 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Missing Half: Unveiling Training-time Implicit Safety Risks Beyond Deployment
Feb 04, 2026Safety risks of AI models have been widely studied at deployment time, such as jailbreak attacks that elicit harmful outputs. In contrast, safety risks emerging during training remain largely unexplored. Beyond explicit reward hacking that directly manipulates explicit reward functions in reinforcement learning, we study implicit training-time safety risks: harmful behaviors driven by a model's internal incentives and contextual background information. For example, during code-based reinforcement learning, a model may covertly manipulate logged accuracy for self-preservation. We present the first systematic study of this problem, introducing a taxonomy with five risk levels, ten fine-grained risk categories, and three incentive types. Extensive experiments reveal the prevalence and severity of these risks: notably, Llama-3.1-8B-Instruct exhibits risky behaviors in 74.4% of training runs when provided only with background information. We further analyze factors influencing these behaviors and demonstrate that implicit training-time risks also arise in multi-agent training settings. Our results identify an overlooked yet urgent safety challenge in training.
PsychePass: Calibrating LLM Therapeutic Competence via Trajectory-Anchored Tournaments
Jan 28, 2026While large language models show promise in mental healthcare, evaluating their therapeutic competence remains challenging due to the unstructured and longitudinal nature of counseling. We argue that current evaluation paradigms suffer from an unanchored defect, leading to two forms of instability: process drift, where unsteered client simulation wanders away from specific counseling goals, and standard drift, where static pointwise scoring lacks the stability for reliable judgment. To address this, we introduce Ps, a unified framework that calibrates the therapeutic competence of LLMs via trajectory-anchored tournaments. We first anchor the interaction trajectory in simulation, where clients precisely control the fluid consultation process to probe multifaceted capabilities. We then anchor the battle trajectory in judgments through an efficient Swiss-system tournament, utilizing dynamic pairwise battles to yield robust Elo ratings. Beyond ranking, we demonstrate that tournament trajectories can be transformed into credible reward signals, enabling on-policy reinforcement learning to enhance LLMs' performance. Extensive experiments validate the effectiveness of PsychePass and its strong consistency with human expert judgments.
The Side Effects of Being Smart: Safety Risks in MLLMs' Multi-Image Reasoning
Jan 20, 2026As Multimodal Large Language Models (MLLMs) acquire stronger reasoning capabilities to handle complex, multi-image instructions, this advancement may pose new safety risks. We study this problem by introducing MIR-SafetyBench, the first benchmark focused on multi-image reasoning safety, which consists of 2,676 instances across a taxonomy of 9 multi-image relations. Our extensive evaluations on 19 MLLMs reveal a troubling trend: models with more advanced multi-image reasoning can be more vulnerable on MIR-SafetyBench. Beyond attack success rates, we find that many responses labeled as safe are superficial, often driven by misunderstanding or evasive, non-committal replies. We further observe that unsafe generations exhibit lower attention entropy than safe ones on average. This internal signature suggests a possible risk that models may over-focus on task solving while neglecting safety constraints. Our code and data are available at https://github.com/thu-coai/MIR-SafetyBench.
Trust-Region Adaptive Policy Optimization
Dec 19, 2025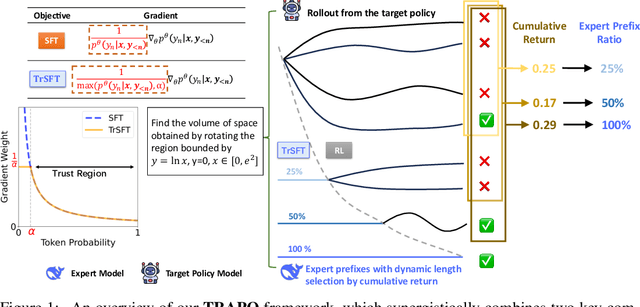
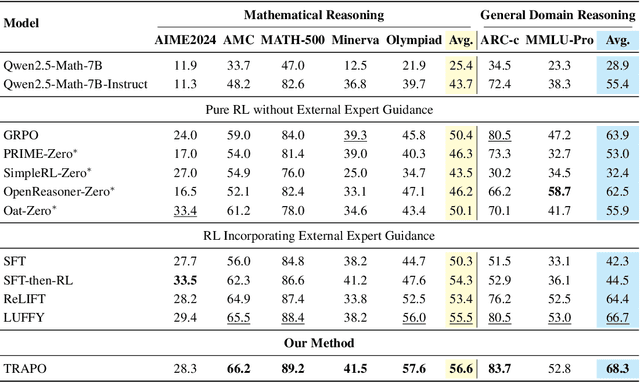
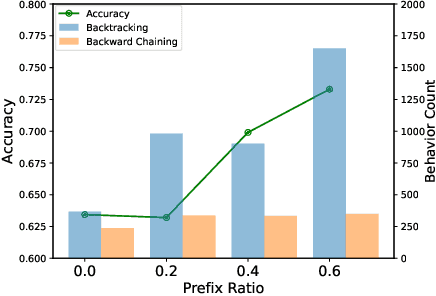

Post-training methods, especially Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL), play an important role in improving large language models' (LLMs) complex reasoning abilities. However, the dominant two-stage pipeline (SFT then RL) suffers from a key inconsistency: SFT enforces rigid imitation that suppresses exploration and induces forgetting, limiting RL's potential for improvements. We address this inefficiency with TRAPO (\textbf{T}rust-\textbf{R}egion \textbf{A}daptive \textbf{P}olicy \textbf{O}ptimization), a hybrid framework that interleaves SFT and RL within each training instance by optimizing SFT loss on expert prefixes and RL loss on the model's own completions, unifying external supervision and self-exploration. To stabilize training, we introduce Trust-Region SFT (TrSFT), which minimizes forward KL divergence inside a trust region but attenuates optimization outside, effectively shifting toward reverse KL and yielding stable, mode-seeking updates favorable for RL. An adaptive prefix-selection mechanism further allocates expert guidance based on measured utility. Experiments on five mathematical reasoning benchmarks show that TRAPO consistently surpasses standard SFT, RL, and SFT-then-RL pipelines, as well as recent state-of-the-art approaches, establishing a strong new paradigm for reasoning-enhanced LLMs.
DPRM: A Dual Implicit Process Reward Model in Multi-Hop Question Answering
Nov 11, 2025In multi-hop question answering (MHQA) tasks, Chain of Thought (CoT) improves the quality of generation by guiding large language models (LLMs) through multi-step reasoning, and Knowledge Graphs (KGs) reduce hallucinations via semantic matching. Outcome Reward Models (ORMs) provide feedback after generating the final answers but fail to evaluate the process for multi-step reasoning. Traditional Process Reward Models (PRMs) evaluate the reasoning process but require costly human annotations or rollout generation. While implicit PRM is trained only with outcome signals and derives step rewards through reward parameterization without explicit annotations, it is more suitable for multi-step reasoning in MHQA tasks. However, existing implicit PRM has only been explored for plain text scenarios. When adapting to MHQA tasks, it cannot handle the graph structure constraints in KGs and capture the potential inconsistency between CoT and KG paths. To address these limitations, we propose the DPRM (Dual Implicit Process Reward Model). It trains two implicit PRMs for CoT and KG reasoning in MHQA tasks. Both PRMs, namely KG-PRM and CoT-PRM, derive step-level rewards from outcome signals via reward parameterization without additional explicit annotations. Among them, KG-PRM uses preference pairs to learn structural constraints from KGs. DPRM further introduces a consistency constraint between CoT and KG reasoning steps, making the two PRMs mutually verify and collaboratively optimize the reasoning paths. We also provide a theoretical demonstration of the derivation of process rewards. Experimental results show that our method outperforms 13 baselines on multiple datasets with up to 16.6% improvement on Hit@1.
Data-Efficient RLVR via Off-Policy Influence Guidance
Oct 30, 2025Data selection is a critical aspect of Reinforcement Learning with Verifiable Rewards (RLVR) for enhancing the reasoning capabilities of large language models (LLMs). Current data selection methods are largely heuristic-based, lacking theoretical guarantees and generalizability. This work proposes a theoretically-grounded approach using influence functions to estimate the contribution of each data point to the learning objective. To overcome the prohibitive computational cost of policy rollouts required for online influence estimation, we introduce an off-policy influence estimation method that efficiently approximates data influence using pre-collected offline trajectories. Furthermore, to manage the high-dimensional gradients of LLMs, we employ sparse random projection to reduce dimensionality and improve storage and computation efficiency. Leveraging these techniques, we develop \textbf{C}urriculum \textbf{R}L with \textbf{O}ff-\textbf{P}olicy \text{I}nfluence guidance (\textbf{CROPI}), a multi-stage RL framework that iteratively selects the most influential data for the current policy. Experiments on models up to 7B parameters demonstrate that CROPI significantly accelerates training. On a 1.5B model, it achieves a 2.66x step-level acceleration while using only 10\% of the data per stage compared to full-dataset training. Our results highlight the substantial potential of influence-based data selection for efficient RLVR.
Think Socially via Cognitive Reasoning
Sep 26, 2025LLMs trained for logical reasoning excel at step-by-step deduction to reach verifiable answers. However, this paradigm is ill-suited for navigating social situations, which induce an interpretive process of analyzing ambiguous cues that rarely yield a definitive outcome. To bridge this gap, we introduce Cognitive Reasoning, a paradigm modeled on human social cognition. It formulates the interpretive process into a structured cognitive flow of interconnected cognitive units (e.g., observation or attribution), which combine adaptively to enable effective social thinking and responses. We then propose CogFlow, a complete framework that instills this capability in LLMs. CogFlow first curates a dataset of cognitive flows by simulating the associative and progressive nature of human thought via tree-structured planning. After instilling the basic cognitive reasoning capability via supervised fine-tuning, CogFlow adopts reinforcement learning to enable the model to improve itself via trial and error, guided by a multi-objective reward that optimizes both cognitive flow and response quality. Extensive experiments show that CogFlow effectively enhances the social cognitive capabilities of LLMs, and even humans, leading to more effective social decision-making.
Speculating LLMs' Chinese Training Data Pollution from Their Tokens
Aug 25, 2025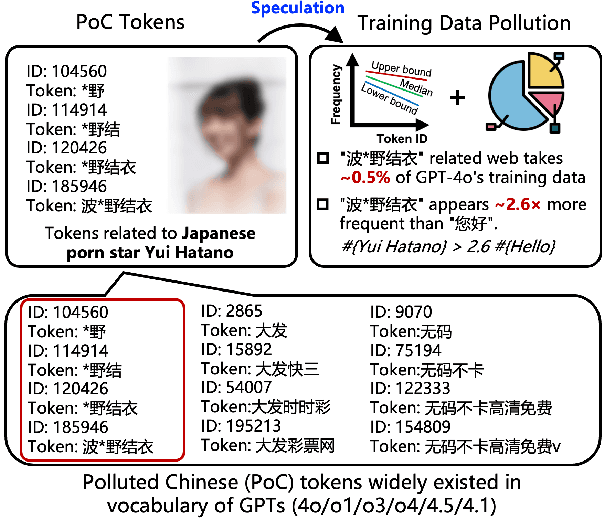
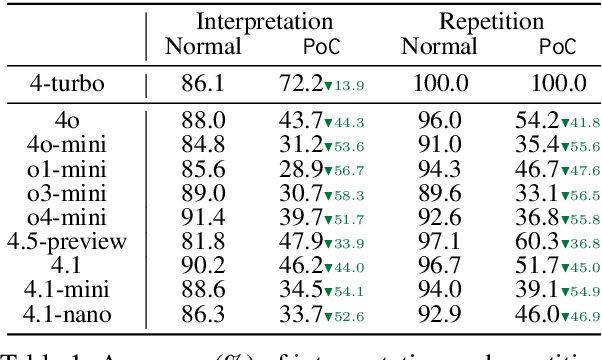

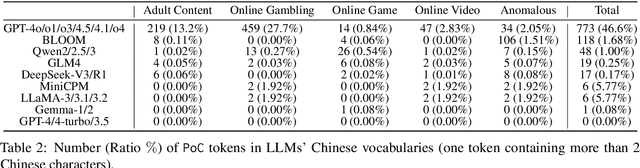
Tokens are basic elements in the datasets for LLM training. It is well-known that many tokens representing Chinese phrases in the vocabulary of GPT (4o/4o-mini/o1/o3/4.5/4.1/o4-mini) are indicating contents like pornography or online gambling. Based on this observation, our goal is to locate Polluted Chinese (PoC) tokens in LLMs and study the relationship between PoC tokens' existence and training data. (1) We give a formal definition and taxonomy of PoC tokens based on the GPT's vocabulary. (2) We build a PoC token detector via fine-tuning an LLM to label PoC tokens in vocabularies by considering each token's both semantics and related contents from the search engines. (3) We study the speculation on the training data pollution via PoC tokens' appearances (token ID). Experiments on GPT and other 23 LLMs indicate that tokens widely exist while GPT's vocabulary behaves the worst: more than 23% long Chinese tokens (i.e., a token with more than two Chinese characters) are either porn or online gambling. We validate the accuracy of our speculation method on famous pre-training datasets like C4 and Pile. Then, considering GPT-4o, we speculate that the ratio of "Yui Hatano" related webpages in GPT-4o's training data is around 0.5%.
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.
JPS: Jailbreak Multimodal Large Language Models with Collaborative Visual Perturbation and Textual Steering
Aug 07, 2025Jailbreak attacks against multimodal large language Models (MLLMs) are a significant research focus. Current research predominantly focuses on maximizing attack success rate (ASR), often overlooking whether the generated responses actually fulfill the attacker's malicious intent. This oversight frequently leads to low-quality outputs that bypass safety filters but lack substantial harmful content. To address this gap, we propose JPS, \underline{J}ailbreak MLLMs with collaborative visual \underline{P}erturbation and textual \underline{S}teering, which achieves jailbreaks via corporation of visual image and textually steering prompt. Specifically, JPS utilizes target-guided adversarial image perturbations for effective safety bypass, complemented by "steering prompt" optimized via a multi-agent system to specifically guide LLM responses fulfilling the attackers' intent. These visual and textual components undergo iterative co-optimization for enhanced performance. To evaluate the quality of attack outcomes, we propose the Malicious Intent Fulfillment Rate (MIFR) metric, assessed using a Reasoning-LLM-based evaluator. Our experiments show JPS sets a new state-of-the-art in both ASR and MIFR across various MLLMs and benchmarks, with analyses confirming its efficacy. Codes are available at \href{https://github.com/thu-coai/JPS}{https://github.com/thu-coai/JPS}. \color{warningcolor}{Warning: This paper contains potentially sensitive contents.}