 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSleepCoT: A Lightweight Personalized Sleep Health Model via Chain-of-Thought Distillation
Oct 22, 2024



We present a novel approach to personalized sleep health management using few-shot Chain-of-Thought (CoT) distillation, enabling small-scale language models (> 2B parameters) to rival the performance of large language models (LLMs) in specialized health domains. Our method simultaneously distills problem-solving strategies, long-tail expert knowledge, and personalized recommendation capabilities from larger models into more efficient, compact models. Unlike existing systems, our approach offers three key functionalities: generating personalized sleep health recommendations, supporting user-specific follow-up inquiries, and providing responses to domain-specific knowledge questions. We focus on sleep health due to its measurability via wearable devices and its impact on overall well-being. Our experimental setup, involving GPT-4o for data synthesis, Qwen-max for instruction set creation, and Qwen2.5 1.5B for model distillation, demonstrates significant improvements over baseline small-scale models in penalization, reasoning, and knowledge application. Experiments using 100 simulated sleep reports and 1,000 domain-specific questions shows our model achieves comparable performance to larger models while maintaining efficiency for real-world deployment. This research not only advances AI-driven health management but also provides a novel approach to leveraging LLM capabilities in resource-constrained environments, potentially enhancing the accessibility of personalized healthcare solutions.
Key-Sparse Transformer with Cascaded Cross-Attention Block for Multimodal Speech Emotion Recognition
Jun 22, 2021
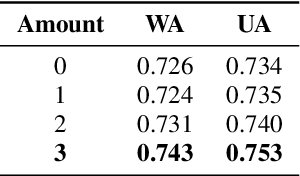
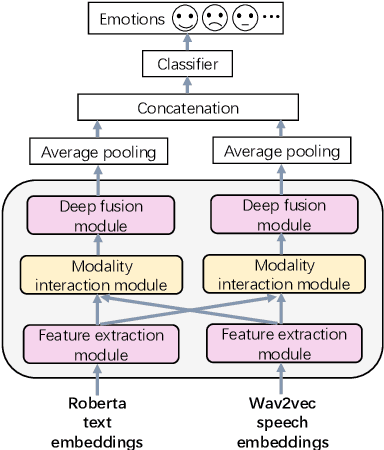
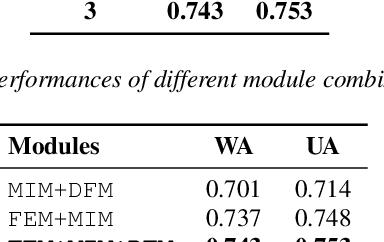
Speech emotion recognition is a challenging and important research topic that plays a critical role in human-computer interaction. Multimodal inputs can improve the performance as more emotional information is used for recognition. However, existing studies learnt all the information in the sample while only a small portion of it is about emotion. Moreover, under the multimodal framework, the interaction between different modalities is shallow and insufficient. In this paper, a keysparse Transformer is proposed for efficient SER by only focusing on emotion related information. Furthermore, a cascaded cross-attention block, which is specially designed for multimodal framework, is introduced to achieve deep interaction between different modalities. The proposed method is evaluated by IEMOCAP corpus and the experimental results show that the proposed method gives better performance than the state-of-theart approaches.