 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFSD50K-Solo: Automated Curation of Single-Source Sound Events
May 13, 2026High-quality training datasets are essential for the performance of neural networks. However, the audio domain still lacks a large-scale, strongly-labeled, and single-source sound event dataset. The FSD50K dataset, despite being relatively large and open, contains a considerable fraction of multi-source samples where background interference or overlapping events could limit the usefulness of the data. To address this challenge, we introduce a data curation framework designed for large-scale open audio corpora. Our approach leverages a generative diffusion model to synthesize clean single-class events to construct controlled noisy mixtures for supervision. We subsequently employ a pre-trained audio encoder coupled with a discriminative classifier to automatically identify and filter out multi-source samples. Experiments show that our framework achieves strong performance on a human expert-curated test set. Finally, we release FSD50K-Solo, a model-curated subset of FSD50K containing single-source audio samples identified by our method. Beyond FSD50K, our method establishes a scalable paradigm for curating open source audio corpora.
CCATMos: Convolutional Context-aware Transformer Network for Non-intrusive Speech Quality Assessment
Nov 04, 2022Speech quality assessment has been a critical component in many voice communication related applications such as telephony and online conferencing. Traditional intrusive speech quality assessment requires the clean reference of the degraded utterance to provide an accurate quality measurement. This requirement limits the usability of these methods in real-world scenarios. On the other hand, non-intrusive subjective measurement is the ``golden standard" in evaluating speech quality as human listeners can intrinsically evaluate the quality of any degraded speech with ease. In this paper, we propose a novel end-to-end model structure called Convolutional Context-Aware Transformer (CCAT) network to predict the mean opinion score (MOS) of human raters. We evaluate our model on three MOS-annotated datasets spanning multiple languages and distortion types and submit our results to the ConferencingSpeech 2022 Challenge. Our experiments show that CCAT provides promising MOS predictions compared to current state-of-art non-intrusive speech assessment models with average Pearson correlation coefficient (PCC) increasing from 0.530 to 0.697 and average RMSE decreasing from 0.768 to 0.570 compared to the baseline model on the challenge evaluation test set.
Self-Supervised Learning for Speech Enhancement through Synthesis
Nov 04, 2022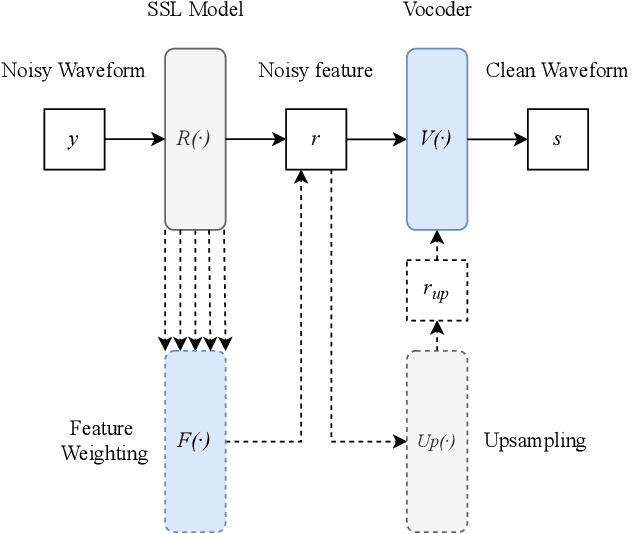
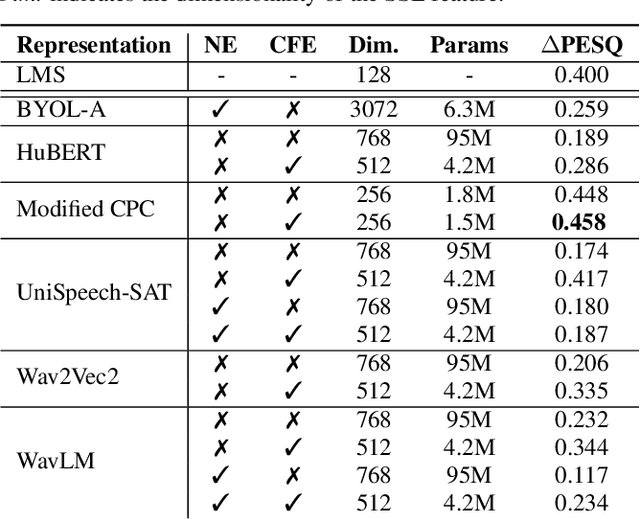
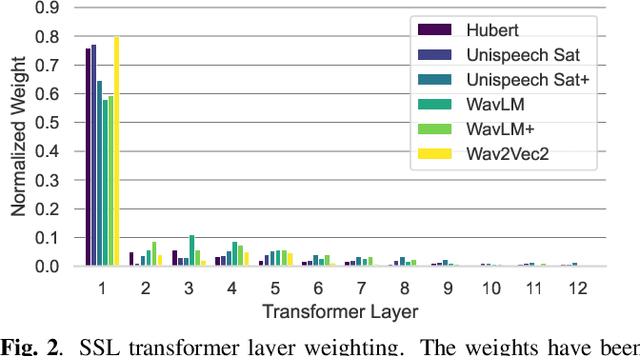
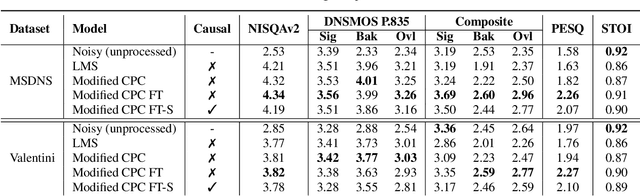
Modern speech enhancement (SE) networks typically implement noise suppression through time-frequency masking, latent representation masking, or discriminative signal prediction. In contrast, some recent works explore SE via generative speech synthesis, where the system's output is synthesized by a neural vocoder after an inherently lossy feature-denoising step. In this paper, we propose a denoising vocoder (DeVo) approach, where a vocoder accepts noisy representations and learns to directly synthesize clean speech. We leverage rich representations from self-supervised learning (SSL) speech models to discover relevant features. We conduct a candidate search across 15 potential SSL front-ends and subsequently train our vocoder adversarially with the best SSL configuration. Additionally, we demonstrate a causal version capable of running on streaming audio with 10ms latency and minimal performance degradation. Finally, we conduct both objective evaluations and subjective listening studies to show our system improves objective metrics and outperforms an existing state-of-the-art SE model subjectively.
Weight, Block or Unit? Exploring Sparsity Tradeoffs for Speech Enhancement on Tiny Neural Accelerators
Nov 09, 2021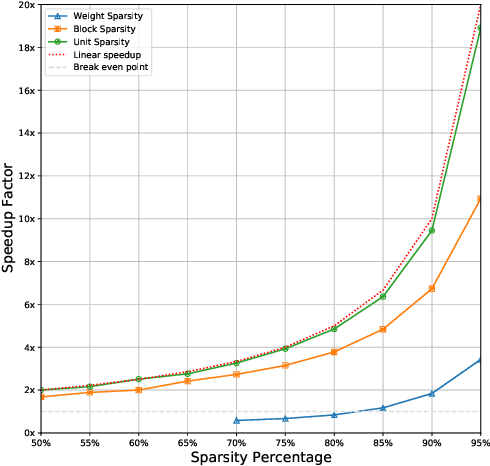
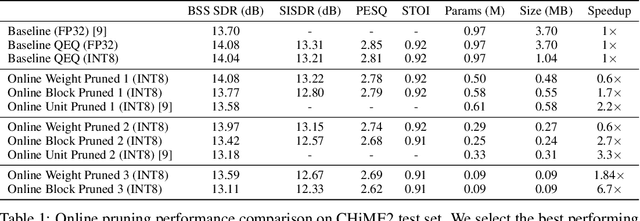
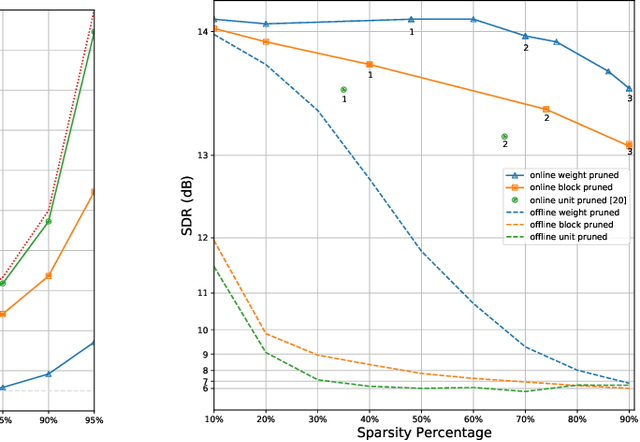

We explore network sparsification strategies with the aim of compressing neural speech enhancement (SE) down to an optimal configuration for a new generation of low power microcontroller based neural accelerators (microNPU's). We examine three unique sparsity structures: weight pruning, block pruning and unit pruning; and discuss their benefits and drawbacks when applied to SE. We focus on the interplay between computational throughput, memory footprint and model quality. Our method supports all three structures above and jointly learns integer quantized weights along with sparsity. Additionally, we demonstrate offline magnitude based pruning of integer quantized models as a performance baseline. Although efficient speech enhancement is an active area of research, our work is the first to apply block pruning to SE and the first to address SE model compression in the context of microNPU's. Using weight pruning, we show that we are able to compress an already compact model's memory footprint by a factor of 42x from 3.7MB to 87kB while only losing 0.1 dB SDR in performance. We also show a computational speedup of 6.7x with a corresponding SDR drop of only 0.59 dB SDR using block pruning.
TinyLSTMs: Efficient Neural Speech Enhancement for Hearing Aids
May 20, 2020
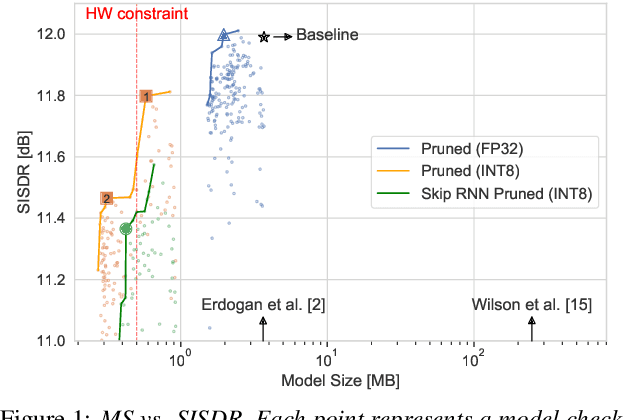
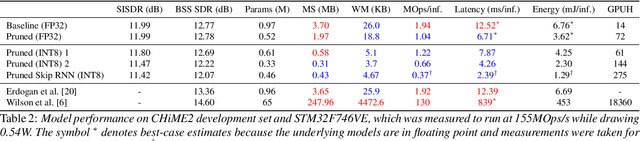
Modern speech enhancement algorithms achieve remarkable noise suppression by means of large recurrent neural networks (RNNs). However, large RNNs limit practical deployment in hearing aid hardware (HW) form-factors, which are battery powered and run on resource-constrained microcontroller units (MCUs) with limited memory capacity and compute capability. In this work, we use model compression techniques to bridge this gap. We define the constraints imposed on the RNN by the HW and describe a method to satisfy them. Although model compression techniques are an active area of research, we are the first to demonstrate their efficacy for RNN speech enhancement, using pruning and integer quantization of weights/activations. We also demonstrate state update skipping, which reduces the computational load. Finally, we conduct a perceptual evaluation of the compressed models to verify audio quality on human raters. Results show a reduction in model size and operations of 11.9$\times$ and 2.9$\times$, respectively, over the baseline for compressed models, without a statistical difference in listening preference and only exhibiting a loss of 0.55dB SDR. Our model achieves a computational latency of 2.39ms, well within the 10ms target and 351$\times$ better than previous work.
Neural Wavetable: a playable wavetable synthesizer using neural networks
Nov 16, 2018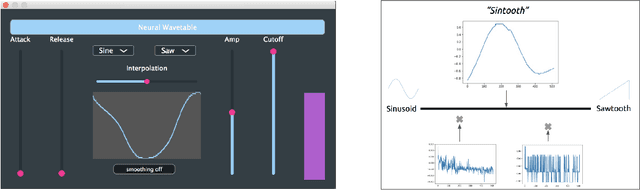
We present Neural Wavetable, a proof-of-concept wavetable synthesizer that uses neural networks to generate playable wavetables. The system can produce new, distinct waveforms through the interpolation of traditional wavetables in an autoencoder's latent space. It is available as a VST/AU plugin for use in a Digital Audio Workstation.
MuseGAN: Multi-track Sequential Generative Adversarial Networks for Symbolic Music Generation and Accompaniment
Nov 24, 2017
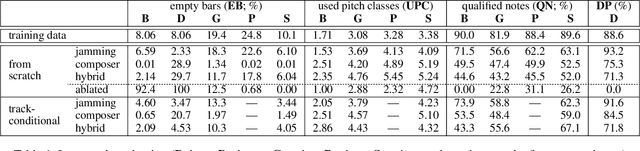
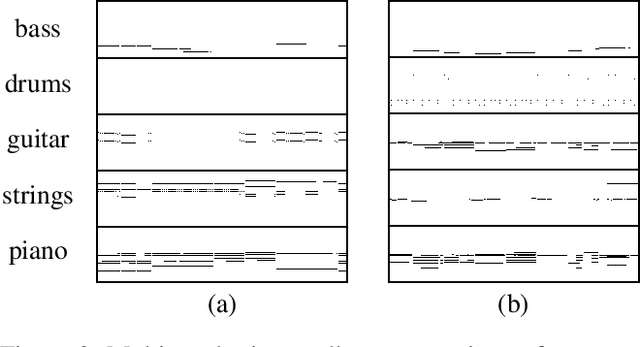
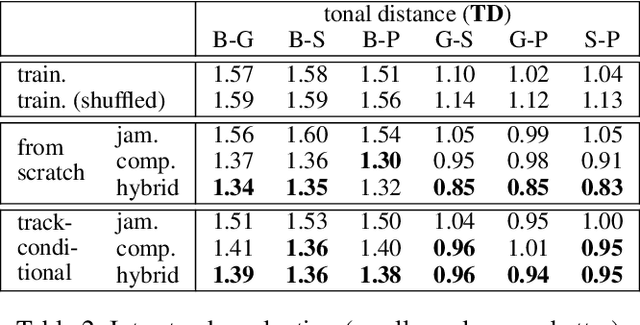
Generating music has a few notable differences from generating images and videos. First, music is an art of time, necessitating a temporal model. Second, music is usually composed of multiple instruments/tracks with their own temporal dynamics, but collectively they unfold over time interdependently. Lastly, musical notes are often grouped into chords, arpeggios or melodies in polyphonic music, and thereby introducing a chronological ordering of notes is not naturally suitable. In this paper, we propose three models for symbolic multi-track music generation under the framework of generative adversarial networks (GANs). The three models, which differ in the underlying assumptions and accordingly the network architectures, are referred to as the jamming model, the composer model and the hybrid model. We trained the proposed models on a dataset of over one hundred thousand bars of rock music and applied them to generate piano-rolls of five tracks: bass, drums, guitar, piano and strings. A few intra-track and inter-track objective metrics are also proposed to evaluate the generative results, in addition to a subjective user study. We show that our models can generate coherent music of four bars right from scratch (i.e. without human inputs). We also extend our models to human-AI cooperative music generation: given a specific track composed by human, we can generate four additional tracks to accompany it. All code, the dataset and the rendered audio samples are available at https://salu133445.github.io/musegan/ .
MidiNet: A Convolutional Generative Adversarial Network for Symbolic-domain Music Generation
Jul 18, 2017
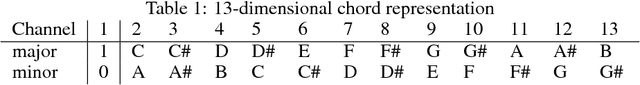

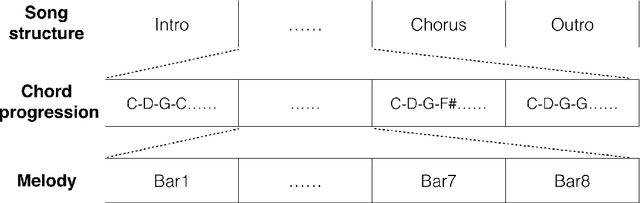
Most existing neural network models for music generation use recurrent neural networks. However, the recent WaveNet model proposed by DeepMind shows that convolutional neural networks (CNNs) can also generate realistic musical waveforms in the audio domain. Following this light, we investigate using CNNs for generating melody (a series of MIDI notes) one bar after another in the symbolic domain. In addition to the generator, we use a discriminator to learn the distributions of melodies, making it a generative adversarial network (GAN). Moreover, we propose a novel conditional mechanism to exploit available prior knowledge, so that the model can generate melodies either from scratch, by following a chord sequence, or by conditioning on the melody of previous bars (e.g. a priming melody), among other possibilities. The resulting model, named MidiNet, can be expanded to generate music with multiple MIDI channels (i.e. tracks). We conduct a user study to compare the melody of eight-bar long generated by MidiNet and by Google's MelodyRNN models, each time using the same priming melody. Result shows that MidiNet performs comparably with MelodyRNN models in being realistic and pleasant to listen to, yet MidiNet's melodies are reported to be much more interesting.
Revisiting the problem of audio-based hit song prediction using convolutional neural networks
Apr 05, 2017
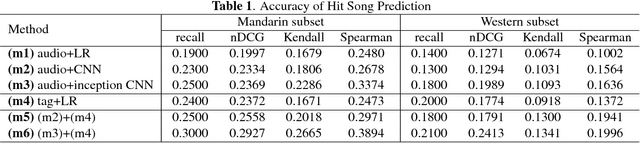
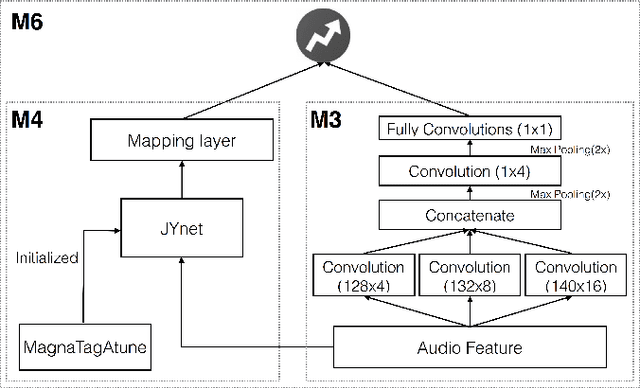
Being able to predict whether a song can be a hit has impor- tant applications in the music industry. Although it is true that the popularity of a song can be greatly affected by exter- nal factors such as social and commercial influences, to which degree audio features computed from musical signals (whom we regard as internal factors) can predict song popularity is an interesting research question on its own. Motivated by the recent success of deep learning techniques, we attempt to ex- tend previous work on hit song prediction by jointly learning the audio features and prediction models using deep learning. Specifically, we experiment with a convolutional neural net- work model that takes the primitive mel-spectrogram as the input for feature learning, a more advanced JYnet model that uses an external song dataset for supervised pre-training and auto-tagging, and the combination of these two models. We also consider the inception model to characterize audio infor- mation in different scales. Our experiments suggest that deep structures are indeed more accurate than shallow structures in predicting the popularity of either Chinese or Western Pop songs in Taiwan. We also use the tags predicted by JYnet to gain insights into the result of different models.