 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTIMERIPPLE: Accelerating vDiTs by Understanding the Spatio-Temporal Correlations in Latent Space
Nov 15, 2025



The recent surge in video generation has shown the growing demand for high-quality video synthesis using large vision models. Existing video generation models are predominantly based on the video diffusion transformer (vDiT), however, they suffer from substantial inference delay due to self-attention. While prior studies have focused on reducing redundant computations in self-attention, they often overlook the inherent spatio-temporal correlations in video streams and directly leverage sparsity patterns from large language models to reduce attention computations. In this work, we take a principled approach to accelerate self-attention in vDiTs by leveraging the spatio-temporal correlations in the latent space. We show that the attention patterns within vDiT are primarily due to the dominant spatial and temporal correlations at the token channel level. Based on this insight, we propose a lightweight and adaptive reuse strategy that approximates attention computations by reusing partial attention scores of spatially or temporally correlated tokens along individual channels. We demonstrate that our method achieves significantly higher computational savings (85\%) compared to state-of-the-art techniques over 4 vDiTs, while preserving almost identical video quality ($<$0.06\% loss on VBench).
ANNIE: Be Careful of Your Robots
Sep 03, 2025The integration of vision-language-action (VLA) models into embodied AI (EAI) robots is rapidly advancing their ability to perform complex, long-horizon tasks in humancentric environments. However, EAI systems introduce critical security risks: a compromised VLA model can directly translate adversarial perturbations on sensory input into unsafe physical actions. Traditional safety definitions and methodologies from the machine learning community are no longer sufficient. EAI systems raise new questions, such as what constitutes safety, how to measure it, and how to design effective attack and defense mechanisms in physically grounded, interactive settings. In this work, we present the first systematic study of adversarial safety attacks on embodied AI systems, grounded in ISO standards for human-robot interactions. We (1) formalize a principled taxonomy of safety violations (critical, dangerous, risky) based on physical constraints such as separation distance, velocity, and collision boundaries; (2) introduce ANNIEBench, a benchmark of nine safety-critical scenarios with 2,400 video-action sequences for evaluating embodied safety; and (3) ANNIE-Attack, a task-aware adversarial framework with an attack leader model that decomposes long-horizon goals into frame-level perturbations. Our evaluation across representative EAI models shows attack success rates exceeding 50% across all safety categories. We further demonstrate sparse and adaptive attack strategies and validate the real-world impact through physical robot experiments. These results expose a previously underexplored but highly consequential attack surface in embodied AI systems, highlighting the urgent need for security-driven defenses in the physical AI era. Code is available at https://github.com/RLCLab/Annie.
DaDu-E: Rethinking the Role of Large Language Model in Robotic Computing Pipeline
Dec 02, 2024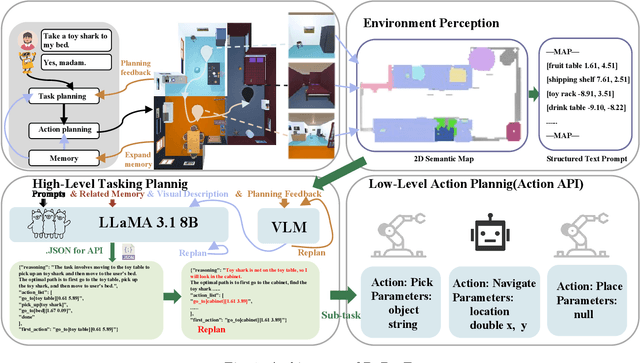



Performing complex tasks in open environments remains challenging for robots, even when using large language models (LLMs) as the core planner. Many LLM-based planners are inefficient due to their large number of parameters and prone to inaccuracies because they operate in open-loop systems. We think the reason is that only applying LLMs as planners is insufficient. In this work, we propose DaDu-E, a robust closed-loop planning framework for embodied AI robots. Specifically, DaDu-E is equipped with a relatively lightweight LLM, a set of encapsulated robot skill instructions, a robust feedback system, and memory augmentation. Together, these components enable DaDu-E to (i) actively perceive and adapt to dynamic environments, (ii) optimize computational costs while maintaining high performance, and (iii) recover from execution failures using its memory and feedback mechanisms. Extensive experiments on real-world and simulated tasks show that DaDu-E achieves task success rates comparable to embodied AI robots with larger models as planners like COME-Robot, while reducing computational requirements by $6.6 \times$. Users are encouraged to explore our system at: \url{https://rlc-lab.github.io/dadu-e/}.
VAP: The Vulnerability-Adaptive Protection Paradigm Toward Reliable Autonomous Machines
Sep 30, 2024



The next ubiquitous computing platform, following personal computers and smartphones, is poised to be inherently autonomous, encompassing technologies like drones, robots, and self-driving cars. Ensuring reliability for these autonomous machines is critical. However, current resiliency solutions make fundamental trade-offs between reliability and cost, resulting in significant overhead in performance, energy consumption, and chip area. This is due to the "one-size-fits-all" approach commonly used, where the same protection scheme is applied throughout the entire software computing stack. This paper presents the key insight that to achieve high protection coverage with minimal cost, we must leverage the inherent variations in robustness across different layers of the autonomous machine software stack. Specifically, we demonstrate that various nodes in this complex stack exhibit different levels of robustness against hardware faults. Our findings reveal that the front-end of an autonomous machine's software stack tends to be more robust, whereas the back-end is generally more vulnerable. Building on these inherent robustness differences, we propose a Vulnerability-Adaptive Protection (VAP) design paradigm. In this paradigm, the allocation of protection resources - whether spatially (e.g., through modular redundancy) or temporally (e.g., via re-execution) - is made inversely proportional to the inherent robustness of tasks or algorithms within the autonomous machine system. Experimental results show that VAP provides high protection coverage while maintaining low overhead in both autonomous vehicle and drone systems.
Corki: Enabling Real-time Embodied AI Robots via Algorithm-Architecture Co-Design
Jul 05, 2024



Embodied AI robots have the potential to fundamentally improve the way human beings live and manufacture. Continued progress in the burgeoning field of using large language models to control robots depends critically on an efficient computing substrate. In particular, today's computing systems for embodied AI robots are designed purely based on the interest of algorithm developers, where robot actions are divided into a discrete frame-basis. Such an execution pipeline creates high latency and energy consumption. This paper proposes Corki, an algorithm-architecture co-design framework for real-time embodied AI robot control. Our idea is to decouple LLM inference, robotic control and data communication in the embodied AI robots compute pipeline. Instead of predicting action for one single frame, Corki predicts the trajectory for the near future to reduce the frequency of LLM inference. The algorithm is coupled with a hardware that accelerates transforming trajectory into actual torque signals used to control robots and an execution pipeline that parallels data communication with computation. Corki largely reduces LLM inference frequency by up to 8.0x, resulting in up to 3.6x speed up. The success rate improvement can be up to 17.3%. Code is provided for re-implementation. https://github.com/hyy0613/Corki
Luban: Building Open-Ended Creative Agents via Autonomous Embodied Verification
May 24, 2024Building open agents has always been the ultimate goal in AI research, and creative agents are the more enticing. Existing LLM agents excel at long-horizon tasks with well-defined goals (e.g., `mine diamonds' in Minecraft). However, they encounter difficulties on creative tasks with open goals and abstract criteria due to the inability to bridge the gap between them, thus lacking feedback for self-improvement in solving the task. In this work, we introduce autonomous embodied verification techniques for agents to fill the gap, laying the groundwork for creative tasks. Specifically, we propose the Luban agent target creative building tasks in Minecraft, which equips with two-level autonomous embodied verification inspired by human design practices: (1) visual verification of 3D structural speculates, which comes from agent synthesized CAD modeling programs; (2) pragmatic verification of the creation by generating and verifying environment-relevant functionality programs based on the abstract criteria. Extensive multi-dimensional human studies and Elo ratings show that the Luban completes diverse creative building tasks in our proposed benchmark and outperforms other baselines ($33\%$ to $100\%$) in both visualization and pragmatism. Additional demos on the real-world robotic arm show the creation potential of the Luban in the physical world.
Thales: Formulating and Estimating Architectural Vulnerability Factors for DNN Accelerators
Dec 05, 2022



As Deep Neural Networks (DNNs) are increasingly deployed in safety critical and privacy sensitive applications such as autonomous driving and biometric authentication, it is critical to understand the fault-tolerance nature of DNNs. Prior work primarily focuses on metrics such as Failures In Time (FIT) rate and the Silent Data Corruption (SDC) rate, which quantify how often a device fails. Instead, this paper focuses on quantifying the DNN accuracy given that a transient error has occurred, which tells us how well a network behaves when a transient error occurs. We call this metric Resiliency Accuracy (RA). We show that existing RA formulation is fundamentally inaccurate, because it incorrectly assumes that software variables (model weights/activations) have equal faulty probability under hardware transient faults. We present an algorithm that captures the faulty probabilities of DNN variables under transient faults and, thus, provides correct RA estimations validated by hardware. To accelerate RA estimation, we reformulate RA calculation as a Monte Carlo integration problem, and solve it using importance sampling driven by DNN specific heuristics. Using our lightweight RA estimation method, we show that transient faults lead to far greater accuracy degradation than what todays DNN resiliency tools estimate. We show how our RA estimation tool can help design more resilient DNNs by integrating it with a Network Architecture Search framework.
TinyLSTMs: Efficient Neural Speech Enhancement for Hearing Aids
May 20, 2020
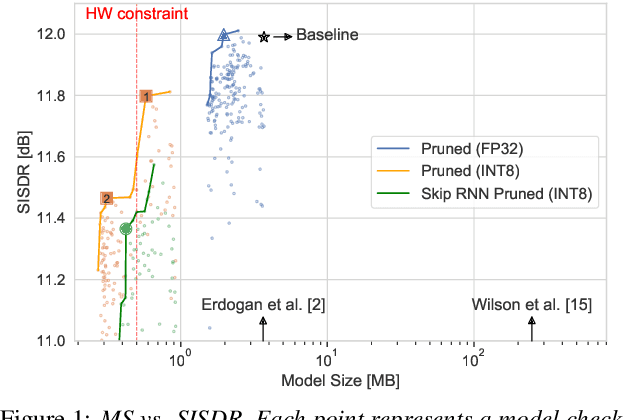
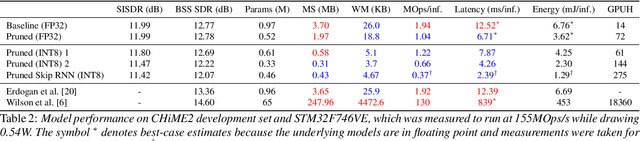
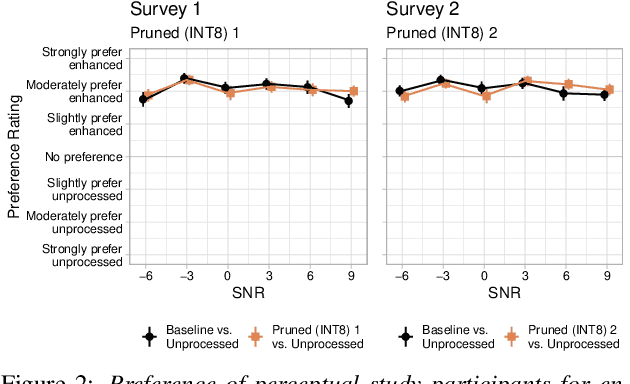
Modern speech enhancement algorithms achieve remarkable noise suppression by means of large recurrent neural networks (RNNs). However, large RNNs limit practical deployment in hearing aid hardware (HW) form-factors, which are battery powered and run on resource-constrained microcontroller units (MCUs) with limited memory capacity and compute capability. In this work, we use model compression techniques to bridge this gap. We define the constraints imposed on the RNN by the HW and describe a method to satisfy them. Although model compression techniques are an active area of research, we are the first to demonstrate their efficacy for RNN speech enhancement, using pruning and integer quantization of weights/activations. We also demonstrate state update skipping, which reduces the computational load. Finally, we conduct a perceptual evaluation of the compressed models to verify audio quality on human raters. Results show a reduction in model size and operations of 11.9$\times$ and 2.9$\times$, respectively, over the baseline for compressed models, without a statistical difference in listening preference and only exhibiting a loss of 0.55dB SDR. Our model achieves a computational latency of 2.39ms, well within the 10ms target and 351$\times$ better than previous work.