 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWrong Code, Right Structure: Learning Netlist Representations from Imperfect LLM-Generated RTL
Mar 10, 2026Learning effective netlist representations is fundamentally constrained by the scarcity of labeled datasets, as real designs are protected by Intellectual Property (IP) and costly to annotate. Existing work therefore focuses on small-scale circuits with clean labels, limiting scalability to realistic designs. Meanwhile, Large Language Models (LLMs) can generate Register-Transfer-Level (RTL) at scale, but their functional incorrectness has hindered their use in circuit analysis. In this work, we make a key observation: even when LLM-Generated RTL is functionally imperfect, the synthesized netlists still preserve structural patterns that are strongly indicative of the intended functionality. Building on this insight, we propose a cost-effective data augmentation and training framework that systematically exploits imperfect LLM-Generated RTL as training data for netlist representation learning, forming an end-to-end pipeline from automated code generation to downstream tasks. We conduct evaluations on circuit functional understanding tasks, including sub-circuit boundary identification and component classification, across benchmarks of increasing scales, extending the task scope from operator-level to IP-level. The evaluations demonstrate that models trained on our noisy synthetic corpus generalize well to real-world netlists, matching or even surpassing methods trained on scarce high-quality data and effectively breaking the data bottleneck in circuit representation learning.
TriMoE: Augmenting GPU with AMX-Enabled CPU and DIMM-NDP for High-Throughput MoE Inference via Offloading
Mar 01, 2026To deploy large Mixture-of-Experts (MoE) models cost-effectively, offloading-based single-GPU heterogeneous inference is crucial. While GPU-CPU architectures that offload cold experts are constrained by host memory bandwidth, emerging GPU-NDP architectures utilize DIMM-NDP to offload non-hot experts. However, non-hot experts are not a homogeneous memory-bound group: a significant subset of warm experts exists is severely penalized by high GPU I/O latency yet can saturate NDP compute throughput, exposing a critical compute gap. We present TriMoE, a novel GPU-CPU-NDP architecture that fills this gap by synergistically leveraging AMX-enabled CPU to precisely map hot, warm, and cold experts onto their optimal compute units. We further introduce a bottleneck-aware expert scheduling policy and a prediction-driven dynamic relayout/rebalancing scheme. Experiments demonstrate that TriMoE achieves up to 2.83x speedup over state-of-the-art solutions.
From Buffers to Registers: Unlocking Fine-Grained FlashAttention with Hybrid-Bonded 3D NPU Co-Design
Feb 11, 2026Transformer-based models dominate modern AI workloads but exacerbate memory bottlenecks due to their quadratic attention complexity and ever-growing model sizes. Existing accelerators, such as Groq and Cerebras, mitigate off-chip traffic with large on-chip caches, while algorithmic innovations such as FlashAttention fuse operators to avoid materializing large attention matrices. However, as off-chip traffic decreases, our measurements show that on-chip SRAM accesses account for over 60% of energy in long-sequence workloads, making cache access the new bottleneck. We propose 3D-Flow, a hybrid-bonded, 3D-stacked spatial accelerator that enables register-to-register communication across vertically partitioned PE tiers. Unlike 2D multi-array architectures limited by NoC-based router-to-router transfers, 3D-Flow leverages sub-10 um vertical TSVs to sustain cycle-level operator pipelining with minimal overhead. On top of this architecture, we design 3D-FlashAttention, a fine-grained scheduling method that balances latency across tiers, forming a bubble-free vertical dataflow without on-chip SRAM roundtrips. Evaluations on Transformer workloads (OPT and QWEN models) show that our 3D spatial accelerator reduces 46-93% energy consumption and achieves 1.4x-7.6x speedups compared to state-of-the-art 2D and 3D designs.
ODMA: On-Demand Memory Allocation Framework for LLM Serving on LPDDR-Class Accelerators
Dec 10, 2025Serving large language models (LLMs) on accelerators with poor random-access bandwidth (e.g., LPDDR5-based) is limited by current memory managers. Static pre-allocation wastes memory, while fine-grained paging (e.g., PagedAttention) is ill-suited due to high random-access costs. Existing HBM-centric solutions do not exploit the characteristics of random-access-constrained memory (RACM) accelerators like Cambricon MLU370. We present ODMA, an on-demand memory allocation framework for RACM. ODMA addresses distribution drift and heavy-tailed requests by coupling a lightweight length predictor with dynamic bucket partitioning and a large-bucket safeguard. Boundaries are periodically updated from live traces to maximize utilization. On Alpaca and Google-NQ, ODMA improves prediction accuracy of prior work significantly (e.g., from 82.68% to 93.36%). Serving DeepSeek-R1-Distill-Qwen-7B on Cambricon MLU370-X4, ODMA raises memory utilization from 55.05% to 72.45% and improves RPS and TPS by 29% and 27% over static baselines. This demonstrates that hardware-aware allocation unlocks efficient LLM serving on RACM platforms.
ANNIE: Be Careful of Your Robots
Sep 03, 2025



The integration of vision-language-action (VLA) models into embodied AI (EAI) robots is rapidly advancing their ability to perform complex, long-horizon tasks in humancentric environments. However, EAI systems introduce critical security risks: a compromised VLA model can directly translate adversarial perturbations on sensory input into unsafe physical actions. Traditional safety definitions and methodologies from the machine learning community are no longer sufficient. EAI systems raise new questions, such as what constitutes safety, how to measure it, and how to design effective attack and defense mechanisms in physically grounded, interactive settings. In this work, we present the first systematic study of adversarial safety attacks on embodied AI systems, grounded in ISO standards for human-robot interactions. We (1) formalize a principled taxonomy of safety violations (critical, dangerous, risky) based on physical constraints such as separation distance, velocity, and collision boundaries; (2) introduce ANNIEBench, a benchmark of nine safety-critical scenarios with 2,400 video-action sequences for evaluating embodied safety; and (3) ANNIE-Attack, a task-aware adversarial framework with an attack leader model that decomposes long-horizon goals into frame-level perturbations. Our evaluation across representative EAI models shows attack success rates exceeding 50% across all safety categories. We further demonstrate sparse and adaptive attack strategies and validate the real-world impact through physical robot experiments. These results expose a previously underexplored but highly consequential attack surface in embodied AI systems, highlighting the urgent need for security-driven defenses in the physical AI era. Code is available at https://github.com/RLCLab/Annie.
KAITIAN: A Unified Communication Framework for Enabling Efficient Collaboration Across Heterogeneous Accelerators in Embodied AI Systems
May 15, 2025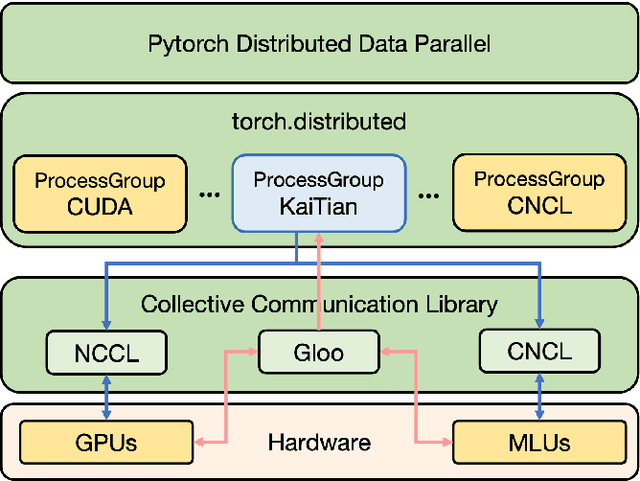
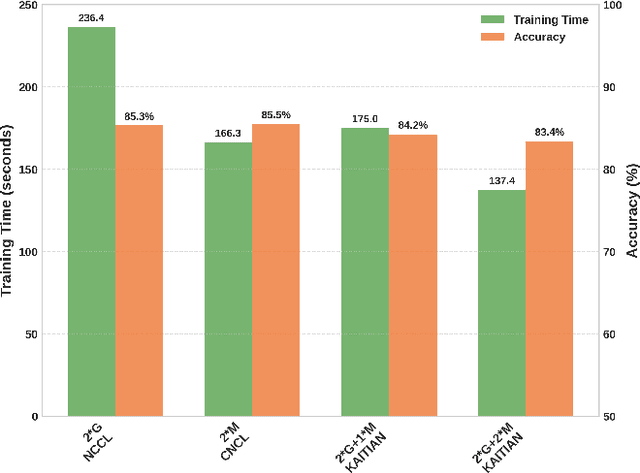
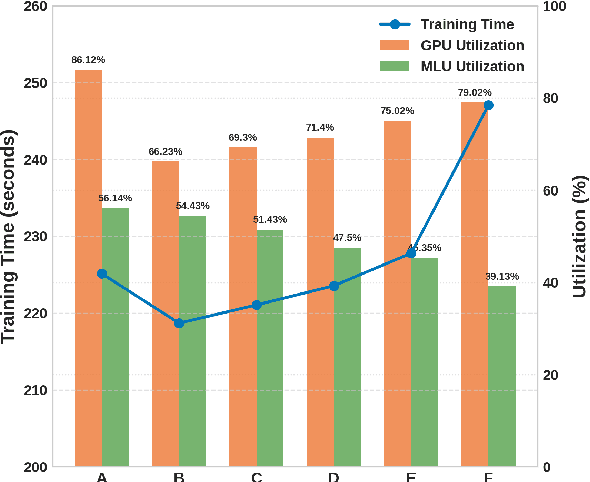
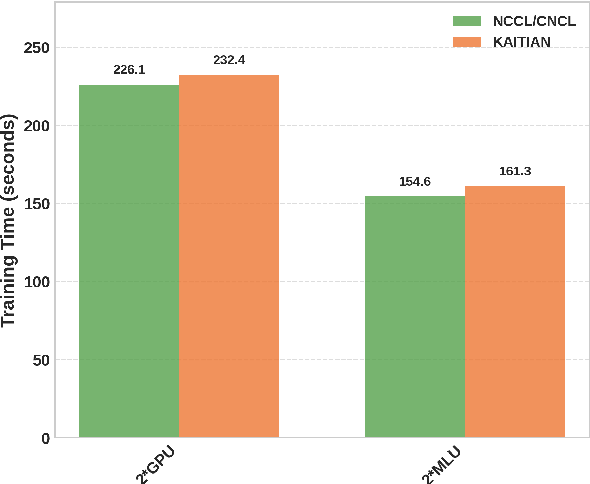
Embodied Artificial Intelligence (AI) systems, such as autonomous robots and intelligent vehicles, are increasingly reliant on diverse heterogeneous accelerators (e.g., GPGPUs, NPUs, FPGAs) to meet stringent real-time processing and energy-efficiency demands. However, the proliferation of vendor-specific proprietary communication libraries creates significant interoperability barriers, hindering seamless collaboration between different accelerator types and leading to suboptimal resource utilization and performance bottlenecks in distributed AI workloads. This paper introduces KAITIAN, a novel distributed communication framework designed to bridge this gap. KAITIAN provides a unified abstraction layer that intelligently integrates vendor-optimized communication libraries for intra-group efficiency with general-purpose communication protocols for inter-group interoperability. Crucially, it incorporates a load-adaptive scheduling mechanism that dynamically balances computational tasks across heterogeneous devices based on their real-time performance characteristics. Implemented as an extension to PyTorch and rigorously evaluated on a testbed featuring NVIDIA GPUs and Cambricon MLUs, KAITIAN demonstrates significant improvements in resource utilization and scalability for distributed training tasks. Experimental results show that KAITIAN can accelerate training time by up to 42% compared to baseline homogeneous systems, while incurring minimal communication overhead (2.8--4.3%) and maintaining model accuracy. KAITIAN paves the way for more flexible and powerful heterogeneous computing in complex embodied AI applications.
RTLMarker: Protecting LLM-Generated RTL Copyright via a Hardware Watermarking Framework
Jan 05, 2025



Recent advances of large language models in the field of Verilog generation have raised several ethical and security concerns, such as code copyright protection and dissemination of malicious code. Researchers have employed watermarking techniques to identify codes generated by large language models. However, the existing watermarking works fail to protect RTL code copyright due to the significant syntactic and semantic differences between RTL code and software code in languages such as Python. This paper proposes a hardware watermarking framework RTLMarker that embeds watermarks into RTL code and deeper into the synthesized netlist. We propose a set of rule-based Verilog code transformations , ensuring the watermarked RTL code's syntactic and semantic correctness. In addition, we consider an inherent tradeoff between watermark transparency and watermark effectiveness and jointly optimize them. The results demonstrate RTLMarker's superiority over the baseline in RTL code watermarking.
DaDu-E: Rethinking the Role of Large Language Model in Robotic Computing Pipeline
Dec 02, 2024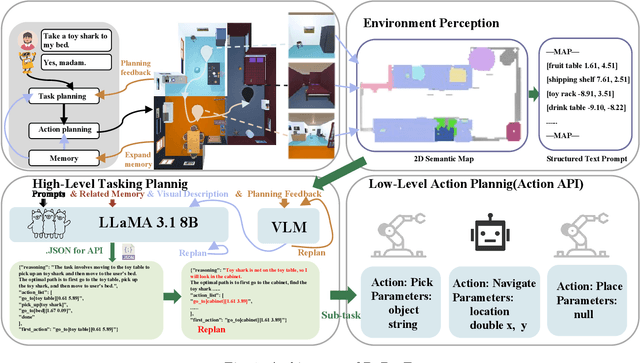



Performing complex tasks in open environments remains challenging for robots, even when using large language models (LLMs) as the core planner. Many LLM-based planners are inefficient due to their large number of parameters and prone to inaccuracies because they operate in open-loop systems. We think the reason is that only applying LLMs as planners is insufficient. In this work, we propose DaDu-E, a robust closed-loop planning framework for embodied AI robots. Specifically, DaDu-E is equipped with a relatively lightweight LLM, a set of encapsulated robot skill instructions, a robust feedback system, and memory augmentation. Together, these components enable DaDu-E to (i) actively perceive and adapt to dynamic environments, (ii) optimize computational costs while maintaining high performance, and (iii) recover from execution failures using its memory and feedback mechanisms. Extensive experiments on real-world and simulated tasks show that DaDu-E achieves task success rates comparable to embodied AI robots with larger models as planners like COME-Robot, while reducing computational requirements by $6.6 \times$. Users are encouraged to explore our system at: \url{https://rlc-lab.github.io/dadu-e/}.
COMET: Towards Partical W4A4KV4 LLMs Serving
Oct 16, 2024



Quantization is a widely-used compression technology to reduce the overhead of serving large language models (LLMs) on terminal devices and in cloud data centers. However, prevalent quantization methods, such as 8-bit weight-activation or 4-bit weight-only quantization, achieve limited performance improvements due to poor support for low-precision (e.g., 4-bit) activation. This work, for the first time, realizes practical W4A4KV4 serving for LLMs, fully utilizing the INT4 tensor cores on modern GPUs and reducing the memory bottleneck caused by the KV cache. Specifically, we propose a novel fine-grained mixed-precision quantization algorithm (FMPQ) that compresses most activations into 4-bit with negligible accuracy loss. To support mixed-precision matrix multiplication for W4A4 and W4A8, we develop a highly optimized W4Ax kernel. Our approach introduces a novel mixed-precision data layout to facilitate access and fast dequantization for activation and weight tensors, utilizing the GPU's software pipeline to hide the overhead of data loading and conversion. Additionally, we propose fine-grained streaming multiprocessor (SM) scheduling to achieve load balance across different SMs. We integrate the optimized W4Ax kernel into our inference framework, COMET, and provide efficient management to support popular LLMs such as LLaMA-3-70B. Extensive evaluations demonstrate that, when running LLaMA family models on a single A100-80G-SMX4, COMET achieves a kernel-level speedup of \textbf{$2.88\times$} over cuBLAS and a \textbf{$2.02 \times$} throughput improvement compared to TensorRT-LLM from an end-to-end framework perspective.
BitQ: Tailoring Block Floating Point Precision for Improved DNN Efficiency on Resource-Constrained Devices
Sep 25, 2024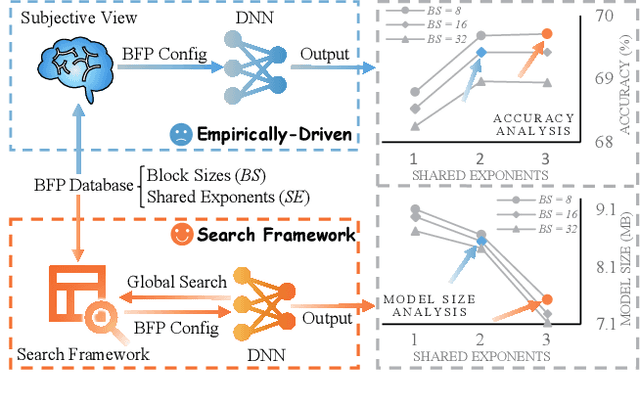
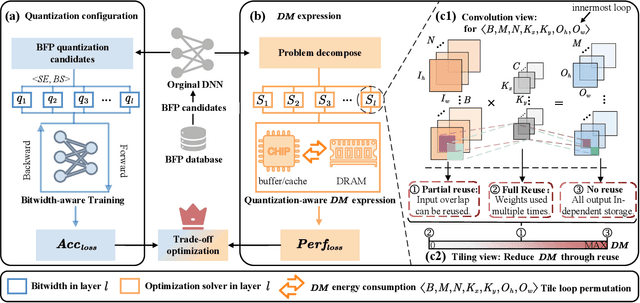

Deep neural networks (DNNs) are powerful for cognitive tasks such as image classification, object detection, and scene segmentation. One drawback however is the significant high computational complexity and memory consumption, which makes them unfeasible to run real-time on embedded platforms because of the limited hardware resources. Block floating point (BFP) quantization is one of the representative compression approaches for reducing the memory and computational burden owing to their capability to effectively capture the broad data distribution of DNN models. Unfortunately, prior works on BFP-based quantization empirically choose the block size and the precision that preserve accuracy. In this paper, we develop a BFP-based bitwidth-aware analytical modeling framework (called ``BitQ'') for the best BFP implementation of DNN inference on embedded platforms. We formulate and resolve an optimization problem to identify the optimal BFP block size and bitwidth distribution by the trade-off of both accuracy and performance loss. Experimental results show that compared with an equal bitwidth setting, the BFP DNNs with optimized bitwidth allocation provide efficient computation, preserving accuracy on famous benchmarks. The source code and data are available at https://github.com/Cheliosoops/BitQ.