 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-time multichannel deep speech enhancement in hearing aids: Comparing monaural and binaural processing in complex acoustic scenarios
May 03, 2024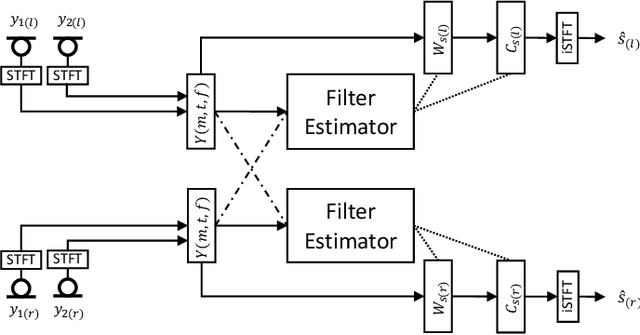
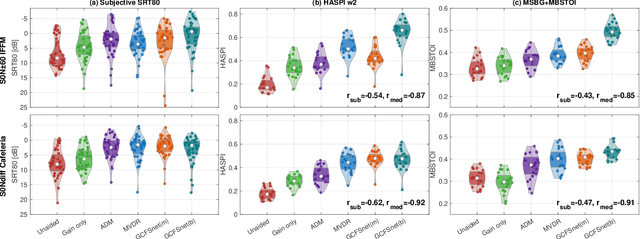
Deep learning has the potential to enhance speech signals and increase their intelligibility for users of hearing aids. Deep models suited for real-world application should feature a low computational complexity and low processing delay of only a few milliseconds. In this paper, we explore deep speech enhancement that matches these requirements and contrast monaural and binaural processing algorithms in two complex acoustic scenes. Both algorithms are evaluated with objective metrics and in experiments with hearing-impaired listeners performing a speech-in-noise test. Results are compared to two traditional enhancement strategies, i.e., adaptive differential microphone processing and binaural beamforming. While in diffuse noise, all algorithms perform similarly, the binaural deep learning approach performs best in the presence of spatial interferers. Through a post-analysis, this can be attributed to improvements at low SNRs and to precise spatial filtering.
Binaural multichannel blind speaker separation with a causal low-latency and low-complexity approach
Dec 08, 2023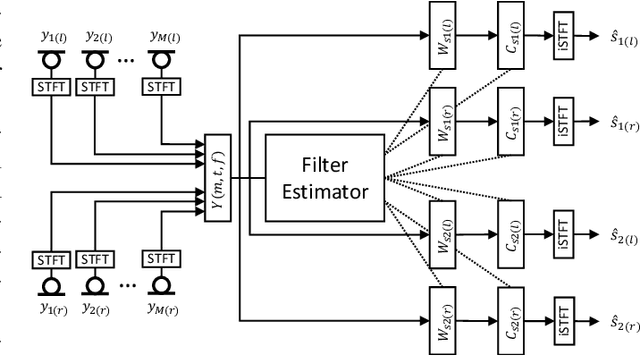
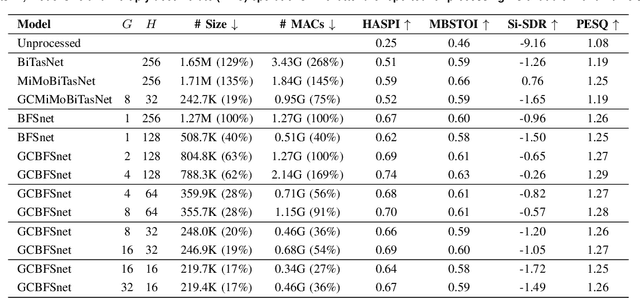
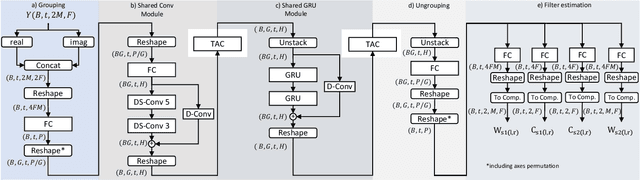

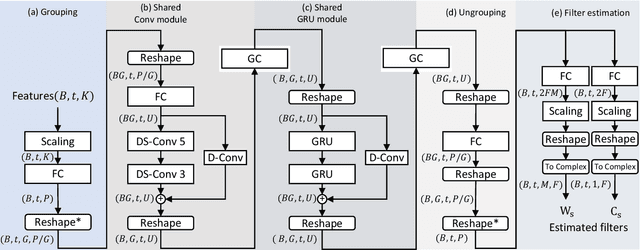
In this paper, we introduce a causal low-latency low-complexity approach for binaural multichannel blind speaker separation in noisy reverberant conditions. The model, referred to as Group Communication Binaural Filter and Sum Network (GCBFSnet) predicts complex filters for filter-and-sum beamforming in the time-frequency domain. We apply Group Communication (GC), i.e., latent model variables are split into groups and processed with a shared sequence model with the aim of reducing the complexity of a simple model only containing one convolutional and one recurrent module. With GC we are able to reduce the size of the model by up to 83 % and the complexity up to 73 % compared to the model without GC, while mostly retaining performance. Even for the smallest model configuration, GCBFSnet matches the performance of a low-complexity TasNet baseline in most metrics despite the larger size and higher number of required operations of the baseline.
Low bit rate binaural link for improved ultra low-latency low-complexity multichannel speech enhancement in Hearing Aids
Jul 17, 2023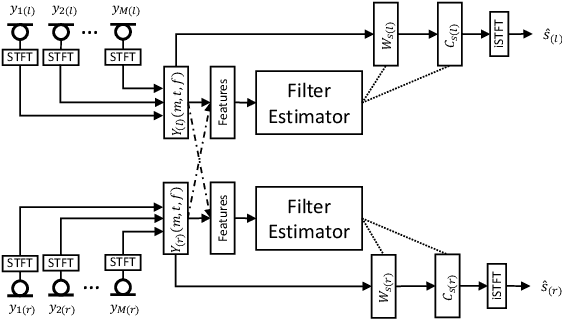
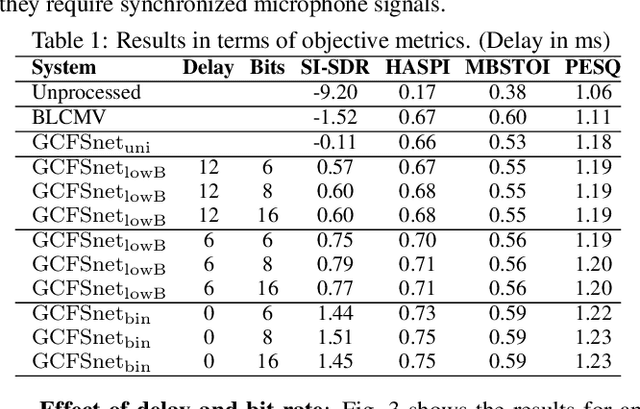
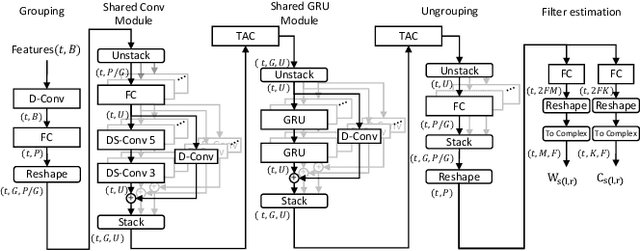

Speech enhancement in hearing aids is a challenging task since the hardware limits the number of possible operations and the latency needs to be in the range of only a few milliseconds. We propose a deep-learning model compatible with these limitations, which we refer to as Group-Communication Filter-and-Sum Network (GCFSnet). GCFSnet is a causal multiple-input single output enhancement model using filter-and-sum processing in the time-frequency domain and a multi-frame deep post filter. All filters are complex-valued and are estimated by a deep-learning model using weight-sharing through Group Communication and quantization-aware training for reducing model size and computational footprint. For a further increase in performance, a low bit rate binaural link for delayed binaural features is proposed to use binaural information while retaining a latency of 2ms. The performance of an oracle binaural LCMV beamformer in non-low-latency configuration can be matched even by a unilateral configuration of the GCFSnet in terms of objective metrics.
tPLCnet: Real-time Deep Packet Loss Concealment in the Time Domain Using a Short Temporal Context
Apr 04, 2022
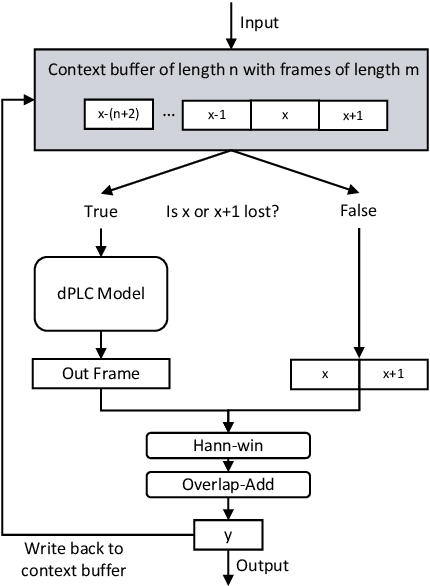
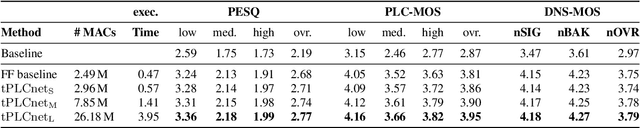
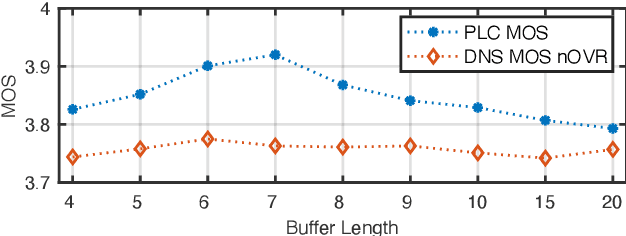
This paper introduces a real-time time-domain packet loss concealment (PLC) neural-network (tPLCnet). It efficiently predicts lost frames from a short context buffer in a sequence-to-one (seq2one) fashion. Because of its seq2one structure, a continuous inference of the model is not required since it can be triggered when packet loss is actually detected. It is trained on 64h of open-source speech data and packet-loss traces of real calls provided by the Audio PLC Challenge. The model with the lowest complexity described in this paper reaches a robust PLC performance and consistent improvements over the zero-filling baseline for all metrics. A configuration with higher complexity is submitted to the PLC Challenge and shows a performance increase of 1.07 compared to the zero-filling baseline in terms of PLC-MOS on the blind test set and reaches a competitive 3rd place in the challenge ranking.
Weight, Block or Unit? Exploring Sparsity Tradeoffs for Speech Enhancement on Tiny Neural Accelerators
Nov 09, 2021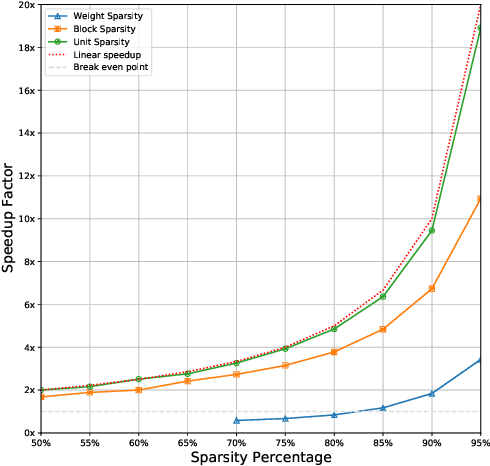
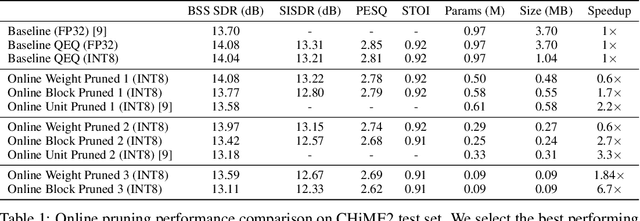
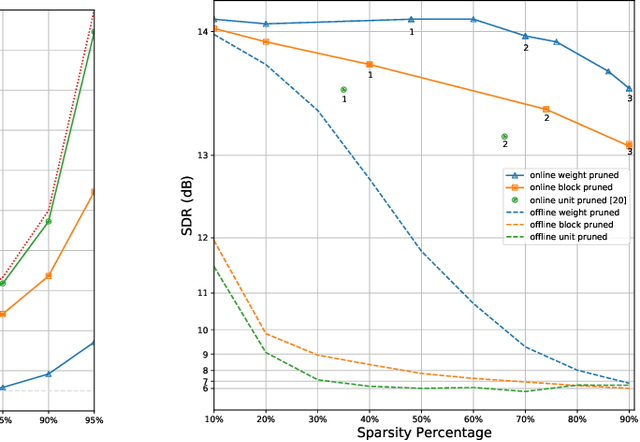

We explore network sparsification strategies with the aim of compressing neural speech enhancement (SE) down to an optimal configuration for a new generation of low power microcontroller based neural accelerators (microNPU's). We examine three unique sparsity structures: weight pruning, block pruning and unit pruning; and discuss their benefits and drawbacks when applied to SE. We focus on the interplay between computational throughput, memory footprint and model quality. Our method supports all three structures above and jointly learns integer quantized weights along with sparsity. Additionally, we demonstrate offline magnitude based pruning of integer quantized models as a performance baseline. Although efficient speech enhancement is an active area of research, our work is the first to apply block pruning to SE and the first to address SE model compression in the context of microNPU's. Using weight pruning, we show that we are able to compress an already compact model's memory footprint by a factor of 42x from 3.7MB to 87kB while only losing 0.1 dB SDR in performance. We also show a computational speedup of 6.7x with a corresponding SDR drop of only 0.59 dB SDR using block pruning.
Reduction of Subjective Listening Effort for TV Broadcast Signals with Recurrent Neural Networks
Nov 02, 2021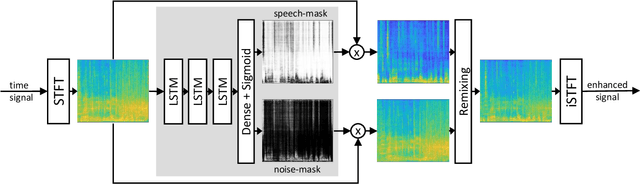
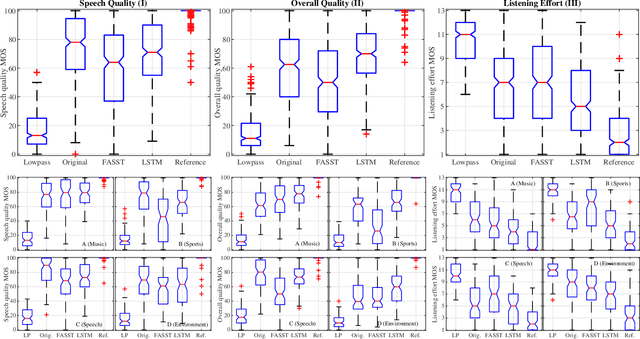


Listening to the audio of TV broadcast signals can be challenging for hearing-impaired as well as normal-hearing listeners, especially when background sounds are prominent or too loud compared to the speech signal. This can result in a reduced satisfaction and increased listening effort of the listeners. Since the broadcast sound is usually premixed, we perform a subjective evaluation for quantifying the potential of speech enhancement systems based on audio source separation and recurrent neural networks (RNN). Recently, RNNs have shown promising results in the context of sound source separation and real-time signal processing. In this paper, we separate the speech from the background signals and remix the separated sounds at a higher signal-to-noise ratio. This differs from classic speech enhancement, where usually only the extracted speech signal is exploited. The subjective evaluation with 20 normal-hearing subjects on real TV-broadcast material shows that our proposed enhancement system is able to reduce the listening effort by around 2 points on a 13-point listening effort rating scale and increases the perceived sound quality compared to the original mixture.