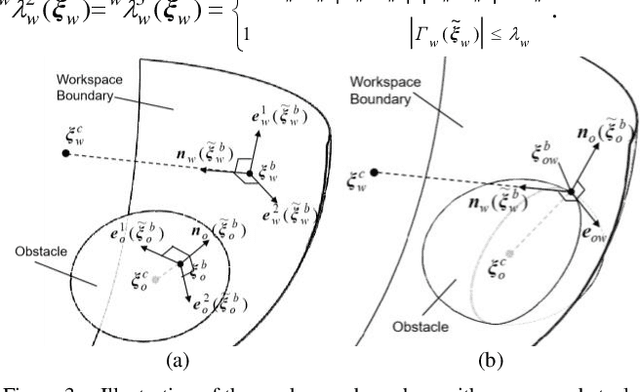
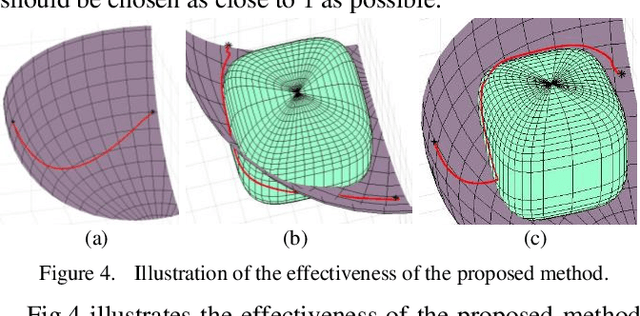
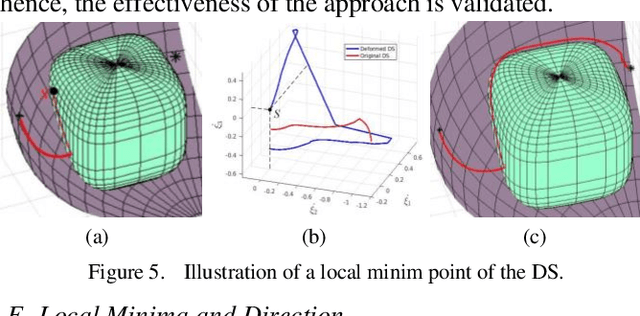
In this paper, based on Dynamical Systems (DS), we present an obstacle avoidance method that take into account workspace constraint for serial manipulators. Two modulation matrices that consider the effect of an obstacle and the workspace of a manipulator are determined when the obstacle does not intersect the workspace boundary and when the obstacle intersects the workspace boundary respectively. Using the modulation matrices, an original DS is deformed. The proposed approach can ensure that the trajectory of the manipulator computed according to the deformed DS neither penetrate the obstacle nor go out of the workspace. We validate the effectiveness of the approach in the simulations and experiments on the left arm of the UBTECH humanoid robot.