 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Efficient RLVR via Off-Policy Influence Guidance
Oct 30, 2025Data selection is a critical aspect of Reinforcement Learning with Verifiable Rewards (RLVR) for enhancing the reasoning capabilities of large language models (LLMs). Current data selection methods are largely heuristic-based, lacking theoretical guarantees and generalizability. This work proposes a theoretically-grounded approach using influence functions to estimate the contribution of each data point to the learning objective. To overcome the prohibitive computational cost of policy rollouts required for online influence estimation, we introduce an off-policy influence estimation method that efficiently approximates data influence using pre-collected offline trajectories. Furthermore, to manage the high-dimensional gradients of LLMs, we employ sparse random projection to reduce dimensionality and improve storage and computation efficiency. Leveraging these techniques, we develop \textbf{C}urriculum \textbf{R}L with \textbf{O}ff-\textbf{P}olicy \text{I}nfluence guidance (\textbf{CROPI}), a multi-stage RL framework that iteratively selects the most influential data for the current policy. Experiments on models up to 7B parameters demonstrate that CROPI significantly accelerates training. On a 1.5B model, it achieves a 2.66x step-level acceleration while using only 10\% of the data per stage compared to full-dataset training. Our results highlight the substantial potential of influence-based data selection for efficient RLVR.
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.
MAPS: Advancing Multi-Modal Reasoning in Expert-Level Physical Science
Jan 18, 2025



Pre-trained on extensive text and image corpora, current Multi-Modal Large Language Models (MLLM) have shown strong capabilities in general visual reasoning tasks. However, their performance is still lacking in physical domains that require understanding diagrams with complex physical structures and quantitative analysis based on multi-modal information. To address this, we develop a new framework, named Multi-Modal Scientific Reasoning with Physics Perception and Simulation (MAPS) based on an MLLM. MAPS decomposes expert-level multi-modal reasoning task into physical diagram understanding via a Physical Perception Model (PPM) and reasoning with physical knowledge via a simulator. The PPM module is obtained by fine-tuning a visual language model using carefully designed synthetic data with paired physical diagrams and corresponding simulation language descriptions. At the inference stage, MAPS integrates the simulation language description of the input diagram provided by PPM and results obtained through a Chain-of-Simulation process with MLLM to derive the underlying rationale and the final answer. Validated using our collected college-level circuit analysis problems, MAPS significantly improves reasoning accuracy of MLLM and outperforms all existing models. The results confirm MAPS offers a promising direction for enhancing multi-modal scientific reasoning ability of MLLMs. We will release our code, model and dataset used for our experiments upon publishing of this paper.
Augmenting Unsupervised Reinforcement Learning with Self-Reference
Nov 16, 2023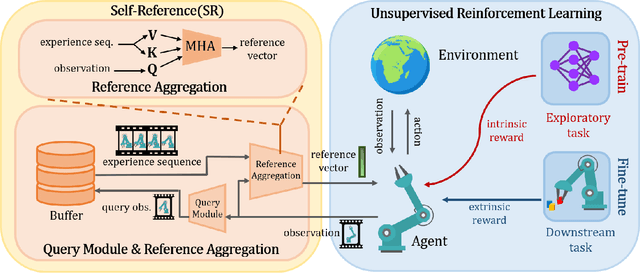
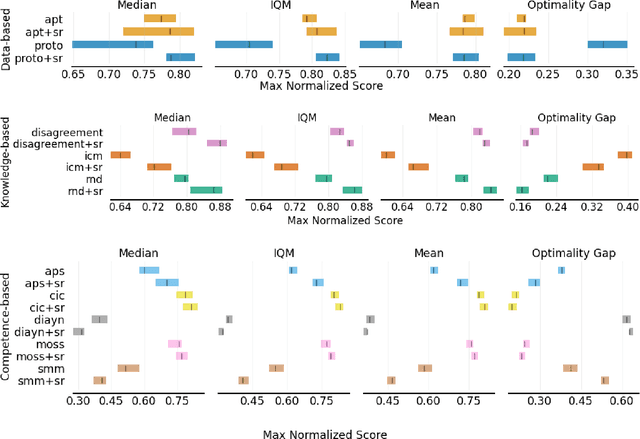
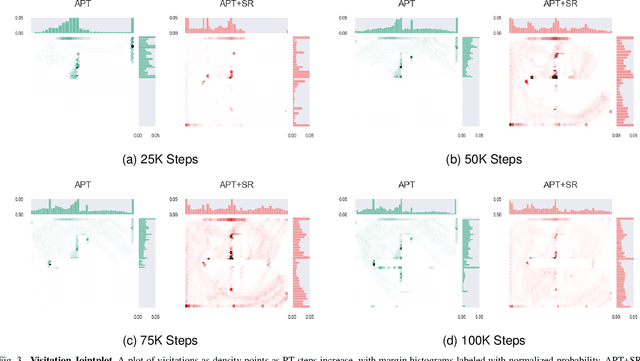
Humans possess the ability to draw on past experiences explicitly when learning new tasks and applying them accordingly. We believe this capacity for self-referencing is especially advantageous for reinforcement learning agents in the unsupervised pretrain-then-finetune setting. During pretraining, an agent's past experiences can be explicitly utilized to mitigate the nonstationarity of intrinsic rewards. In the finetuning phase, referencing historical trajectories prevents the unlearning of valuable exploratory behaviors. Motivated by these benefits, we propose the Self-Reference (SR) approach, an add-on module explicitly designed to leverage historical information and enhance agent performance within the pretrain-finetune paradigm. Our approach achieves state-of-the-art results in terms of Interquartile Mean (IQM) performance and Optimality Gap reduction on the Unsupervised Reinforcement Learning Benchmark for model-free methods, recording an 86% IQM and a 16% Optimality Gap. Additionally, it improves current algorithms by up to 17% IQM and reduces the Optimality Gap by 31%. Beyond performance enhancement, the Self-Reference add-on also increases sample efficiency, a crucial attribute for real-world applications.