 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent CLAP Loss for Better Foley Sound Synthesis
Mar 18, 2024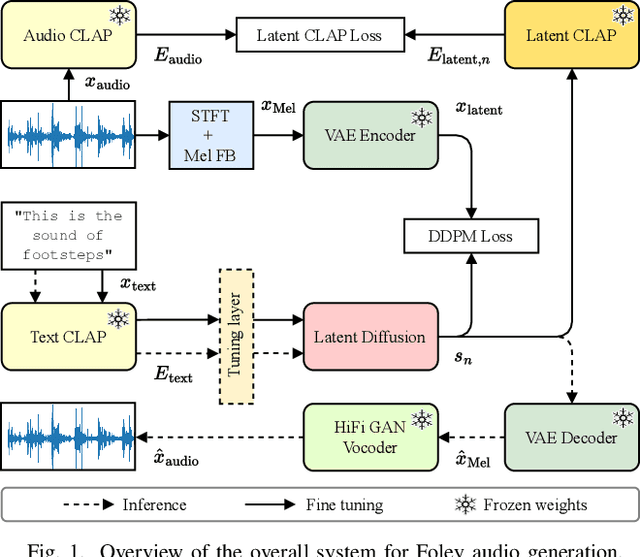
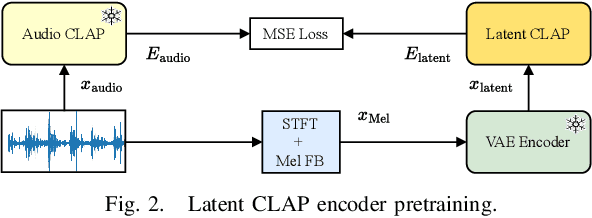
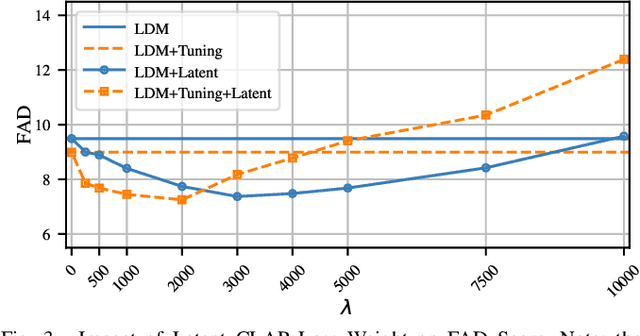
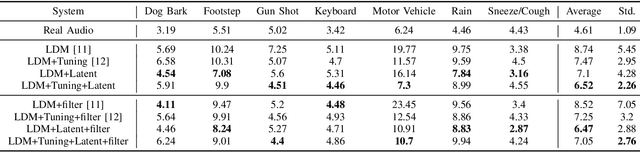
Foley sound generation, the art of creating audio for multimedia, has recently seen notable advancements through text-conditioned latent diffusion models. These systems use multimodal text-audio representation models, such as Contrastive Language-Audio Pretraining (CLAP), whose objective is to map corresponding audio and text prompts into a joint embedding space. AudioLDM, a text-to-audio model, was the winner of the DCASE2023 task 7 Foley sound synthesis challenge. The winning system fine-tuned the model for specific audio classes and applied a post-filtering method using CLAP similarity scores between output audio and input text at inference time, requiring the generation of extra samples, thus reducing data generation efficiency. We introduce a new loss term to enhance Foley sound generation in AudioLDM without post-filtering. This loss term uses a new module based on the CLAP mode-Latent CLAP encode-to align the latent diffusion output with real audio in a shared CLAP embedding space. Our experiments demonstrate that our method effectively reduces the Frechet Audio Distance (FAD) score of the generated audio and eliminates the need for post-filtering, thus enhancing generation efficiency.