 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFSD50K-Solo: Automated Curation of Single-Source Sound Events
May 13, 2026High-quality training datasets are essential for the performance of neural networks. However, the audio domain still lacks a large-scale, strongly-labeled, and single-source sound event dataset. The FSD50K dataset, despite being relatively large and open, contains a considerable fraction of multi-source samples where background interference or overlapping events could limit the usefulness of the data. To address this challenge, we introduce a data curation framework designed for large-scale open audio corpora. Our approach leverages a generative diffusion model to synthesize clean single-class events to construct controlled noisy mixtures for supervision. We subsequently employ a pre-trained audio encoder coupled with a discriminative classifier to automatically identify and filter out multi-source samples. Experiments show that our framework achieves strong performance on a human expert-curated test set. Finally, we release FSD50K-Solo, a model-curated subset of FSD50K containing single-source audio samples identified by our method. Beyond FSD50K, our method establishes a scalable paradigm for curating open source audio corpora.
CATSE: A Context-Aware Framework for Causal Target Sound Extraction
Mar 21, 2024



Target Sound Extraction (TSE) focuses on the problem of separating sources of interest, indicated by a user's cue, from the input mixture. Most existing solutions operate in an offline fashion and are not suited to the low-latency causal processing constraints imposed by applications in live-streamed content such as augmented hearing. We introduce a family of context-aware low-latency causal TSE models suitable for real-time processing. First, we explore the utility of context by providing the TSE model with oracle information about what sound classes make up the input mixture, where the objective of the model is to extract one or more sources of interest indicated by the user. Since the practical applications of oracle models are limited due to their assumptions, we introduce a composite multi-task training objective involving separation and classification losses. Our evaluation involving single- and multi-source extraction shows the benefit of using context information in the model either by means of providing full context or via the proposed multi-task training loss without the need for full context information. Specifically, we show that our proposed model outperforms size- and latency-matched Waveformer, a state-of-the-art model for real-time TSE.
Latent CLAP Loss for Better Foley Sound Synthesis
Mar 18, 2024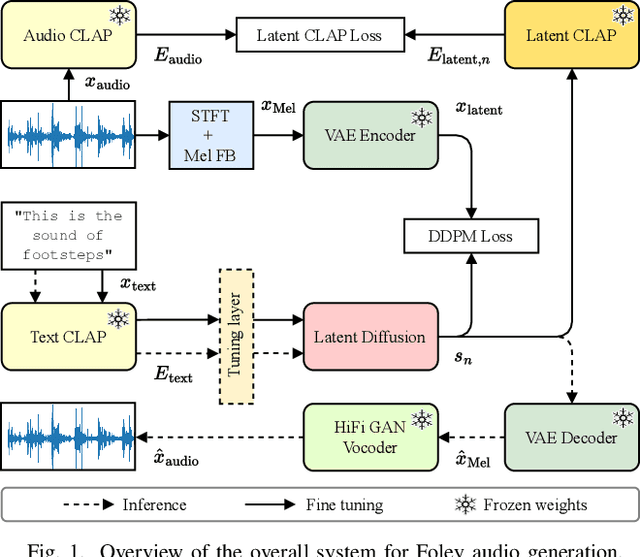
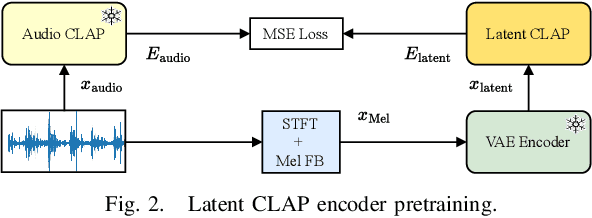
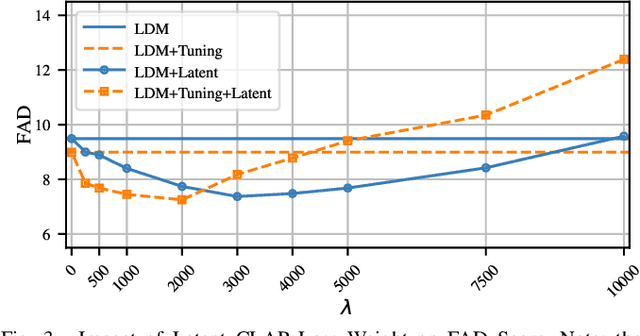
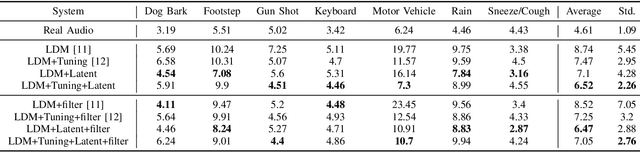
Foley sound generation, the art of creating audio for multimedia, has recently seen notable advancements through text-conditioned latent diffusion models. These systems use multimodal text-audio representation models, such as Contrastive Language-Audio Pretraining (CLAP), whose objective is to map corresponding audio and text prompts into a joint embedding space. AudioLDM, a text-to-audio model, was the winner of the DCASE2023 task 7 Foley sound synthesis challenge. The winning system fine-tuned the model for specific audio classes and applied a post-filtering method using CLAP similarity scores between output audio and input text at inference time, requiring the generation of extra samples, thus reducing data generation efficiency. We introduce a new loss term to enhance Foley sound generation in AudioLDM without post-filtering. This loss term uses a new module based on the CLAP mode-Latent CLAP encode-to align the latent diffusion output with real audio in a shared CLAP embedding space. Our experiments demonstrate that our method effectively reduces the Frechet Audio Distance (FAD) score of the generated audio and eliminates the need for post-filtering, thus enhancing generation efficiency.
Two-Step Knowledge Distillation for Tiny Speech Enhancement
Sep 15, 2023Tiny, causal models are crucial for embedded audio machine learning applications. Model compression can be achieved via distilling knowledge from a large teacher into a smaller student model. In this work, we propose a novel two-step approach for tiny speech enhancement model distillation. In contrast to the standard approach of a weighted mixture of distillation and supervised losses, we firstly pre-train the student using only the knowledge distillation (KD) objective, after which we switch to a fully supervised training regime. We also propose a novel fine-grained similarity-preserving KD loss, which aims to match the student's intra-activation Gram matrices to that of the teacher. Our method demonstrates broad improvements, but particularly shines in adverse conditions including high compression and low signal to noise ratios (SNR), yielding signal to distortion ratio gains of 0.9 dB and 1.1 dB, respectively, at -5 dB input SNR and 63x compression compared to baseline.
Self-Supervised Learning for Speech Enhancement through Synthesis
Nov 04, 2022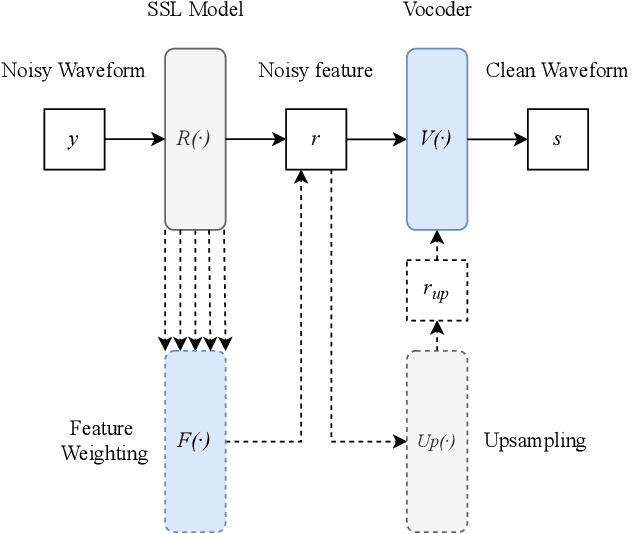
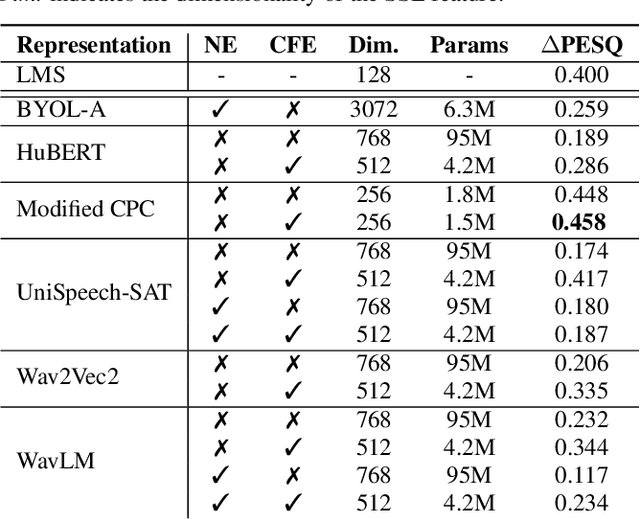
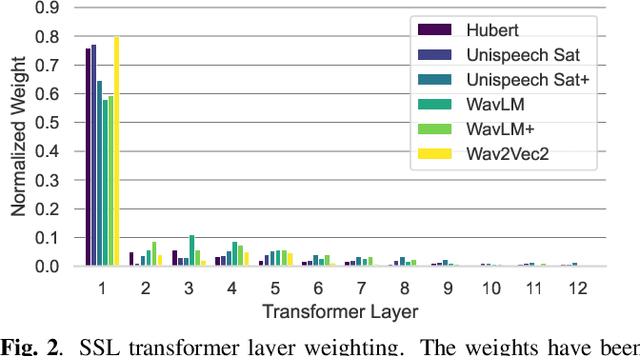
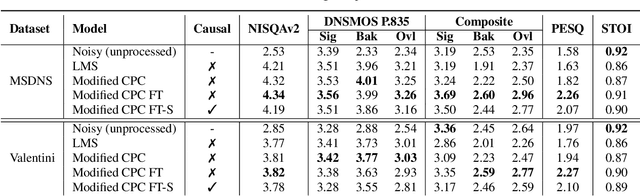
Modern speech enhancement (SE) networks typically implement noise suppression through time-frequency masking, latent representation masking, or discriminative signal prediction. In contrast, some recent works explore SE via generative speech synthesis, where the system's output is synthesized by a neural vocoder after an inherently lossy feature-denoising step. In this paper, we propose a denoising vocoder (DeVo) approach, where a vocoder accepts noisy representations and learns to directly synthesize clean speech. We leverage rich representations from self-supervised learning (SSL) speech models to discover relevant features. We conduct a candidate search across 15 potential SSL front-ends and subsequently train our vocoder adversarially with the best SSL configuration. Additionally, we demonstrate a causal version capable of running on streaming audio with 10ms latency and minimal performance degradation. Finally, we conduct both objective evaluations and subjective listening studies to show our system improves objective metrics and outperforms an existing state-of-the-art SE model subjectively.
CCATMos: Convolutional Context-aware Transformer Network for Non-intrusive Speech Quality Assessment
Nov 04, 2022Speech quality assessment has been a critical component in many voice communication related applications such as telephony and online conferencing. Traditional intrusive speech quality assessment requires the clean reference of the degraded utterance to provide an accurate quality measurement. This requirement limits the usability of these methods in real-world scenarios. On the other hand, non-intrusive subjective measurement is the ``golden standard" in evaluating speech quality as human listeners can intrinsically evaluate the quality of any degraded speech with ease. In this paper, we propose a novel end-to-end model structure called Convolutional Context-Aware Transformer (CCAT) network to predict the mean opinion score (MOS) of human raters. We evaluate our model on three MOS-annotated datasets spanning multiple languages and distortion types and submit our results to the ConferencingSpeech 2022 Challenge. Our experiments show that CCAT provides promising MOS predictions compared to current state-of-art non-intrusive speech assessment models with average Pearson correlation coefficient (PCC) increasing from 0.530 to 0.697 and average RMSE decreasing from 0.768 to 0.570 compared to the baseline model on the challenge evaluation test set.
Weight, Block or Unit? Exploring Sparsity Tradeoffs for Speech Enhancement on Tiny Neural Accelerators
Nov 09, 2021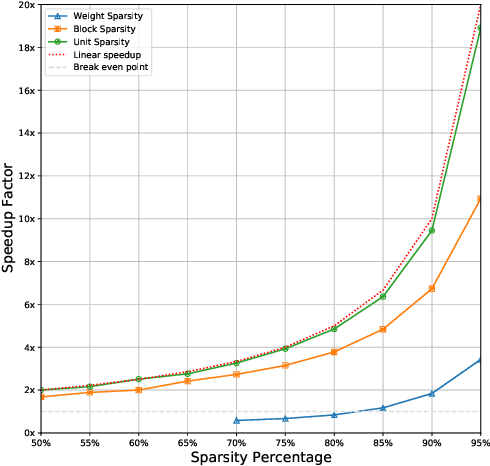
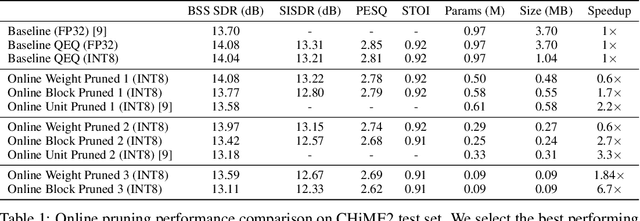
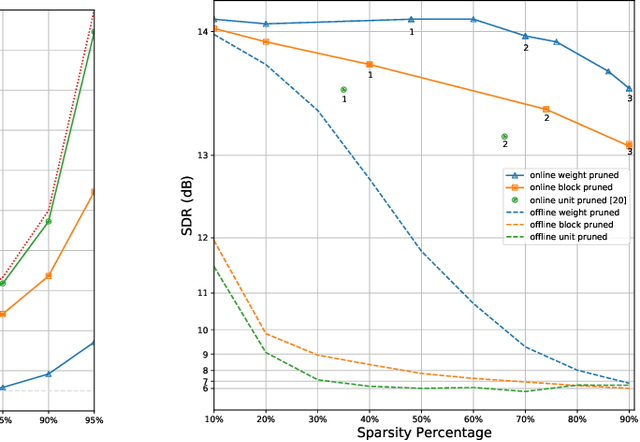

We explore network sparsification strategies with the aim of compressing neural speech enhancement (SE) down to an optimal configuration for a new generation of low power microcontroller based neural accelerators (microNPU's). We examine three unique sparsity structures: weight pruning, block pruning and unit pruning; and discuss their benefits and drawbacks when applied to SE. We focus on the interplay between computational throughput, memory footprint and model quality. Our method supports all three structures above and jointly learns integer quantized weights along with sparsity. Additionally, we demonstrate offline magnitude based pruning of integer quantized models as a performance baseline. Although efficient speech enhancement is an active area of research, our work is the first to apply block pruning to SE and the first to address SE model compression in the context of microNPU's. Using weight pruning, we show that we are able to compress an already compact model's memory footprint by a factor of 42x from 3.7MB to 87kB while only losing 0.1 dB SDR in performance. We also show a computational speedup of 6.7x with a corresponding SDR drop of only 0.59 dB SDR using block pruning.
TinyLSTMs: Efficient Neural Speech Enhancement for Hearing Aids
May 20, 2020
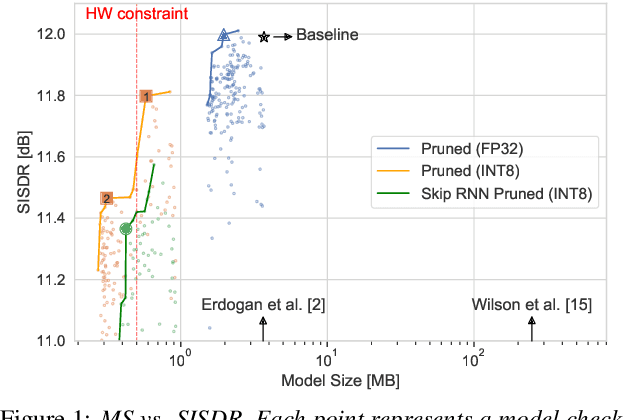
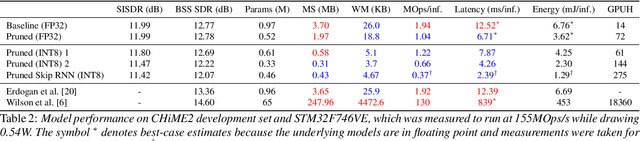
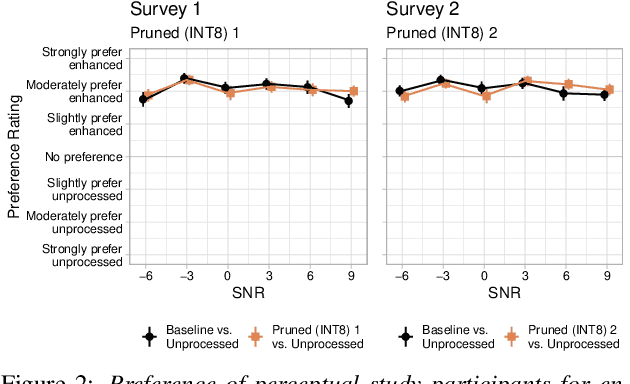
Modern speech enhancement algorithms achieve remarkable noise suppression by means of large recurrent neural networks (RNNs). However, large RNNs limit practical deployment in hearing aid hardware (HW) form-factors, which are battery powered and run on resource-constrained microcontroller units (MCUs) with limited memory capacity and compute capability. In this work, we use model compression techniques to bridge this gap. We define the constraints imposed on the RNN by the HW and describe a method to satisfy them. Although model compression techniques are an active area of research, we are the first to demonstrate their efficacy for RNN speech enhancement, using pruning and integer quantization of weights/activations. We also demonstrate state update skipping, which reduces the computational load. Finally, we conduct a perceptual evaluation of the compressed models to verify audio quality on human raters. Results show a reduction in model size and operations of 11.9$\times$ and 2.9$\times$, respectively, over the baseline for compressed models, without a statistical difference in listening preference and only exhibiting a loss of 0.55dB SDR. Our model achieves a computational latency of 2.39ms, well within the 10ms target and 351$\times$ better than previous work.
Machine Identification of High Impact Research through Text and Image Analysis
May 20, 2020
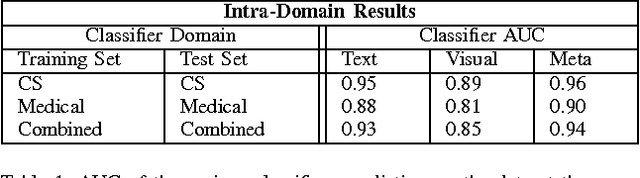
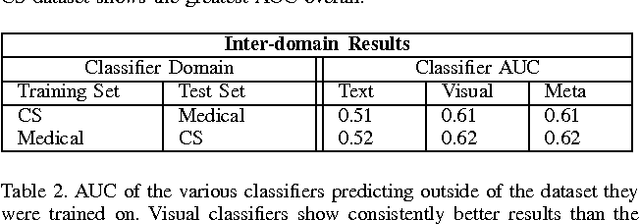
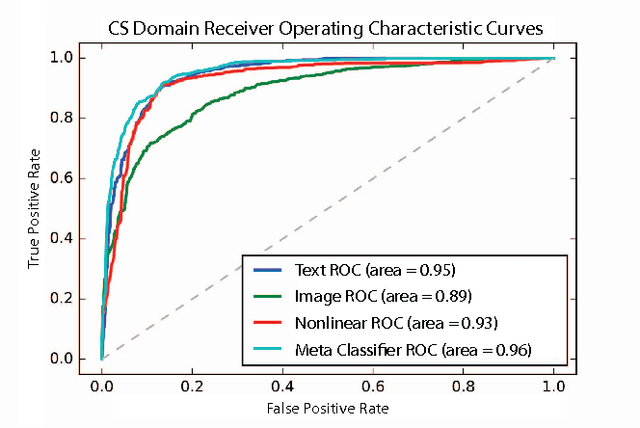
The volume of academic paper submissions and publications is growing at an ever increasing rate. While this flood of research promises progress in various fields, the sheer volume of output inherently increases the amount of noise. We present a system to automatically separate papers with a high from those with a low likelihood of gaining citations as a means to quickly find high impact, high quality research. Our system uses both a visual classifier, useful for surmising a document's overall appearance, and a text classifier, for making content-informed decisions. Current work in the field focuses on small datasets composed of papers from individual conferences. Attempts to use similar techniques on larger datasets generally only considers excerpts of the documents such as the abstract, potentially throwing away valuable data. We rectify these issues by providing a dataset composed of PDF documents and citation counts spanning a decade of output within two separate academic domains: computer science and medicine. This new dataset allows us to expand on current work in the field by generalizing across time and academic domain. Moreover, we explore inter-domain prediction models - evaluating a classifier's performance on a domain it was not trained on - to shed further insight on this important problem.
Towards Cover Song Detection with Siamese Convolutional Neural Networks
May 20, 2020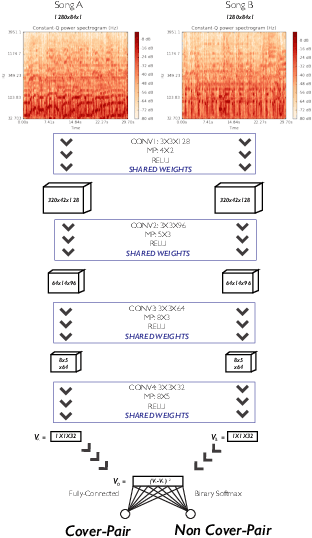
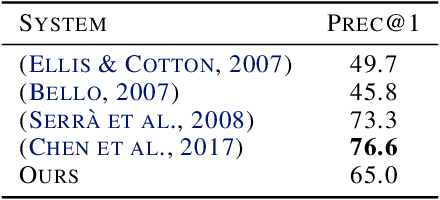
A cover song, by definition, is a new performance or recording of a previously recorded, commercially released song. It may be by the original artist themselves or a different artist altogether and can vary from the original in unpredictable ways including key, arrangement, instrumentation, timbre and more. In this work we propose a novel approach to learning audio representations for the task of cover song detection. We train a neural architecture on tens of thousands of cover-song audio clips and test it on a held out set. We obtain a mean precision@1 of 65% over mini-batches, ten times better than random guessing. Our results indicate that Siamese network configurations show promise for approaching the cover song identification problem.
* Code available at https://github.com/markostam/coversongs-dual-convnet