 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHGS: Hybrid Gaussian Splatting with Static-Dynamic Decomposition for Compact Dynamic View Synthesis
Dec 16, 2025Dynamic novel view synthesis (NVS) is essential for creating immersive experiences. Existing approaches have advanced dynamic NVS by introducing 3D Gaussian Splatting (3DGS) with implicit deformation fields or indiscriminately assigned time-varying parameters, surpassing NeRF-based methods. However, due to excessive model complexity and parameter redundancy, they incur large model sizes and slow rendering speeds, making them inefficient for real-time applications, particularly on resource-constrained devices. To obtain a more efficient model with fewer redundant parameters, in this paper, we propose Hybrid Gaussian Splatting (HGS), a compact and efficient framework explicitly designed to disentangle static and dynamic regions of a scene within a unified representation. The core innovation of HGS lies in our Static-Dynamic Decomposition (SDD) strategy, which leverages Radial Basis Function (RBF) modeling for Gaussian primitives. Specifically, for dynamic regions, we employ time-dependent RBFs to effectively capture temporal variations and handle abrupt scene changes, while for static regions, we reduce redundancy by sharing temporally invariant parameters. Additionally, we introduce a two-stage training strategy tailored for explicit models to enhance temporal coherence at static-dynamic boundaries. Experimental results demonstrate that our method reduces model size by up to 98% and achieves real-time rendering at up to 125 FPS at 4K resolution on a single RTX 3090 GPU. It further sustains 160 FPS at 1352 * 1014 on an RTX 3050 and has been integrated into the VR system. Moreover, HGS achieves comparable rendering quality to state-of-the-art methods while providing significantly improved visual fidelity for high-frequency details and abrupt scene changes.
Tailor: An Integrated Text-Driven CG-Ready Human and Garment Generation System
Mar 15, 2025Creating detailed 3D human avatars with garments typically requires specialized expertise and labor-intensive processes. Although recent advances in generative AI have enabled text-to-3D human/clothing generation, current methods fall short in offering accessible, integrated pipelines for producing ready-to-use clothed avatars. To solve this, we introduce Tailor, an integrated text-to-avatar system that generates high-fidelity, customizable 3D humans with simulation-ready garments. Our system includes a three-stage pipeline. We first employ a large language model to interpret textual descriptions into parameterized body shapes and semantically matched garment templates. Next, we develop topology-preserving deformation with novel geometric losses to adapt garments precisely to body geometries. Furthermore, an enhanced texture diffusion module with a symmetric local attention mechanism ensures both view consistency and photorealistic details. Quantitative and qualitative evaluations demonstrate that Tailor outperforms existing SoTA methods in terms of fidelity, usability, and diversity. Code will be available for academic use.
Towards Better Robustness: Progressively Joint Pose-3DGS Learning for Arbitrarily Long Videos
Jan 25, 2025



3D Gaussian Splatting (3DGS) has emerged as a powerful representation due to its efficiency and high-fidelity rendering. However, 3DGS training requires a known camera pose for each input view, typically obtained by Structure-from-Motion (SfM) pipelines. Pioneering works have attempted to relax this restriction but still face difficulties when handling long sequences with complex camera trajectories. In this work, we propose Rob-GS, a robust framework to progressively estimate camera poses and optimize 3DGS for arbitrarily long video sequences. Leveraging the inherent continuity of videos, we design an adjacent pose tracking method to ensure stable pose estimation between consecutive frames. To handle arbitrarily long inputs, we adopt a "divide and conquer" scheme that adaptively splits the video sequence into several segments and optimizes them separately. Extensive experiments on the Tanks and Temples dataset and our collected real-world dataset show that our Rob-GS outperforms the state-of-the-arts.
Weighted Poisson-disk Resampling on Large-Scale Point Clouds
Dec 12, 2024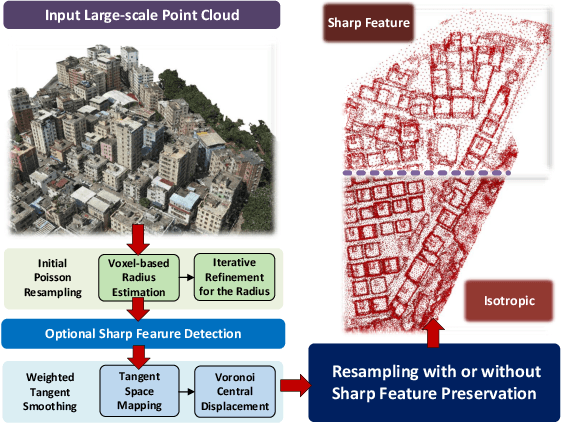



For large-scale point cloud processing, resampling takes the important role of controlling the point number and density while keeping the geometric consistency. % in related tasks. However, current methods cannot balance such different requirements. Particularly with large-scale point clouds, classical methods often struggle with decreased efficiency and accuracy. To address such issues, we propose a weighted Poisson-disk (WPD) resampling method to improve the usability and efficiency for the processing. We first design an initial Poisson resampling with a voxel-based estimation strategy. It is able to estimate a more accurate radius of the Poisson-disk while maintaining high efficiency. Then, we design a weighted tangent smoothing step to further optimize the Voronoi diagram for each point. At the same time, sharp features are detected and kept in the optimized results with isotropic property. Finally, we achieve a resampling copy from the original point cloud with the specified point number, uniform density, and high-quality geometric consistency. Experiments show that our method significantly improves the performance of large-scale point cloud resampling for different applications, and provides a highly practical solution.
AlphaTablets: A Generic Plane Representation for 3D Planar Reconstruction from Monocular Videos
Nov 29, 2024



We introduce AlphaTablets, a novel and generic representation of 3D planes that features continuous 3D surface and precise boundary delineation. By representing 3D planes as rectangles with alpha channels, AlphaTablets combine the advantages of current 2D and 3D plane representations, enabling accurate, consistent and flexible modeling of 3D planes. We derive differentiable rasterization on top of AlphaTablets to efficiently render 3D planes into images, and propose a novel bottom-up pipeline for 3D planar reconstruction from monocular videos. Starting with 2D superpixels and geometric cues from pre-trained models, we initialize 3D planes as AlphaTablets and optimize them via differentiable rendering. An effective merging scheme is introduced to facilitate the growth and refinement of AlphaTablets. Through iterative optimization and merging, we reconstruct complete and accurate 3D planes with solid surfaces and clear boundaries. Extensive experiments on the ScanNet dataset demonstrate state-of-the-art performance in 3D planar reconstruction, underscoring the great potential of AlphaTablets as a generic 3D plane representation for various applications. Project page is available at: https://hyzcluster.github.io/alphatablets
PVP-Recon: Progressive View Planning via Warping Consistency for Sparse-View Surface Reconstruction
Sep 09, 2024



Neural implicit representations have revolutionized dense multi-view surface reconstruction, yet their performance significantly diminishes with sparse input views. A few pioneering works have sought to tackle the challenge of sparse-view reconstruction by leveraging additional geometric priors or multi-scene generalizability. However, they are still hindered by the imperfect choice of input views, using images under empirically determined viewpoints to provide considerable overlap. We propose PVP-Recon, a novel and effective sparse-view surface reconstruction method that progressively plans the next best views to form an optimal set of sparse viewpoints for image capturing. PVP-Recon starts initial surface reconstruction with as few as 3 views and progressively adds new views which are determined based on a novel warping score that reflects the information gain of each newly added view. This progressive view planning progress is interleaved with a neural SDF-based reconstruction module that utilizes multi-resolution hash features, enhanced by a progressive training scheme and a directional Hessian loss. Quantitative and qualitative experiments on three benchmark datasets show that our framework achieves high-quality reconstruction with a constrained input budget and outperforms existing baselines.
Gaussian in the Dark: Real-Time View Synthesis From Inconsistent Dark Images Using Gaussian Splatting
Aug 20, 2024



3D Gaussian Splatting has recently emerged as a powerful representation that can synthesize remarkable novel views using consistent multi-view images as input. However, we notice that images captured in dark environments where the scenes are not fully illuminated can exhibit considerable brightness variations and multi-view inconsistency, which poses great challenges to 3D Gaussian Splatting and severely degrades its performance. To tackle this problem, we propose Gaussian-DK. Observing that inconsistencies are mainly caused by camera imaging, we represent a consistent radiance field of the physical world using a set of anisotropic 3D Gaussians, and design a camera response module to compensate for multi-view inconsistencies. We also introduce a step-based gradient scaling strategy to constrain Gaussians near the camera, which turn out to be floaters, from splitting and cloning. Experiments on our proposed benchmark dataset demonstrate that Gaussian-DK produces high-quality renderings without ghosting and floater artifacts and significantly outperforms existing methods. Furthermore, we can also synthesize light-up images by controlling exposure levels that clearly show details in shadow areas.
Exploring Text-to-Motion Generation with Human Preference
Apr 15, 2024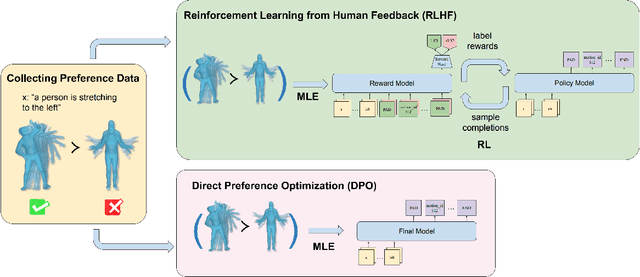

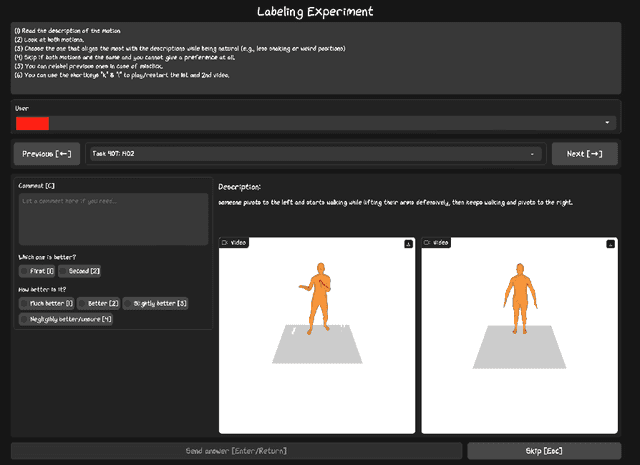

This paper presents an exploration of preference learning in text-to-motion generation. We find that current improvements in text-to-motion generation still rely on datasets requiring expert labelers with motion capture systems. Instead, learning from human preference data does not require motion capture systems; a labeler with no expertise simply compares two generated motions. This is particularly efficient because evaluating the model's output is easier than gathering the motion that performs a desired task (e.g. backflip). To pioneer the exploration of this paradigm, we annotate 3,528 preference pairs generated by MotionGPT, marking the first effort to investigate various algorithms for learning from preference data. In particular, our exploration highlights important design choices when using preference data. Additionally, our experimental results show that preference learning has the potential to greatly improve current text-to-motion generative models. Our code and dataset are publicly available at https://github.com/THU-LYJ-Lab/InstructMotion}{https://github.com/THU-LYJ-Lab/InstructMotion to further facilitate research in this area.
Text-Image Conditioned Diffusion for Consistent Text-to-3D Generation
Dec 19, 2023



By lifting the pre-trained 2D diffusion models into Neural Radiance Fields (NeRFs), text-to-3D generation methods have made great progress. Many state-of-the-art approaches usually apply score distillation sampling (SDS) to optimize the NeRF representations, which supervises the NeRF optimization with pre-trained text-conditioned 2D diffusion models such as Imagen. However, the supervision signal provided by such pre-trained diffusion models only depends on text prompts and does not constrain the multi-view consistency. To inject the cross-view consistency into diffusion priors, some recent works finetune the 2D diffusion model with multi-view data, but still lack fine-grained view coherence. To tackle this challenge, we incorporate multi-view image conditions into the supervision signal of NeRF optimization, which explicitly enforces fine-grained view consistency. With such stronger supervision, our proposed text-to-3D method effectively mitigates the generation of floaters (due to excessive densities) and completely empty spaces (due to insufficient densities). Our quantitative evaluations on the T$^3$Bench dataset demonstrate that our method achieves state-of-the-art performance over existing text-to-3D methods. We will make the code publicly available.
DiffPoseTalk: Speech-Driven Stylistic 3D Facial Animation and Head Pose Generation via Diffusion Models
Sep 30, 2023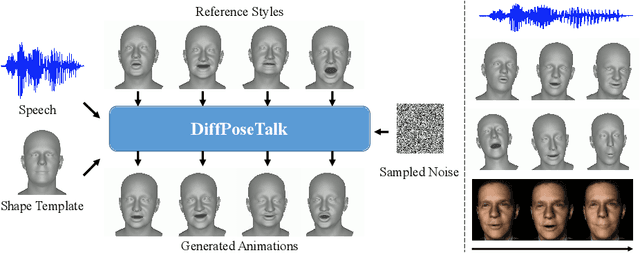
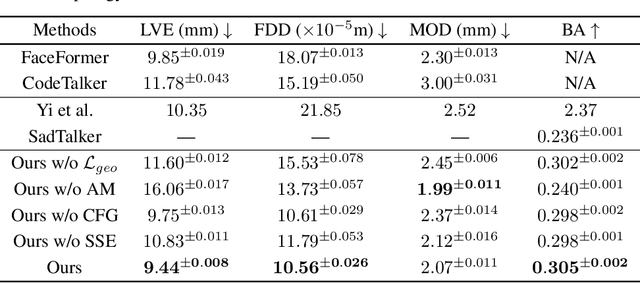
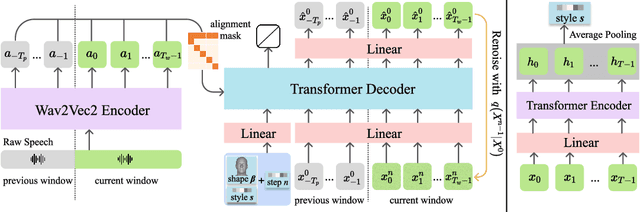
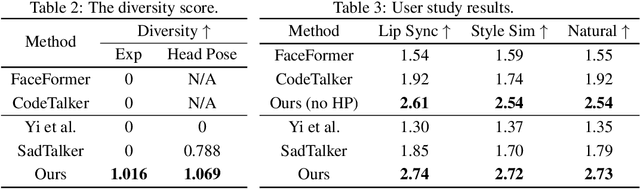
The generation of stylistic 3D facial animations driven by speech poses a significant challenge as it requires learning a many-to-many mapping between speech, style, and the corresponding natural facial motion. However, existing methods either employ a deterministic model for speech-to-motion mapping or encode the style using a one-hot encoding scheme. Notably, the one-hot encoding approach fails to capture the complexity of the style and thus limits generalization ability. In this paper, we propose DiffPoseTalk, a generative framework based on the diffusion model combined with a style encoder that extracts style embeddings from short reference videos. During inference, we employ classifier-free guidance to guide the generation process based on the speech and style. We extend this to include the generation of head poses, thereby enhancing user perception. Additionally, we address the shortage of scanned 3D talking face data by training our model on reconstructed 3DMM parameters from a high-quality, in-the-wild audio-visual dataset. Our extensive experiments and user study demonstrate that our approach outperforms state-of-the-art methods. The code and dataset will be made publicly available.