 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCATSE: A Context-Aware Framework for Causal Target Sound Extraction
Mar 21, 2024



Target Sound Extraction (TSE) focuses on the problem of separating sources of interest, indicated by a user's cue, from the input mixture. Most existing solutions operate in an offline fashion and are not suited to the low-latency causal processing constraints imposed by applications in live-streamed content such as augmented hearing. We introduce a family of context-aware low-latency causal TSE models suitable for real-time processing. First, we explore the utility of context by providing the TSE model with oracle information about what sound classes make up the input mixture, where the objective of the model is to extract one or more sources of interest indicated by the user. Since the practical applications of oracle models are limited due to their assumptions, we introduce a composite multi-task training objective involving separation and classification losses. Our evaluation involving single- and multi-source extraction shows the benefit of using context information in the model either by means of providing full context or via the proposed multi-task training loss without the need for full context information. Specifically, we show that our proposed model outperforms size- and latency-matched Waveformer, a state-of-the-art model for real-time TSE.
Latent CLAP Loss for Better Foley Sound Synthesis
Mar 18, 2024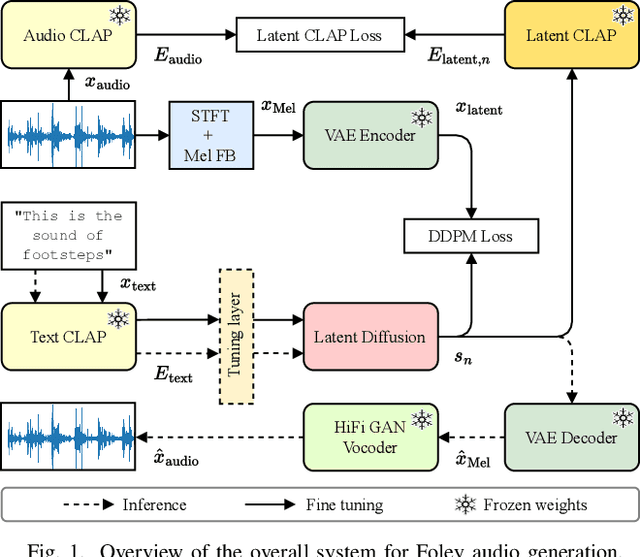
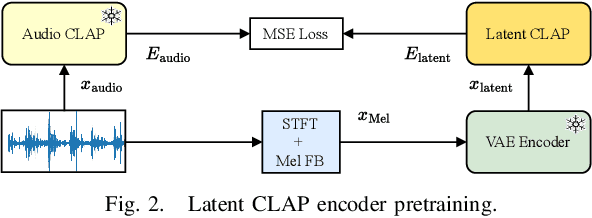
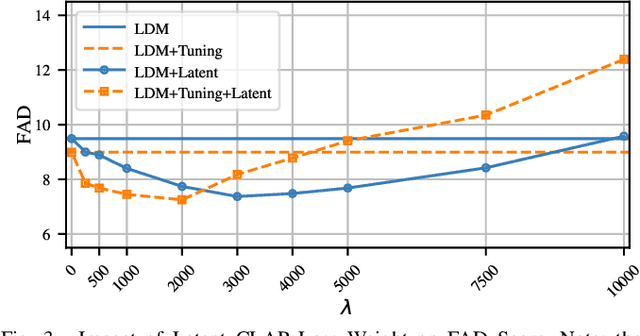
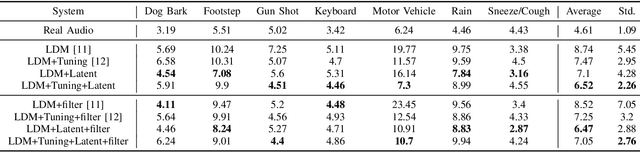
Foley sound generation, the art of creating audio for multimedia, has recently seen notable advancements through text-conditioned latent diffusion models. These systems use multimodal text-audio representation models, such as Contrastive Language-Audio Pretraining (CLAP), whose objective is to map corresponding audio and text prompts into a joint embedding space. AudioLDM, a text-to-audio model, was the winner of the DCASE2023 task 7 Foley sound synthesis challenge. The winning system fine-tuned the model for specific audio classes and applied a post-filtering method using CLAP similarity scores between output audio and input text at inference time, requiring the generation of extra samples, thus reducing data generation efficiency. We introduce a new loss term to enhance Foley sound generation in AudioLDM without post-filtering. This loss term uses a new module based on the CLAP mode-Latent CLAP encode-to align the latent diffusion output with real audio in a shared CLAP embedding space. Our experiments demonstrate that our method effectively reduces the Frechet Audio Distance (FAD) score of the generated audio and eliminates the need for post-filtering, thus enhancing generation efficiency.
Self-Supervised Learning for Speech Enhancement through Synthesis
Nov 04, 2022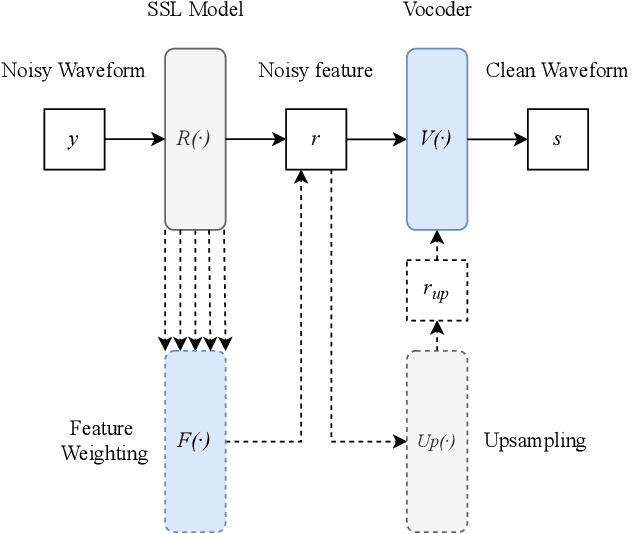
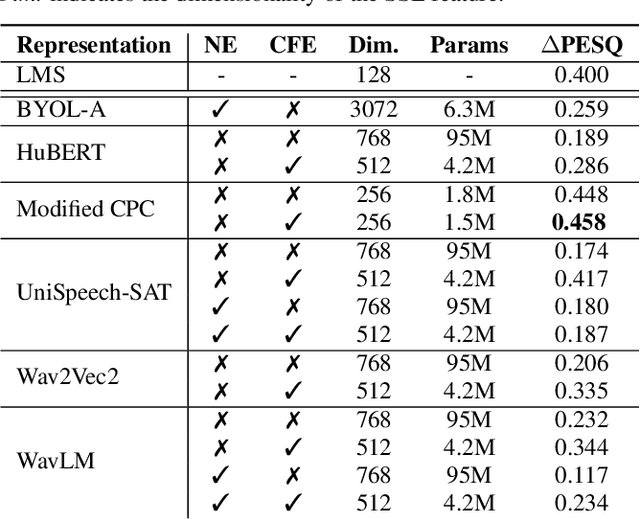
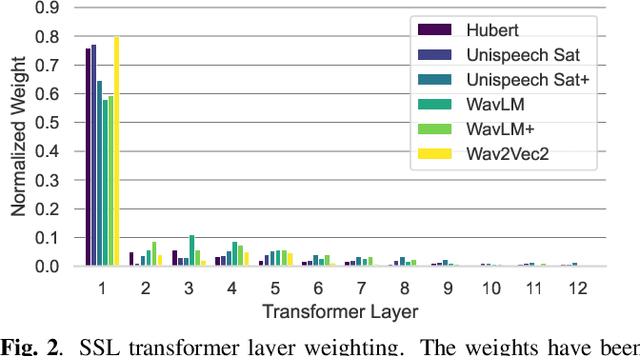
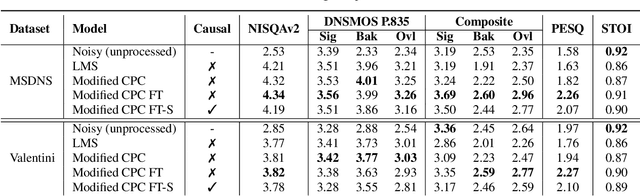
Modern speech enhancement (SE) networks typically implement noise suppression through time-frequency masking, latent representation masking, or discriminative signal prediction. In contrast, some recent works explore SE via generative speech synthesis, where the system's output is synthesized by a neural vocoder after an inherently lossy feature-denoising step. In this paper, we propose a denoising vocoder (DeVo) approach, where a vocoder accepts noisy representations and learns to directly synthesize clean speech. We leverage rich representations from self-supervised learning (SSL) speech models to discover relevant features. We conduct a candidate search across 15 potential SSL front-ends and subsequently train our vocoder adversarially with the best SSL configuration. Additionally, we demonstrate a causal version capable of running on streaming audio with 10ms latency and minimal performance degradation. Finally, we conduct both objective evaluations and subjective listening studies to show our system improves objective metrics and outperforms an existing state-of-the-art SE model subjectively.