 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCCATMos: Convolutional Context-aware Transformer Network for Non-intrusive Speech Quality Assessment
Nov 04, 2022Speech quality assessment has been a critical component in many voice communication related applications such as telephony and online conferencing. Traditional intrusive speech quality assessment requires the clean reference of the degraded utterance to provide an accurate quality measurement. This requirement limits the usability of these methods in real-world scenarios. On the other hand, non-intrusive subjective measurement is the ``golden standard" in evaluating speech quality as human listeners can intrinsically evaluate the quality of any degraded speech with ease. In this paper, we propose a novel end-to-end model structure called Convolutional Context-Aware Transformer (CCAT) network to predict the mean opinion score (MOS) of human raters. We evaluate our model on three MOS-annotated datasets spanning multiple languages and distortion types and submit our results to the ConferencingSpeech 2022 Challenge. Our experiments show that CCAT provides promising MOS predictions compared to current state-of-art non-intrusive speech assessment models with average Pearson correlation coefficient (PCC) increasing from 0.530 to 0.697 and average RMSE decreasing from 0.768 to 0.570 compared to the baseline model on the challenge evaluation test set.
Weight, Block or Unit? Exploring Sparsity Tradeoffs for Speech Enhancement on Tiny Neural Accelerators
Nov 09, 2021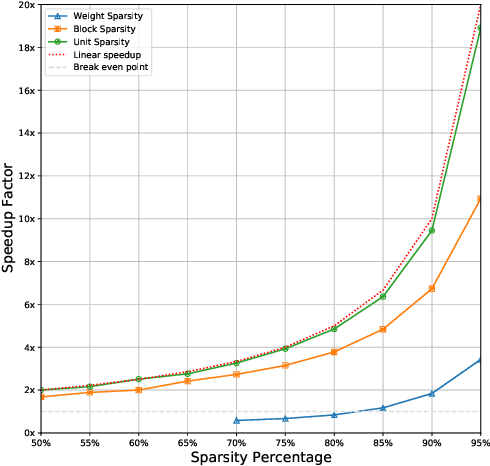
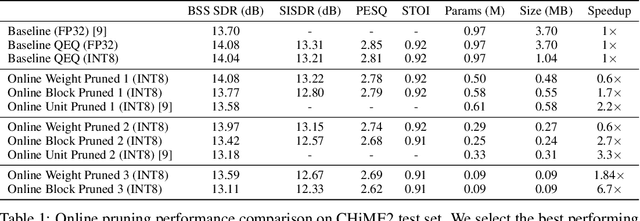
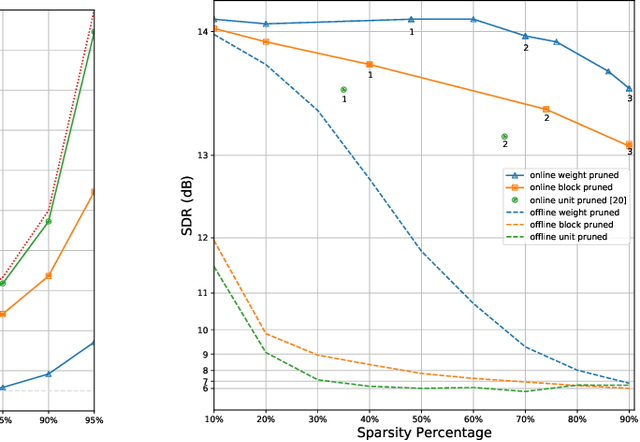

We explore network sparsification strategies with the aim of compressing neural speech enhancement (SE) down to an optimal configuration for a new generation of low power microcontroller based neural accelerators (microNPU's). We examine three unique sparsity structures: weight pruning, block pruning and unit pruning; and discuss their benefits and drawbacks when applied to SE. We focus on the interplay between computational throughput, memory footprint and model quality. Our method supports all three structures above and jointly learns integer quantized weights along with sparsity. Additionally, we demonstrate offline magnitude based pruning of integer quantized models as a performance baseline. Although efficient speech enhancement is an active area of research, our work is the first to apply block pruning to SE and the first to address SE model compression in the context of microNPU's. Using weight pruning, we show that we are able to compress an already compact model's memory footprint by a factor of 42x from 3.7MB to 87kB while only losing 0.1 dB SDR in performance. We also show a computational speedup of 6.7x with a corresponding SDR drop of only 0.59 dB SDR using block pruning.