 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPLF-SAM: Self-Prompting Segment Anything Model for Light Field Salient Object Detection
Aug 27, 2025Segment Anything Model (SAM) has demonstrated remarkable capabilities in solving light field salient object detection (LF SOD). However, most existing models tend to neglect the extraction of prompt information under this task. Meanwhile, traditional models ignore the analysis of frequency-domain information, which leads to small objects being overwhelmed by noise. In this paper, we put forward a novel model called self-prompting light field segment anything model (SPLF-SAM), equipped with unified multi-scale feature embedding block (UMFEB) and a multi-scale adaptive filtering adapter (MAFA). UMFEB is capable of identifying multiple objects of varying sizes, while MAFA, by learning frequency features, effectively prevents small objects from being overwhelmed by noise. Extensive experiments have demonstrated the superiority of our method over ten state-of-the-art (SOTA) LF SOD methods. Our code will be available at https://github.com/XucherCH/splfsam.
AirSwarm: Enabling Cost-Effective Multi-UAV Research with COTS drones
Mar 10, 2025Traditional unmanned aerial vehicle (UAV) swarm missions rely heavily on expensive custom-made drones with onboard perception or external positioning systems, limiting their widespread adoption in research and education. To address this issue, we propose AirSwarm. AirSwarm democratizes multi-drone coordination using low-cost commercially available drones such as Tello or Anafi, enabling affordable swarm aerial robotics research and education. Key innovations include a hierarchical control architecture for reliable multi-UAV coordination, an infrastructure-free visual SLAM system for precise localization without external motion capture, and a ROS-based software framework for simplified swarm development. Experiments demonstrate cm-level tracking accuracy, low-latency control, communication failure resistance, formation flight, and trajectory tracking. By reducing financial and technical barriers, AirSwarm makes multi-robot education and research more accessible. The complete instructions and open source code will be available at
PAPI: Exploiting Dynamic Parallelism in Large Language Model Decoding with a Processing-In-Memory-Enabled Computing System
Feb 21, 2025Large language models (LLMs) are widely used for natural language understanding and text generation. An LLM model relies on a time-consuming step called LLM decoding to generate output tokens. Several prior works focus on improving the performance of LLM decoding using parallelism techniques, such as batching and speculative decoding. State-of-the-art LLM decoding has both compute-bound and memory-bound kernels. Some prior works statically identify and map these different kernels to a heterogeneous architecture consisting of both processing-in-memory (PIM) units and computation-centric accelerators. We observe that characteristics of LLM decoding kernels (e.g., whether or not a kernel is memory-bound) can change dynamically due to parameter changes to meet user and/or system demands, making (1) static kernel mapping to PIM units and computation-centric accelerators suboptimal, and (2) one-size-fits-all approach of designing PIM units inefficient due to a large degree of heterogeneity even in memory-bound kernels. In this paper, we aim to accelerate LLM decoding while considering the dynamically changing characteristics of the kernels involved. We propose PAPI (PArallel Decoding with PIM), a PIM-enabled heterogeneous architecture that exploits dynamic scheduling of compute-bound or memory-bound kernels to suitable hardware units. PAPI has two key mechanisms: (1) online kernel characterization to dynamically schedule kernels to the most suitable hardware units at runtime and (2) a PIM-enabled heterogeneous computing system that harmoniously orchestrates both computation-centric processing units and hybrid PIM units with different computing capabilities. Our experimental results on three broadly-used LLMs show that PAPI achieves 1.8$\times$ and 11.1$\times$ speedups over a state-of-the-art heterogeneous LLM accelerator and a state-of-the-art PIM-only LLM accelerator, respectively.
COMET: Towards Partical W4A4KV4 LLMs Serving
Oct 16, 2024



Quantization is a widely-used compression technology to reduce the overhead of serving large language models (LLMs) on terminal devices and in cloud data centers. However, prevalent quantization methods, such as 8-bit weight-activation or 4-bit weight-only quantization, achieve limited performance improvements due to poor support for low-precision (e.g., 4-bit) activation. This work, for the first time, realizes practical W4A4KV4 serving for LLMs, fully utilizing the INT4 tensor cores on modern GPUs and reducing the memory bottleneck caused by the KV cache. Specifically, we propose a novel fine-grained mixed-precision quantization algorithm (FMPQ) that compresses most activations into 4-bit with negligible accuracy loss. To support mixed-precision matrix multiplication for W4A4 and W4A8, we develop a highly optimized W4Ax kernel. Our approach introduces a novel mixed-precision data layout to facilitate access and fast dequantization for activation and weight tensors, utilizing the GPU's software pipeline to hide the overhead of data loading and conversion. Additionally, we propose fine-grained streaming multiprocessor (SM) scheduling to achieve load balance across different SMs. We integrate the optimized W4Ax kernel into our inference framework, COMET, and provide efficient management to support popular LLMs such as LLaMA-3-70B. Extensive evaluations demonstrate that, when running LLaMA family models on a single A100-80G-SMX4, COMET achieves a kernel-level speedup of \textbf{$2.88\times$} over cuBLAS and a \textbf{$2.02 \times$} throughput improvement compared to TensorRT-LLM from an end-to-end framework perspective.
IICPilot: An Intelligent Integrated Circuit Backend Design Framework Using Open EDA
Jul 17, 2024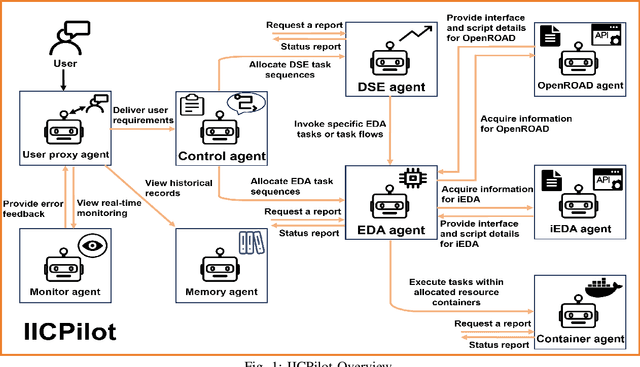

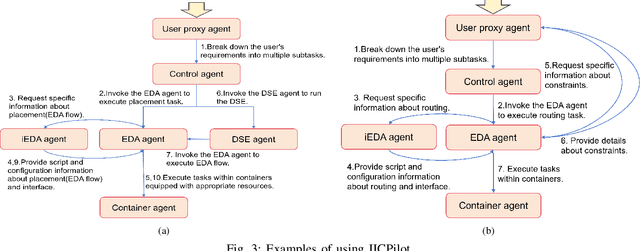

Open-source EDA tools are rapidly advancing, fostering collaboration, innovation, and knowledge sharing within the EDA community. However, the growing complexity of these tools, characterized by numerous design parameters and heuristics, poses a significant barrier to their widespread adoption. This complexity is particularly pronounced in integrated circuit (IC) backend designs, which place substantial demands on engineers' expertise in EDA tools. To tackle this challenge, we introduce IICPilot, an intelligent IC backend design system based on LLM technology. IICPilot automates various backend design procedures, including script generation, EDA tool invocation, design space exploration of EDA parameters, container-based computing resource allocation, and exception management. By automating these tasks, IICPilot significantly lowers the barrier to entry for open-source EDA tools. Specifically, IICPilot utilizes LangChain's multi-agent framework to efficiently handle distinct design tasks, enabling flexible enhancements independently. Moreover, IICPilot separates the backend design workflow from specific open-source EDA tools through a unified EDA calling interface. This approach allows seamless integration with different open-source EDA tools like OpenROAD and iEDA, streamlining the backend design and optimization across the EDA tools.
A microwave photonic prototype for concurrent radar detection and spectrum sensing over an 8 to 40 GHz bandwidth
Jun 20, 2024



In this work, a microwave photonic prototype for concurrent radar detection and spectrum sensing is proposed, designed, built, and investigated. A direct digital synthesizer and an analog electronic circuit are integrated to generate an intermediate frequency (IF) linearly frequency-modulated (LFM) signal with a tunable center frequency from 2.5 to 9.5 GHz and an instantaneous bandwidth of 1 GHz. The IF LFM signal is converted to the optical domain via an intensity modulator and then filtered by a fiber Bragg grating (FBG) to generate only two 2nd-order optical LFM sidebands. In radar detection, the two optical LFM sidebands beat with each other to generate a frequency-and-bandwidth-quadrupled LFM signal, which is used for ranging, radial velocity measurement, and imaging. By changing the center frequency of the IF LFM signal, the radar function can be operated within 8 to 40 GHz. In spectrum sensing, one 2nd-order optical LFM sideband is selected by another FBG, which then works in conjunction with the stimulated Brillouin scattering gain spectrum to map the frequency of the signal under test to time with an instantaneous measurement bandwidth of 2 GHz. By using a frequency shift module to adjust the pump frequency, the frequency measurement range can be adjusted from 0 to 40 GHz. The prototype is comprehensively studied and tested, which is capable of achieving a range resolution of 3.75 cm, a range error of less than $\pm$ 2 cm, a radial velocity error within $\pm$ 1 cm/s, delivering clear imaging of multiple small targets, and maintaining a frequency measurement error of less than $\pm$ 7 MHz and a frequency resolution of better than 20 MHz.
Detection of Acetone as a Gas Biomarker for Diabetes Based on Gas Sensor Technology
Jun 03, 2024

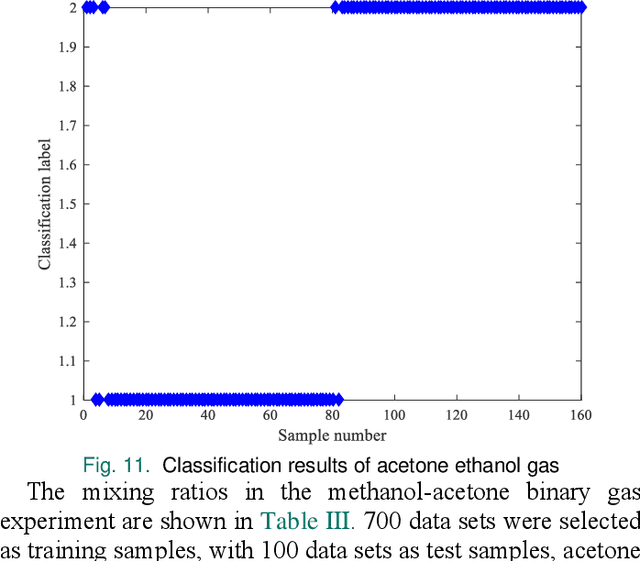

With the continuous development and improvement of medical services, there is a growing demand for improving diabetes diagnosis. Exhaled breath analysis, characterized by its speed, convenience, and non-invasive nature, is leading the trend in diagnostic development. Studies have shown that the acetone levels in the breath of diabetes patients are higher than normal, making acetone a basis for diabetes breath analysis. This provides a more readily accepted method for early diabetes prevention and monitoring. Addressing issues such as the invasive nature, disease transmission risks, and complexity of diabetes testing, this study aims to design a diabetes gas biomarker acetone detection system centered around a sensor array using gas sensors and pattern recognition algorithms. The research covers sensor selection, sensor preparation, circuit design, data acquisition and processing, and detection model establishment to accurately identify acetone. Titanium dioxide was chosen as the nano gas-sensitive material to prepare the acetone gas sensor, with data collection conducted using STM32. Filtering was applied to process the raw sensor data, followed by feature extraction using principal component analysis. A recognition model based on support vector machine algorithm was used for qualitative identification of gas samples, while a recognition model based on backpropagation neural network was employed for quantitative detection of gas sample concentrations. Experimental results demonstrated recognition accuracies of 96% and 97.5% for acetone-ethanol and acetone-methanol mixed gases, and 90% for ternary acetone, ethanol, and methanol mixed gases.
Data is all you need: Finetuning LLMs for Chip Design via an Automated design-data augmentation framework
Mar 17, 2024
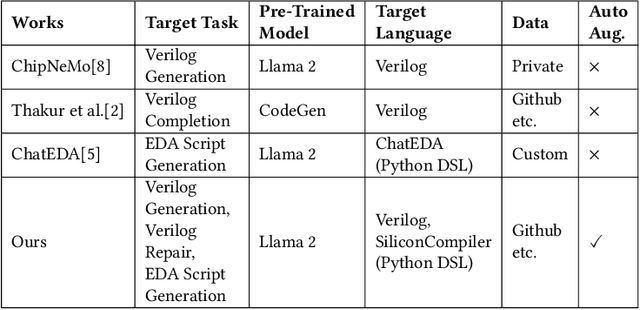


Recent advances in large language models have demonstrated their potential for automated generation of hardware description language (HDL) code from high-level prompts. Researchers have utilized fine-tuning to enhance the ability of these large language models (LLMs) in the field of Chip Design. However, the lack of Verilog data hinders further improvement in the quality of Verilog generation by LLMs. Additionally, the absence of a Verilog and Electronic Design Automation (EDA) script data augmentation framework significantly increases the time required to prepare the training dataset for LLM trainers. This paper proposes an automated design-data augmentation framework, which generates high-volume and high-quality natural language aligned with Verilog and EDA scripts. For Verilog generation, it translates Verilog files to an abstract syntax tree and then maps nodes to natural language with a predefined template. For Verilog repair, it uses predefined rules to generate the wrong verilog file and then pairs EDA Tool feedback with the right and wrong verilog file. For EDA Script generation, it uses existing LLM(GPT-3.5) to obtain the description of the Script. To evaluate the effectiveness of our data augmentation method, we finetune Llama2-13B and Llama2-7B models using the dataset generated by our augmentation framework. The results demonstrate a significant improvement in the Verilog generation tasks with LLMs. Moreover, the accuracy of Verilog generation surpasses that of the current state-of-the-art open-source Verilog generation model, increasing from 58.8% to 70.6% with the same benchmark. Our 13B model (ChipGPT-FT) has a pass rate improvement compared with GPT-3.5 in Verilog generation and outperforms in EDA script (i.e., SiliconCompiler) generation with only 200 EDA script data.
ROG$_{PL}$: Robust Open-Set Graph Learning via Region-Based Prototype Learning
Feb 29, 2024



Open-set graph learning is a practical task that aims to classify the known class nodes and to identify unknown class samples as unknowns. Conventional node classification methods usually perform unsatisfactorily in open-set scenarios due to the complex data they encounter, such as out-of-distribution (OOD) data and in-distribution (IND) noise. OOD data are samples that do not belong to any known classes. They are outliers if they occur in training (OOD noise), and open-set samples if they occur in testing. IND noise are training samples which are assigned incorrect labels. The existence of IND noise and OOD noise is prevalent, which usually cause the ambiguity problem, including the intra-class variety problem and the inter-class confusion problem. Thus, to explore robust open-set learning methods is necessary and difficult, and it becomes even more difficult for non-IID graph data.To this end, we propose a unified framework named ROG$_{PL}$ to achieve robust open-set learning on complex noisy graph data, by introducing prototype learning. In specific, ROG$_{PL}$ consists of two modules, i.e., denoising via label propagation and open-set prototype learning via regions. The first module corrects noisy labels through similarity-based label propagation and removes low-confidence samples, to solve the intra-class variety problem caused by noise. The second module learns open-set prototypes for each known class via non-overlapped regions and remains both interior and border prototypes to remedy the inter-class confusion problem.The two modules are iteratively updated under the constraints of classification loss and prototype diversity loss. To the best of our knowledge, the proposed ROG$_{PL}$ is the first robust open-set node classification method for graph data with complex noise.
Cross-Layer Optimization for Fault-Tolerant Deep Learning
Dec 21, 2023Fault-tolerant deep learning accelerator is the basis for highly reliable deep learning processing and critical to deploy deep learning in safety-critical applications such as avionics and robotics. Since deep learning is known to be computing- and memory-intensive, traditional fault-tolerant approaches based on redundant computing will incur substantial overhead including power consumption and chip area. To this end, we propose to characterize deep learning vulnerability difference across both neurons and bits of each neuron, and leverage the vulnerability difference to enable selective protection of the deep learning processing components from the perspective of architecture layer and circuit layer respectively. At the same time, we observe the correlation between model quantization and bit protection overhead of the underlying processing elements of deep learning accelerators, and propose to reduce the bit protection overhead by adding additional quantization constrain without compromising the model accuracy. Finally, we employ Bayesian optimization strategy to co-optimize the correlated cross-layer design parameters at algorithm layer, architecture layer, and circuit layer to minimize the hardware resource consumption while fulfilling multiple user constraints including reliability, accuracy, and performance of the deep learning processing at the same time.