 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Source Extraction with Diffusion and Consistency Models
Dec 09, 2024In this work, we demonstrate the integration of a score-matching diffusion model into a deterministic architecture for time-domain musical source extraction, resulting in enhanced audio quality. To address the typically slow iterative sampling process of diffusion models, we apply consistency distillation and reduce the sampling process to a single step, achieving performance comparable to that of diffusion models, and with two or more steps, even surpassing them. Trained on the Slakh2100 dataset for four instruments (bass, drums, guitar, and piano), our model shows significant improvements across objective metrics compared to baseline methods. Sound examples are available at https://consistency-separation.github.io/.
Multi-Track MusicLDM: Towards Versatile Music Generation with Latent Diffusion Model
Sep 04, 2024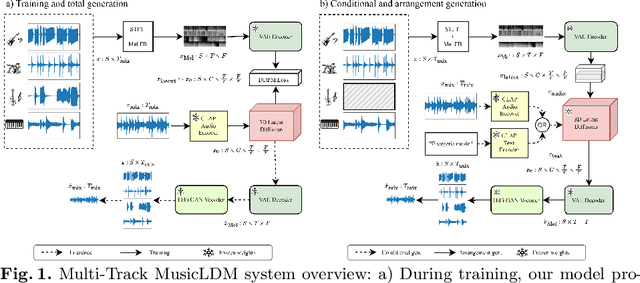


Diffusion models have shown promising results in cross-modal generation tasks involving audio and music, such as text-to-sound and text-to-music generation. These text-controlled music generation models typically focus on generating music by capturing global musical attributes like genre and mood. However, music composition is a complex, multilayered task that often involves musical arrangement as an integral part of the process. This process involves composing each instrument to align with existing ones in terms of beat, dynamics, harmony, and melody, requiring greater precision and control over tracks than text prompts usually provide. In this work, we address these challenges by extending the MusicLDM, a latent diffusion model for music, into a multi-track generative model. By learning the joint probability of tracks sharing a context, our model is capable of generating music across several tracks that correspond well to each other, either conditionally or unconditionally. Additionally, our model is capable of arrangement generation, where the model can generate any subset of tracks given the others (e.g., generating a piano track complementing given bass and drum tracks). We compared our model with an existing multi-track generative model and demonstrated that our model achieves considerable improvements across objective metrics for both total and arrangement generation tasks.
"It is okay to be uncommon": Quantizing Sound Event Detection Networks on Hardware Accelerators with Uncommon Sub-Byte Support
Apr 05, 2024



If our noise-canceling headphones can understand our audio environments, they can then inform us of important sound events, tune equalization based on the types of content we listen to, and dynamically adjust noise cancellation parameters based on audio scenes to further reduce distraction. However, running multiple audio understanding models on headphones with a limited energy budget and on-chip memory remains a challenging task. In this work, we identify a new class of neural network accelerators (e.g., NE16 on GAP9) that allows network weights to be quantized to different common (e.g., 8 bits) and uncommon bit-widths (e.g., 3 bits). We then applied a differentiable neural architecture search to search over the optimal bit-widths of a network on two different sound event detection tasks with potentially different requirements on quantization and prediction granularity (i.e., classification vs. embeddings for few-shot learning). We further evaluated our quantized models on actual hardware, showing that we reduce memory usage, inference latency, and energy consumption by an average of 62%, 46%, and 61% respectively compared to 8-bit models while maintaining floating point performance. Our work sheds light on the benefits of such accelerators on sound event detection tasks when combined with an appropriate search method.
Latent CLAP Loss for Better Foley Sound Synthesis
Mar 18, 2024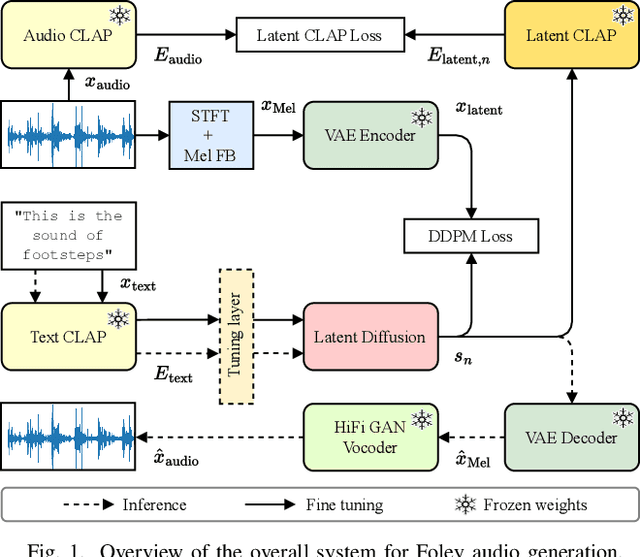
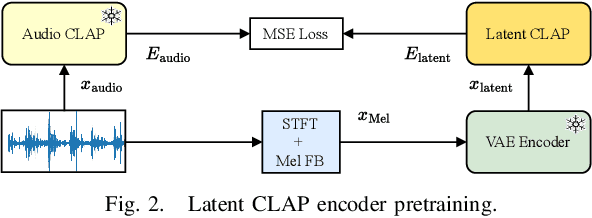
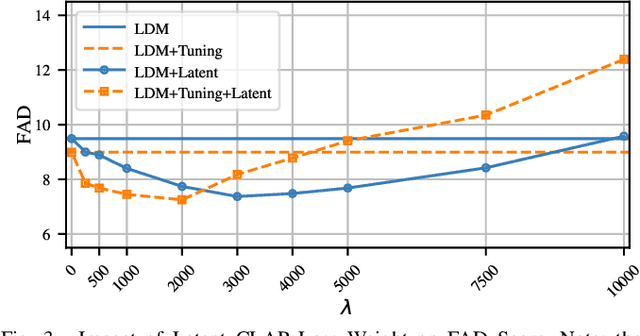
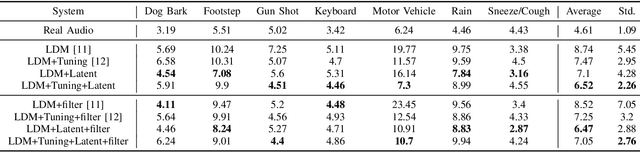
Foley sound generation, the art of creating audio for multimedia, has recently seen notable advancements through text-conditioned latent diffusion models. These systems use multimodal text-audio representation models, such as Contrastive Language-Audio Pretraining (CLAP), whose objective is to map corresponding audio and text prompts into a joint embedding space. AudioLDM, a text-to-audio model, was the winner of the DCASE2023 task 7 Foley sound synthesis challenge. The winning system fine-tuned the model for specific audio classes and applied a post-filtering method using CLAP similarity scores between output audio and input text at inference time, requiring the generation of extra samples, thus reducing data generation efficiency. We introduce a new loss term to enhance Foley sound generation in AudioLDM without post-filtering. This loss term uses a new module based on the CLAP mode-Latent CLAP encode-to align the latent diffusion output with real audio in a shared CLAP embedding space. Our experiments demonstrate that our method effectively reduces the Frechet Audio Distance (FAD) score of the generated audio and eliminates the need for post-filtering, thus enhancing generation efficiency.
HiSSNet: Sound Event Detection and Speaker Identification via Hierarchical Prototypical Networks for Low-Resource Headphones
Mar 13, 2023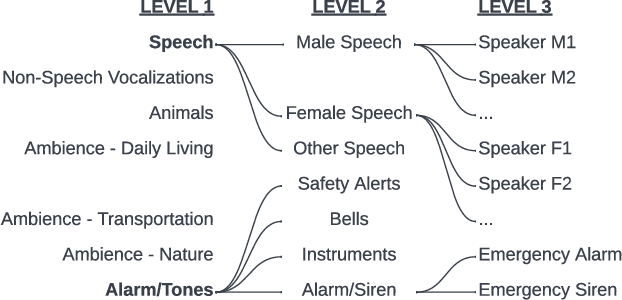



Modern noise-cancelling headphones have significantly improved users' auditory experiences by removing unwanted background noise, but they can also block out sounds that matter to users. Machine learning (ML) models for sound event detection (SED) and speaker identification (SID) can enable headphones to selectively pass through important sounds; however, implementing these models for a user-centric experience presents several unique challenges. First, most people spend limited time customizing their headphones, so the sound detection should work reasonably well out of the box. Second, the models should be able to learn over time the specific sounds that are important to users based on their implicit and explicit interactions. Finally, such models should have a small memory footprint to run on low-power headphones with limited on-chip memory. In this paper, we propose addressing these challenges using HiSSNet (Hierarchical SED and SID Network). HiSSNet is an SEID (SED and SID) model that uses a hierarchical prototypical network to detect both general and specific sounds of interest and characterize both alarm-like and speech sounds. We show that HiSSNet outperforms an SEID model trained using non-hierarchical prototypical networks by 6.9 - 8.6 percent. When compared to state-of-the-art (SOTA) models trained specifically for SED or SID alone, HiSSNet achieves similar or better performance while reducing the memory footprint required to support multiple capabilities on-device.
Affinity Mixup for Weakly Supervised Sound Event Detection
Jun 21, 2021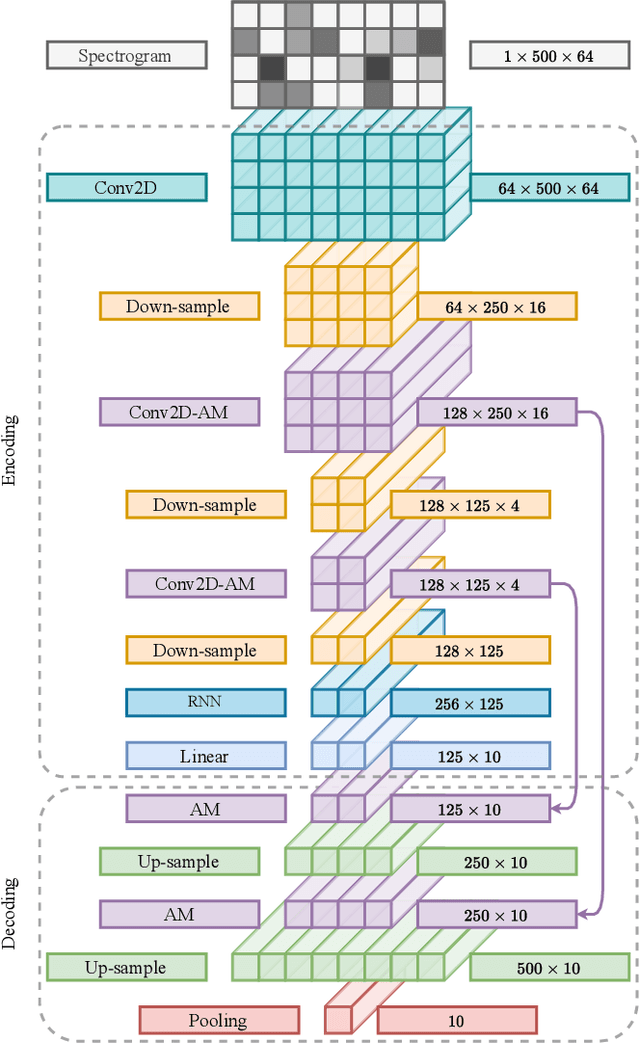
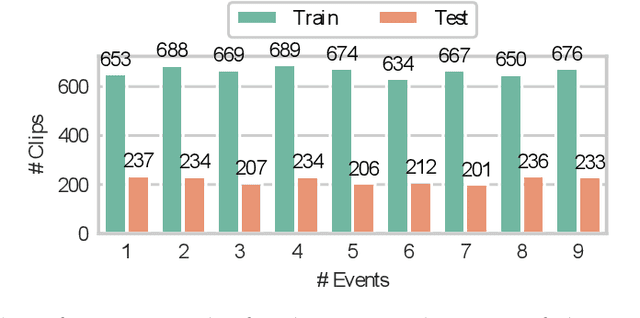
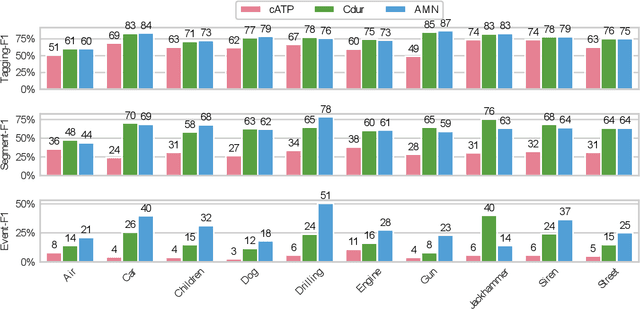
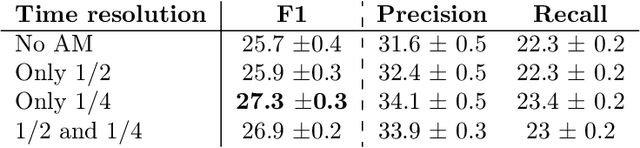
The weakly supervised sound event detection problem is the task of predicting the presence of sound events and their corresponding starting and ending points in a weakly labeled dataset. A weak dataset associates each training sample (a short recording) to one or more present sources. Networks that solely rely on convolutional and recurrent layers cannot directly relate multiple frames in a recording. Motivated by attention and graph neural networks, we introduce the concept of an affinity mixup to incorporate time-level similarities and make a connection between frames. This regularization technique mixes up features in different layers using an adaptive affinity matrix. Our proposed affinity mixup network improves over state-of-the-art techniques event-F1 scores by $8.2\%$.
Optimization of Graph Neural Networks with Natural Gradient Descent
Aug 21, 2020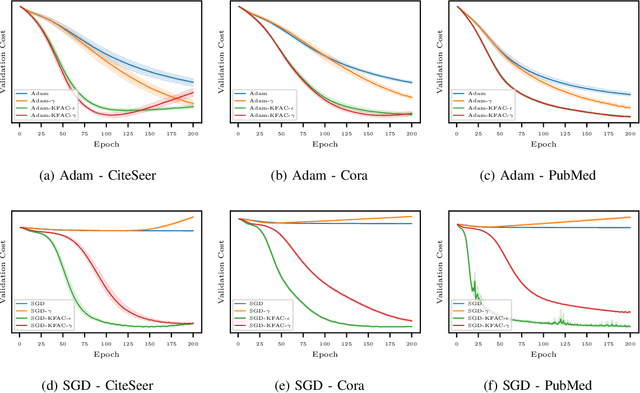
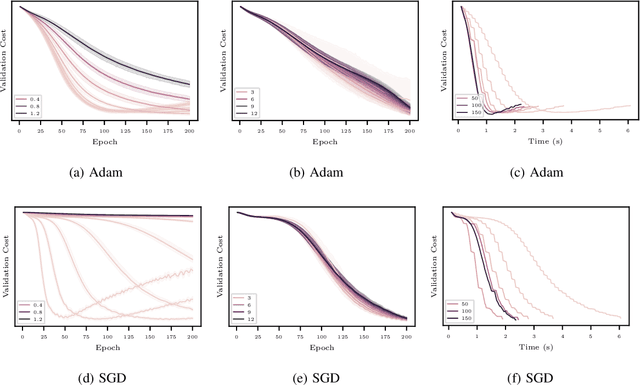
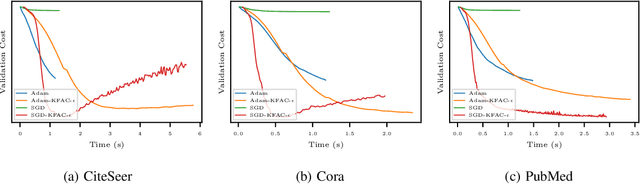

In this work, we propose to employ information-geometric tools to optimize a graph neural network architecture such as the graph convolutional networks. More specifically, we develop optimization algorithms for the graph-based semi-supervised learning by employing the natural gradient information in the optimization process. This allows us to efficiently exploit the geometry of the underlying statistical model or parameter space for optimization and inference. To the best of our knowledge, this is the first work that has utilized the natural gradient for the optimization of graph neural networks that can be extended to other semi-supervised problems. Efficient computations algorithms are developed and extensive numerical studies are conducted to demonstrate the superior performance of our algorithms over existing algorithms such as ADAM and SGD.
Feature Level Fusion from Facial Attributes for Face Recognition
Sep 28, 2019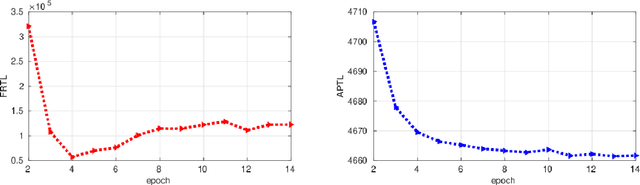


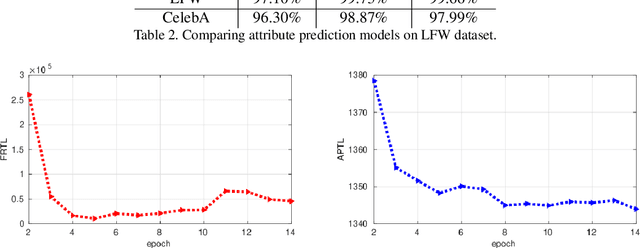
We introduce a deep convolutional neural networks (CNN) architecture to classify facial attributes and recognize face images simultaneously via a shared learning paradigm to improve the accuracy for facial attribute prediction and face recognition performance. In this method, we use facial attributes as an auxiliary source of information to assist CNN features extracted from the face images to improve the face recognition performance. Specifically, we use a shared CNN architecture that jointly predicts facial attributes and recognize face images simultaneously via a shared learning parameters, and then we use facial attribute features an an auxiliary source of information concatenated by face features to increase the discrimination of the CNN for face recognition. This process assists the CNN classifier to better recognize face images. The experimental results show that our model increases both the face recognition and facial attribute prediction performance, especially for the identity attributes such as gender and race. We evaluated our method on several standard datasets labeled by identities and face attributes and the results show that the proposed method outperforms state-of-the-art face recognition models.