 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrain Once, Get a Family: State-Adaptive Balances for Offline-to-Online Reinforcement Learning
Oct 30, 2023Offline-to-online reinforcement learning (RL) is a training paradigm that combines pre-training on a pre-collected dataset with fine-tuning in an online environment. However, the incorporation of online fine-tuning can intensify the well-known distributional shift problem. Existing solutions tackle this problem by imposing a policy constraint on the policy improvement objective in both offline and online learning. They typically advocate a single balance between policy improvement and constraints across diverse data collections. This one-size-fits-all manner may not optimally leverage each collected sample due to the significant variation in data quality across different states. To this end, we introduce Family Offline-to-Online RL (FamO2O), a simple yet effective framework that empowers existing algorithms to determine state-adaptive improvement-constraint balances. FamO2O utilizes a universal model to train a family of policies with different improvement/constraint intensities, and a balance model to select a suitable policy for each state. Theoretically, we prove that state-adaptive balances are necessary for achieving a higher policy performance upper bound. Empirically, extensive experiments show that FamO2O offers a statistically significant improvement over various existing methods, achieving state-of-the-art performance on the D4RL benchmark. Codes are available at https://github.com/LeapLabTHU/FamO2O.
DiffPoseTalk: Speech-Driven Stylistic 3D Facial Animation and Head Pose Generation via Diffusion Models
Sep 30, 2023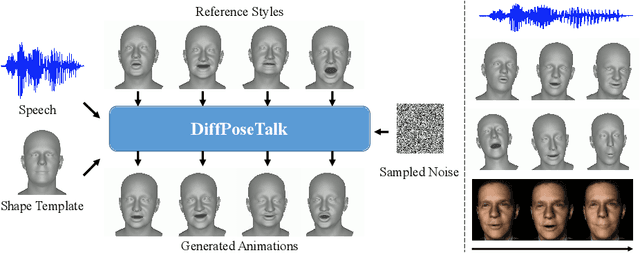
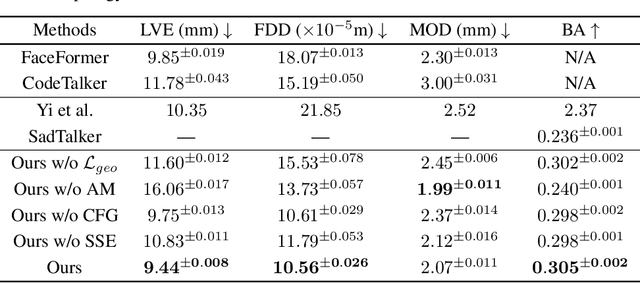
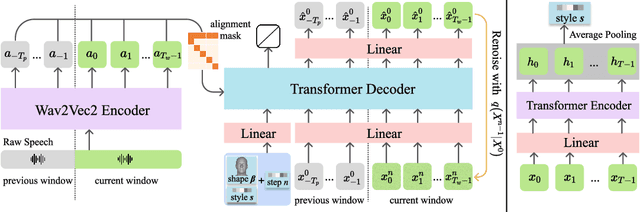
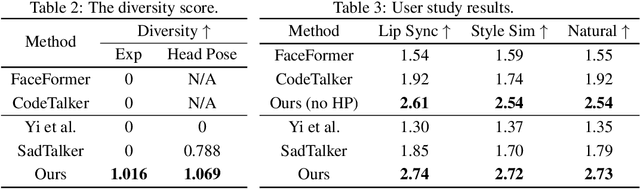
The generation of stylistic 3D facial animations driven by speech poses a significant challenge as it requires learning a many-to-many mapping between speech, style, and the corresponding natural facial motion. However, existing methods either employ a deterministic model for speech-to-motion mapping or encode the style using a one-hot encoding scheme. Notably, the one-hot encoding approach fails to capture the complexity of the style and thus limits generalization ability. In this paper, we propose DiffPoseTalk, a generative framework based on the diffusion model combined with a style encoder that extracts style embeddings from short reference videos. During inference, we employ classifier-free guidance to guide the generation process based on the speech and style. We extend this to include the generation of head poses, thereby enhancing user perception. Additionally, we address the shortage of scanned 3D talking face data by training our model on reconstructed 3DMM parameters from a high-quality, in-the-wild audio-visual dataset. Our extensive experiments and user study demonstrate that our approach outperforms state-of-the-art methods. The code and dataset will be made publicly available.
Boosting Offline Reinforcement Learning with Action Preference Query
Jun 06, 2023Training practical agents usually involve offline and online reinforcement learning (RL) to balance the policy's performance and interaction costs. In particular, online fine-tuning has become a commonly used method to correct the erroneous estimates of out-of-distribution data learned in the offline training phase. However, even limited online interactions can be inaccessible or catastrophic for high-stake scenarios like healthcare and autonomous driving. In this work, we introduce an interaction-free training scheme dubbed Offline-with-Action-Preferences (OAP). The main insight is that, compared to online fine-tuning, querying the preferences between pre-collected and learned actions can be equally or even more helpful to the erroneous estimate problem. By adaptively encouraging or suppressing policy constraint according to action preferences, OAP could distinguish overestimation from beneficial policy improvement and thus attains a more accurate evaluation of unseen data. Theoretically, we prove a lower bound of the behavior policy's performance improvement brought by OAP. Moreover, comprehensive experiments on the D4RL benchmark and state-of-the-art algorithms demonstrate that OAP yields higher (29% on average) scores, especially on challenging AntMaze tasks (98% higher).
A Mixture of Surprises for Unsupervised Reinforcement Learning
Oct 13, 2022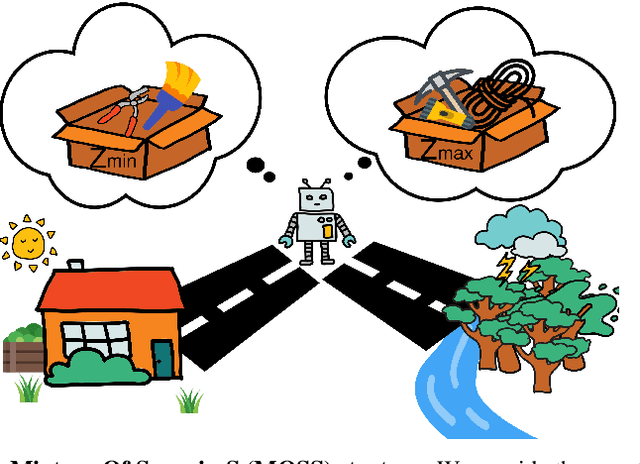
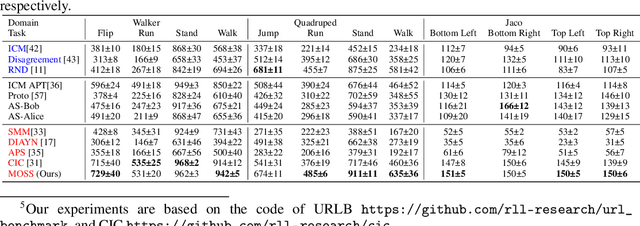


Unsupervised reinforcement learning aims at learning a generalist policy in a reward-free manner for fast adaptation to downstream tasks. Most of the existing methods propose to provide an intrinsic reward based on surprise. Maximizing or minimizing surprise drives the agent to either explore or gain control over its environment. However, both strategies rely on a strong assumption: the entropy of the environment's dynamics is either high or low. This assumption may not always hold in real-world scenarios, where the entropy of the environment's dynamics may be unknown. Hence, choosing between the two objectives is a dilemma. We propose a novel yet simple mixture of policies to address this concern, allowing us to optimize an objective that simultaneously maximizes and minimizes the surprise. Concretely, we train one mixture component whose objective is to maximize the surprise and another whose objective is to minimize the surprise. Hence, our method does not make assumptions about the entropy of the environment's dynamics. We call our method a $\textbf{M}\text{ixture }\textbf{O}\text{f }\textbf{S}\text{urprise}\textbf{S}$ (MOSS) for unsupervised reinforcement learning. Experimental results show that our simple method achieves state-of-the-art performance on the URLB benchmark, outperforming previous pure surprise maximization-based objectives. Our code is available at: https://github.com/LeapLabTHU/MOSS.