 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOAT: Ordered Action Tokenization
Feb 04, 2026Autoregressive policies offer a compelling foundation for scalable robot learning by enabling discrete abstraction, token-level reasoning, and flexible inference. However, applying autoregressive modeling to continuous robot actions requires an effective action tokenization scheme. Existing approaches either rely on analytical discretization methods that produce prohibitively long token sequences, or learned latent tokenizers that lack structure, limiting their compatibility with next-token prediction. In this work, we identify three desiderata for action tokenization - high compression, total decodability, and a left-to-right causally ordered token space - and introduce Ordered Action Tokenization (OAT), a learned action tokenizer that satisfies all three. OAT discretizes action chunks into an ordered sequence of tokens using transformer with registers, finite scalar quantization, and ordering-inducing training mechanisms. The resulting token space aligns naturally with autoregressive generation and enables prefix-based detokenization, yielding an anytime trade-off between inference cost and action fidelity. Across more than 20 tasks spanning four simulation benchmarks and real-world settings, autoregressive policies equipped with OAT consistently outperform prior tokenization schemes and diffusion-based baselines, while offering significantly greater flexibility at inference time.
ASAP: Aligning Simulation and Real-World Physics for Learning Agile Humanoid Whole-Body Skills
Feb 03, 2025Humanoid robots hold the potential for unparalleled versatility in performing human-like, whole-body skills. However, achieving agile and coordinated whole-body motions remains a significant challenge due to the dynamics mismatch between simulation and the real world. Existing approaches, such as system identification (SysID) and domain randomization (DR) methods, often rely on labor-intensive parameter tuning or result in overly conservative policies that sacrifice agility. In this paper, we present ASAP (Aligning Simulation and Real-World Physics), a two-stage framework designed to tackle the dynamics mismatch and enable agile humanoid whole-body skills. In the first stage, we pre-train motion tracking policies in simulation using retargeted human motion data. In the second stage, we deploy the policies in the real world and collect real-world data to train a delta (residual) action model that compensates for the dynamics mismatch. Then, ASAP fine-tunes pre-trained policies with the delta action model integrated into the simulator to align effectively with real-world dynamics. We evaluate ASAP across three transfer scenarios: IsaacGym to IsaacSim, IsaacGym to Genesis, and IsaacGym to the real-world Unitree G1 humanoid robot. Our approach significantly improves agility and whole-body coordination across various dynamic motions, reducing tracking error compared to SysID, DR, and delta dynamics learning baselines. ASAP enables highly agile motions that were previously difficult to achieve, demonstrating the potential of delta action learning in bridging simulation and real-world dynamics. These results suggest a promising sim-to-real direction for developing more expressive and agile humanoids.
A microwave photonic prototype for concurrent radar detection and spectrum sensing over an 8 to 40 GHz bandwidth
Jun 20, 2024



In this work, a microwave photonic prototype for concurrent radar detection and spectrum sensing is proposed, designed, built, and investigated. A direct digital synthesizer and an analog electronic circuit are integrated to generate an intermediate frequency (IF) linearly frequency-modulated (LFM) signal with a tunable center frequency from 2.5 to 9.5 GHz and an instantaneous bandwidth of 1 GHz. The IF LFM signal is converted to the optical domain via an intensity modulator and then filtered by a fiber Bragg grating (FBG) to generate only two 2nd-order optical LFM sidebands. In radar detection, the two optical LFM sidebands beat with each other to generate a frequency-and-bandwidth-quadrupled LFM signal, which is used for ranging, radial velocity measurement, and imaging. By changing the center frequency of the IF LFM signal, the radar function can be operated within 8 to 40 GHz. In spectrum sensing, one 2nd-order optical LFM sideband is selected by another FBG, which then works in conjunction with the stimulated Brillouin scattering gain spectrum to map the frequency of the signal under test to time with an instantaneous measurement bandwidth of 2 GHz. By using a frequency shift module to adjust the pump frequency, the frequency measurement range can be adjusted from 0 to 40 GHz. The prototype is comprehensively studied and tested, which is capable of achieving a range resolution of 3.75 cm, a range error of less than $\pm$ 2 cm, a radial velocity error within $\pm$ 1 cm/s, delivering clear imaging of multiple small targets, and maintaining a frequency measurement error of less than $\pm$ 7 MHz and a frequency resolution of better than 20 MHz.
CooHOI: Learning Cooperative Human-Object Interaction with Manipulated Object Dynamics
Jun 20, 2024
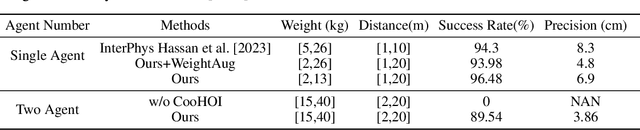
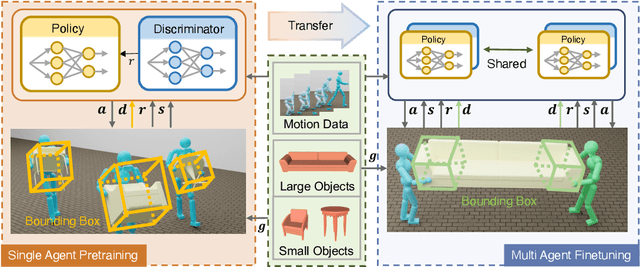
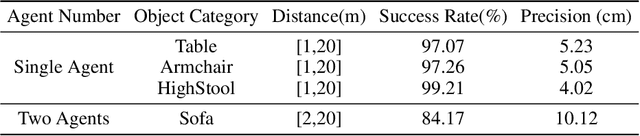
Recent years have seen significant advancements in humanoid control, largely due to the availability of large-scale motion capture data and the application of reinforcement learning methodologies. However, many real-world tasks, such as moving large and heavy furniture, require multi-character collaboration. Given the scarcity of data on multi-character collaboration and the efficiency challenges associated with multi-agent learning, these tasks cannot be straightforwardly addressed using training paradigms designed for single-agent scenarios. In this paper, we introduce Cooperative Human-Object Interaction (CooHOI), a novel framework that addresses multi-character objects transporting through a two-phase learning paradigm: individual skill acquisition and subsequent transfer. Initially, a single agent learns to perform tasks using the Adversarial Motion Priors (AMP) framework. Following this, the agent learns to collaborate with others by considering the shared dynamics of the manipulated object during parallel training using Multi Agent Proximal Policy Optimization (MAPPO). When one agent interacts with the object, resulting in specific object dynamics changes, the other agents learn to respond appropriately, thereby achieving implicit communication and coordination between teammates. Unlike previous approaches that relied on tracking-based methods for multi-character HOI, CooHOI is inherently efficient, does not depend on motion capture data of multi-character interactions, and can be seamlessly extended to include more participants and a wide range of object types
Hybrid Internal Model: Learning Agile Legged Locomotion with Simulated Robot Response
Jan 02, 2024Robust locomotion control depends on accurate state estimations. However, the sensors of most legged robots can only provide partial and noisy observations, making the estimation particularly challenging, especially for external states like terrain frictions and elevation maps. Inspired by the classical Internal Model Control principle, we consider these external states as disturbances and introduce Hybrid Internal Model (HIM) to estimate them according to the response of the robot. The response, which we refer to as the hybrid internal embedding, contains the robot's explicit velocity and implicit stability representation, corresponding to two primary goals for locomotion tasks: explicitly tracking velocity and implicitly maintaining stability. We use contrastive learning to optimize the embedding to be close to the robot's successor state, in which the response is naturally embedded. HIM has several appealing benefits: It only needs the robot's proprioceptions, i.e., those from joint encoders and IMU as observations. It innovatively maintains consistent observations between simulation reference and reality that avoids information loss in mimicking learning. It exploits batch-level information that is more robust to noises and keeps better sample efficiency. It only requires 1 hour of training on an RTX 4090 to enable a quadruped robot to traverse any terrain under any disturbances. A wealth of real-world experiments demonstrates its agility, even in high-difficulty tasks and cases never occurred during the training process, revealing remarkable open-world generalizability.
Train Once, Get a Family: State-Adaptive Balances for Offline-to-Online Reinforcement Learning
Oct 30, 2023Offline-to-online reinforcement learning (RL) is a training paradigm that combines pre-training on a pre-collected dataset with fine-tuning in an online environment. However, the incorporation of online fine-tuning can intensify the well-known distributional shift problem. Existing solutions tackle this problem by imposing a policy constraint on the policy improvement objective in both offline and online learning. They typically advocate a single balance between policy improvement and constraints across diverse data collections. This one-size-fits-all manner may not optimally leverage each collected sample due to the significant variation in data quality across different states. To this end, we introduce Family Offline-to-Online RL (FamO2O), a simple yet effective framework that empowers existing algorithms to determine state-adaptive improvement-constraint balances. FamO2O utilizes a universal model to train a family of policies with different improvement/constraint intensities, and a balance model to select a suitable policy for each state. Theoretically, we prove that state-adaptive balances are necessary for achieving a higher policy performance upper bound. Empirically, extensive experiments show that FamO2O offers a statistically significant improvement over various existing methods, achieving state-of-the-art performance on the D4RL benchmark. Codes are available at https://github.com/LeapLabTHU/FamO2O.
The Computational Complexity of Fire Emblem Series and similar Tactical Role-Playing Games
Sep 25, 2019
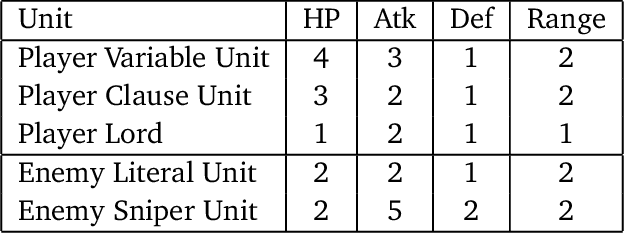
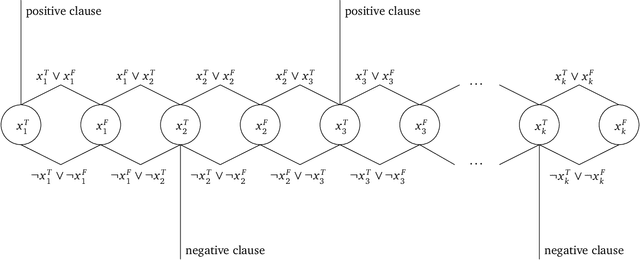
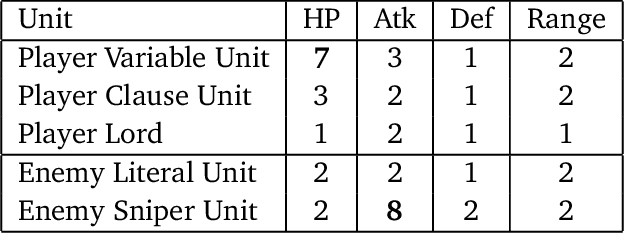
Fire Emblem (FE) is a popular turn-based tactical role-playing game (TRPG) series on the Nintendo gaming consoles. This paper studies the computational complexity of a simplified version of FE (only floor tiles and wall tiles, the HP and other attributes of characters are constants at most 8, the movement distance per character each turn is fixed to 6 tiles), and proves that: 1. Simplified FE is PSPACE-complete (Thus actual FE is at least as hard). 2. Poly-round FE is NP-complete, even when the map is cycle-free, without healing units, and the weapon durability is a small constant. Poly-round FE is to decide whether the player can win the game in a certain number of rounds that is polynomial to the map size. A map is called cycle-free if its corresponding planar graph is cycle-free. These hardness results also hold for other similar TRPG series, such as Final Fantasy Tactics, Tactics Ogre and Disgaea.