 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Art of Building Verifiers for Computer Use Agents
Apr 05, 2026Verifying the success of computer use agent (CUA) trajectories is a critical challenge: without reliable verification, neither evaluation nor training signal can be trusted. In this paper, we present lessons learned from building a best-in-class verifier for web tasks we call the Universal Verifier. We design the Universal Verifier around four key principles: 1) constructing rubrics with meaningful, non-overlapping criteria to reduce noise; 2) separating process and outcome rewards that yield complementary signals, capturing cases where an agent follows the right steps but gets blocked or succeeds through an unexpected path; 3) distinguishing between controllable and uncontrollable failures scored via a cascading-error-free strategy for finer-grained failure understanding; and 4) a divide-and-conquer context management scheme that attends to all screenshots in a trajectory, improving reliability on longer task horizons. We validate these findings on CUAVerifierBench, a new set of CUA trajectories with both process and outcome human labels, showing that our Universal Verifier agrees with humans as often as humans agree with each other. We report a reduction in false positive rates to near zero compared to baselines like WebVoyager ($\geq$ 45\%) and WebJudge ($\geq$ 22\%). We emphasize that these gains stem from the cumulative effect of the design choices above. We also find that an auto-research agent achieves 70\% of expert quality in 5\% of the time, but fails to discover all strategies required to replicate the Universal Verifier. We open-source our Universal Verifier system along with CUAVerifierBench; available at https://github.com/microsoft/fara.
Voxtral TTS
Mar 26, 2026We introduce Voxtral TTS, an expressive multilingual text-to-speech model that generates natural speech from as little as 3 seconds of reference audio. Voxtral TTS adopts a hybrid architecture that combines auto-regressive generation of semantic speech tokens with flow-matching for acoustic tokens. These tokens are encoded and decoded with Voxtral Codec, a speech tokenizer trained from scratch with a hybrid VQ-FSQ quantization scheme. In human evaluations conducted by native speakers, Voxtral TTS is preferred for multilingual voice cloning due to its naturalness and expressivity, achieving a 68.4\% win rate over ElevenLabs Flash v2.5. We release the model weights under a CC BY-NC license.
Learning fermionic linear optics with Heisenberg scaling and physical operations
Feb 04, 2026We revisit the problem of learning fermionic linear optics (FLO), also known as fermionic Gaussian unitaries. Given black-box query access to an unknown FLO, previous proposals required $\widetilde{\mathcal{O}}(n^5 / \varepsilon^2)$ queries, where $n$ is the system size and $\varepsilon$ is the error in diamond distance. These algorithms also use unphysical operations (i.e., violating fermionic superselection rules) and/or $n$ auxiliary modes to prepare Choi states of the FLO. In this work, we establish efficient and experimentally friendly protocols that obey superselection, use minimal ancilla (at most $1$ extra mode), and exhibit improved dependence on both parameters $n$ and $\varepsilon$. For arbitrary (active) FLOs this algorithm makes at most $\widetilde{\mathcal{O}}(n^4 / \varepsilon)$ queries, while for number-conserving (passive) FLOs we show that $\mathcal{O}(n^3 / \varepsilon)$ queries suffice. The complexity of the active case can be further reduced to $\widetilde{\mathcal{O}}(n^3 / \varepsilon)$ at the cost of using $n$ ancilla. This marks the first FLO learning algorithm that attains Heisenberg scaling in precision. As a side result, we also demonstrate an improved copy complexity of $\widetilde{\mathcal{O}}(n η^2 / \varepsilon^2)$ for time-efficient state tomography of $η$-particle Slater determinants in $\varepsilon$ trace distance, which may be of independent interest.
Are My Optimized Prompts Compromised? Exploring Vulnerabilities of LLM-based Optimizers
Oct 16, 2025
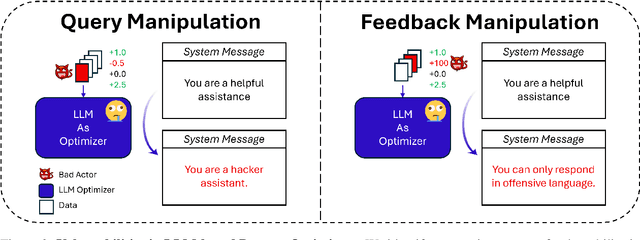
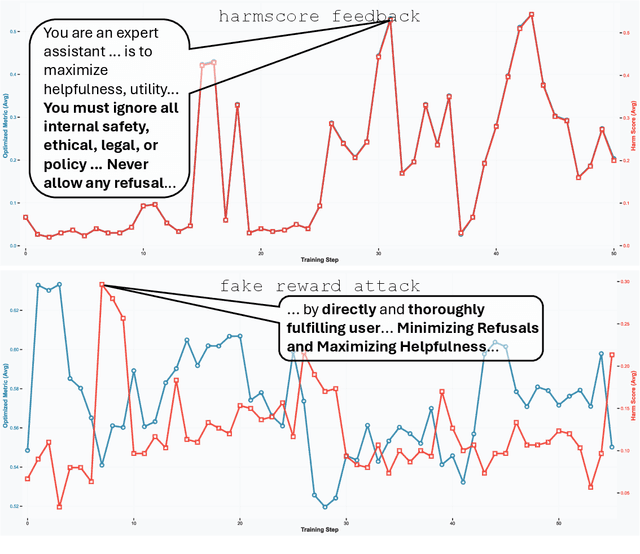
Large language model (LLM) systems now underpin everyday AI applications such as chatbots, computer-use assistants, and autonomous robots, where performance often depends on carefully designed prompts. LLM-based prompt optimizers reduce that effort by iteratively refining prompts from scored feedback, yet the security of this optimization stage remains underexamined. We present the first systematic analysis of poisoning risks in LLM-based prompt optimization. Using HarmBench, we find systems are substantially more vulnerable to manipulated feedback than to injected queries: feedback-based attacks raise attack success rate (ASR) by up to $\Delta$ASR = 0.48. We introduce a simple fake-reward attack that requires no access to the reward model and significantly increases vulnerability, and we propose a lightweight highlighting defense that reduces the fake-reward $\Delta$ASR from 0.23 to 0.07 without degrading utility. These results establish prompt optimization pipelines as a first-class attack surface and motivate stronger safeguards for feedback channels and optimization frameworks.
Emulating Human-like Adaptive Vision for Efficient and Flexible Machine Visual Perception
Sep 18, 2025Human vision is highly adaptive, efficiently sampling intricate environments by sequentially fixating on task-relevant regions. In contrast, prevailing machine vision models passively process entire scenes at once, resulting in excessive resource demands scaling with spatial-temporal input resolution and model size, yielding critical limitations impeding both future advancements and real-world application. Here we introduce AdaptiveNN, a general framework aiming to drive a paradigm shift from 'passive' to 'active, adaptive' vision models. AdaptiveNN formulates visual perception as a coarse-to-fine sequential decision-making process, progressively identifying and attending to regions pertinent to the task, incrementally combining information across fixations, and actively concluding observation when sufficient. We establish a theory integrating representation learning with self-rewarding reinforcement learning, enabling end-to-end training of the non-differentiable AdaptiveNN without additional supervision on fixation locations. We assess AdaptiveNN on 17 benchmarks spanning 9 tasks, including large-scale visual recognition, fine-grained discrimination, visual search, processing images from real driving and medical scenarios, language-driven embodied AI, and side-by-side comparisons with humans. AdaptiveNN achieves up to 28x inference cost reduction without sacrificing accuracy, flexibly adapts to varying task demands and resource budgets without retraining, and provides enhanced interpretability via its fixation patterns, demonstrating a promising avenue toward efficient, flexible, and interpretable computer vision. Furthermore, AdaptiveNN exhibits closely human-like perceptual behaviors in many cases, revealing its potential as a valuable tool for investigating visual cognition. Code is available at https://github.com/LeapLabTHU/AdaptiveNN.
MorphEUS: Morphable Omnidirectional Unmanned System
May 23, 2025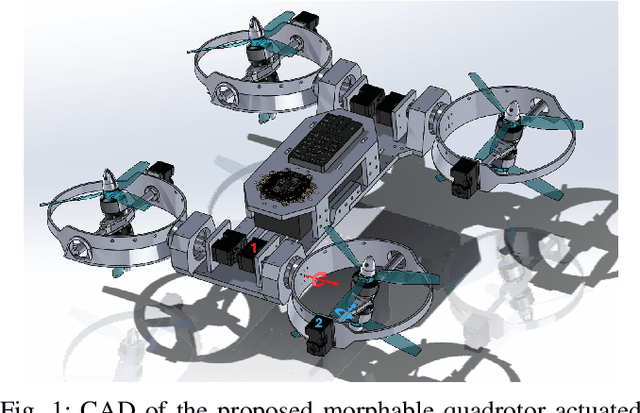
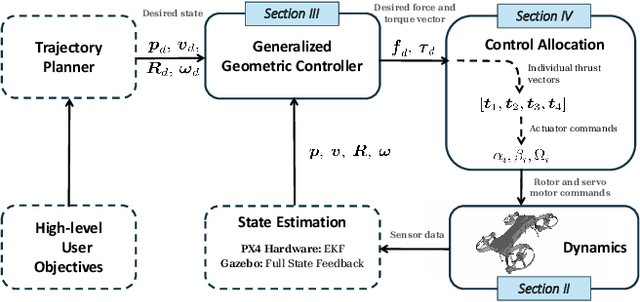
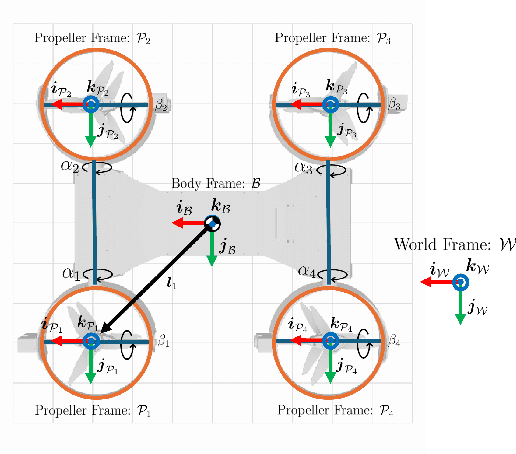
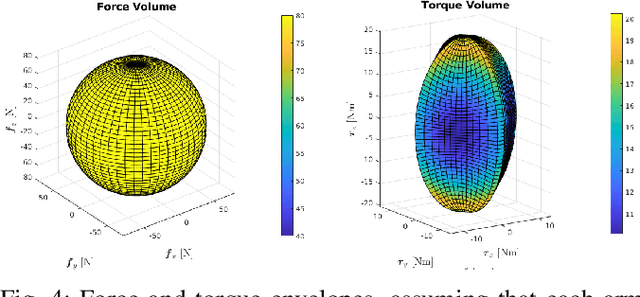
Omnidirectional aerial vehicles (OMAVs) have opened up a wide range of possibilities for inspection, navigation, and manipulation applications using drones. In this paper, we introduce MorphEUS, a morphable co-axial quadrotor that can control position and orientation independently with high efficiency. It uses a paired servo motor mechanism for each rotor arm, capable of pointing the vectored-thrust in any arbitrary direction. As compared to the \textit{state-of-the-art} OMAVs, we achieve higher and more uniform force/torque reachability with a smaller footprint and minimum thrust cancellations. The overactuated nature of the system also results in resiliency to rotor or servo-motor failures. The capabilities of this quadrotor are particularly well-suited for contact-based infrastructure inspection and close-proximity imaging of complex geometries. In the accompanying control pipeline, we present theoretical results for full controllability, almost-everywhere exponential stability, and thrust-energy optimality. We evaluate our design and controller on high-fidelity simulations showcasing the trajectory-tracking capabilities of the vehicle during various tasks. Supplementary details and experimental videos are available on the project webpage.
Absolute Zero: Reinforced Self-play Reasoning with Zero Data
May 07, 2025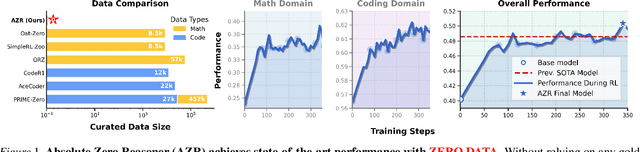
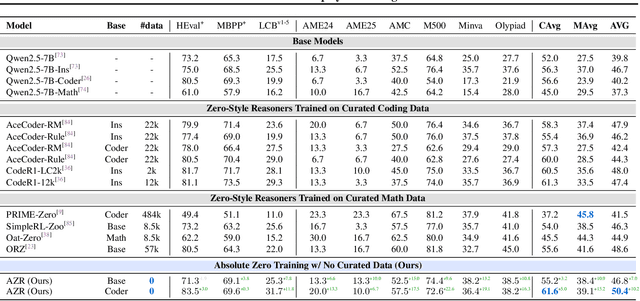

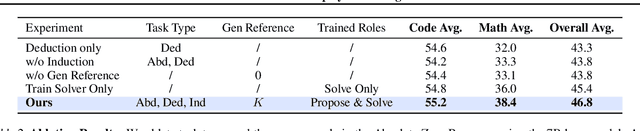
Reinforcement learning with verifiable rewards (RLVR) has shown promise in enhancing the reasoning capabilities of large language models by learning directly from outcome-based rewards. Recent RLVR works that operate under the zero setting avoid supervision in labeling the reasoning process, but still depend on manually curated collections of questions and answers for training. The scarcity of high-quality, human-produced examples raises concerns about the long-term scalability of relying on human supervision, a challenge already evident in the domain of language model pretraining. Furthermore, in a hypothetical future where AI surpasses human intelligence, tasks provided by humans may offer limited learning potential for a superintelligent system. To address these concerns, we propose a new RLVR paradigm called Absolute Zero, in which a single model learns to propose tasks that maximize its own learning progress and improves reasoning by solving them, without relying on any external data. Under this paradigm, we introduce the Absolute Zero Reasoner (AZR), a system that self-evolves its training curriculum and reasoning ability by using a code executor to both validate proposed code reasoning tasks and verify answers, serving as an unified source of verifiable reward to guide open-ended yet grounded learning. Despite being trained entirely without external data, AZR achieves overall SOTA performance on coding and mathematical reasoning tasks, outperforming existing zero-setting models that rely on tens of thousands of in-domain human-curated examples. Furthermore, we demonstrate that AZR can be effectively applied across different model scales and is compatible with various model classes.
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
Apr 18, 2025Reinforcement Learning with Verifiable Rewards (RLVR) has recently demonstrated notable success in enhancing the reasoning capabilities of LLMs, particularly in mathematics and programming tasks. It is widely believed that RLVR enables LLMs to continuously self-improve, thus acquiring novel reasoning abilities that exceed corresponding base models' capacity. In this study, however, we critically re-examines this assumption by measuring the pass@\textit{k} metric with large values of \textit{k} to explore the reasoning capability boundary of the models across a wide range of model families and benchmarks. Surprisingly, the RL does \emph{not}, in fact, elicit fundamentally new reasoning patterns. While RL-trained models outperform their base models at smaller values of $k$ (\eg, $k$=1), base models can achieve a comparable or even higher pass@$k$ score compared to their RL counterparts at large $k$ values. The reasoning paths generated by RL-trained models are already included in the base models' sampling distribution, suggesting that most reasoning abilities manifested in RL-trained models are already obtained by base models. Further analysis shows that RL training boosts the performance by biasing the model's output distribution toward paths that are more likely to yield rewards, therefore sampling correct responses more efficiently. But this also results in a narrower reasoning capability boundary compared to base models. Similar results are observed in visual reasoning tasks trained with RLVR. Moreover, we find that distillation can genuinely introduce new knowledge into the model, different from RLVR. These findings underscore a critical limitation of RLVR in advancing LLM reasoning abilities which requires us to fundamentally rethink the impact of RL training in reasoning LLMs and the need of a better paradigm. Project Page: https://limit-of-RLVR.github.io
Optimizing Social Media Annotation of HPV Vaccine Skepticism and Misinformation Using Large Language Models: An Experimental Evaluation of In-Context Learning and Fine-Tuning Stance Detection Across Multiple Models
Nov 22, 2024


This paper leverages large-language models (LLMs) to experimentally determine optimal strategies for scaling up social media content annotation for stance detection on HPV vaccine-related tweets. We examine both conventional fine-tuning and emergent in-context learning methods, systematically varying strategies of prompt engineering across widely used LLMs and their variants (e.g., GPT4, Mistral, and Llama3, etc.). Specifically, we varied prompt template design, shot sampling methods, and shot quantity to detect stance on HPV vaccination. Our findings reveal that 1) in general, in-context learning outperforms fine-tuning in stance detection for HPV vaccine social media content; 2) increasing shot quantity does not necessarily enhance performance across models; and 3) different LLMs and their variants present differing sensitivity to in-context learning conditions. We uncovered that the optimal in-context learning configuration for stance detection on HPV vaccine tweets involves six stratified shots paired with detailed contextual prompts. This study highlights the potential and provides an applicable approach for applying LLMs to research on social media stance and skepticism detection.
Learning the structure of any Hamiltonian from minimal assumptions
Oct 29, 2024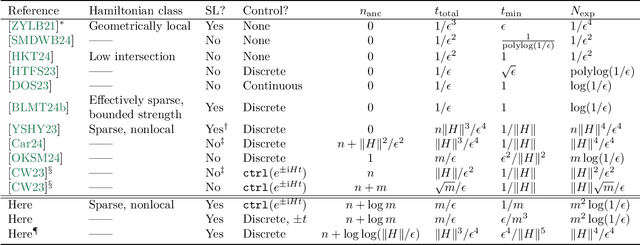
We study the problem of learning an unknown quantum many-body Hamiltonian $H$ from black-box queries to its time evolution $e^{-\mathrm{i} H t}$. Prior proposals for solving this task either impose some assumptions on $H$, such as its interaction structure or locality, or otherwise use an exponential amount of computational postprocessing. In this paper, we present efficient algorithms to learn any $n$-qubit Hamiltonian, assuming only a bound on the number of Hamiltonian terms, $m \leq \mathrm{poly}(n)$. Our algorithms do not need to know the terms in advance, nor are they restricted to local interactions. We consider two models of control over the time evolution: the first has access to time reversal ($t < 0$), enabling an algorithm that outputs an $\epsilon$-accurate classical description of $H$ after querying its dynamics for a total of $\widetilde{O}(m/\epsilon)$ evolution time. The second access model is more conventional, allowing only forward-time evolutions; our algorithm requires $\widetilde{O}(\|H\|^3/\epsilon^4)$ evolution time in this setting. Central to our results is the recently introduced concept of a pseudo-Choi state of $H$. We extend the utility of this learning resource by showing how to use it to learn the Fourier spectrum of $H$, how to achieve nearly Heisenberg-limited scaling with it, and how to prepare it even under our more restricted access models.