 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCATSE: A Context-Aware Framework for Causal Target Sound Extraction
Mar 21, 2024



Target Sound Extraction (TSE) focuses on the problem of separating sources of interest, indicated by a user's cue, from the input mixture. Most existing solutions operate in an offline fashion and are not suited to the low-latency causal processing constraints imposed by applications in live-streamed content such as augmented hearing. We introduce a family of context-aware low-latency causal TSE models suitable for real-time processing. First, we explore the utility of context by providing the TSE model with oracle information about what sound classes make up the input mixture, where the objective of the model is to extract one or more sources of interest indicated by the user. Since the practical applications of oracle models are limited due to their assumptions, we introduce a composite multi-task training objective involving separation and classification losses. Our evaluation involving single- and multi-source extraction shows the benefit of using context information in the model either by means of providing full context or via the proposed multi-task training loss without the need for full context information. Specifically, we show that our proposed model outperforms size- and latency-matched Waveformer, a state-of-the-art model for real-time TSE.
DistPro: Searching A Fast Knowledge Distillation Process via Meta Optimization
Apr 12, 2022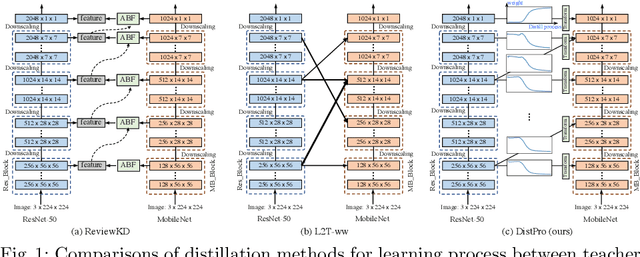
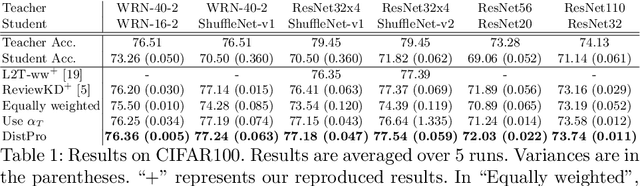

Recent Knowledge distillation (KD) studies show that different manually designed schemes impact the learned results significantly. Yet, in KD, automatically searching an optimal distillation scheme has not yet been well explored. In this paper, we propose DistPro, a novel framework which searches for an optimal KD process via differentiable meta-learning. Specifically, given a pair of student and teacher networks, DistPro first sets up a rich set of KD connection from the transmitting layers of the teacher to the receiving layers of the student, and in the meanwhile, various transforms are also proposed for comparing feature maps along its pathway for the distillation. Then, each combination of a connection and a transform choice (pathway) is associated with a stochastic weighting process which indicates its importance at every step during the distillation. In the searching stage, the process can be effectively learned through our proposed bi-level meta-optimization strategy. In the distillation stage, DistPro adopts the learned processes for knowledge distillation, which significantly improves the student accuracy especially when faster training is required. Lastly, we find the learned processes can be generalized between similar tasks and networks. In our experiments, DistPro produces state-of-the-art (SoTA) accuracy under varying number of learning epochs on popular datasets, i.e. CIFAR100 and ImageNet, which demonstrate the effectiveness of our framework.
NightLab: A Dual-level Architecture with Hardness Detection for Segmentation at Night
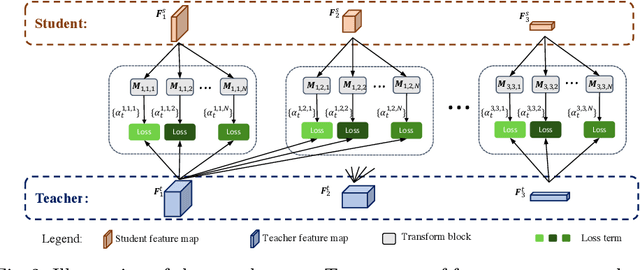
Apr 12, 2022
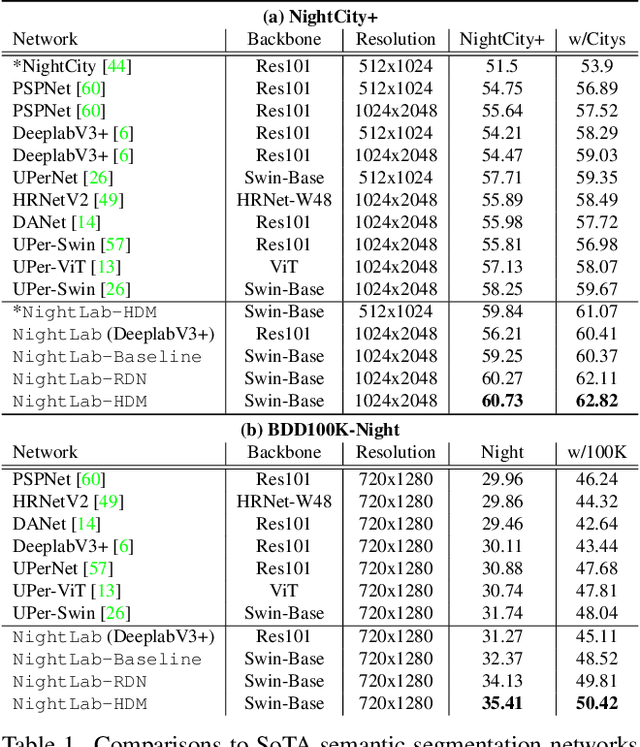
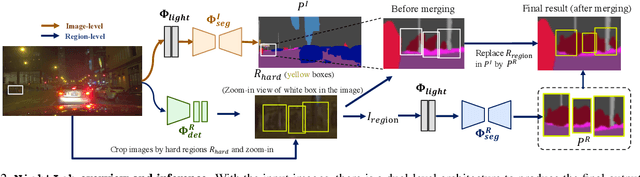

The semantic segmentation of nighttime scenes is a challenging problem that is key to impactful applications like self-driving cars. Yet, it has received little attention compared to its daytime counterpart. In this paper, we propose NightLab, a novel nighttime segmentation framework that leverages multiple deep learning models imbued with night-aware features to yield State-of-The-Art (SoTA) performance on multiple night segmentation benchmarks. Notably, NightLab contains models at two levels of granularity, i.e. image and regional, and each level is composed of light adaptation and segmentation modules. Given a nighttime image, the image level model provides an initial segmentation estimate while, in parallel, a hardness detection module identifies regions and their surrounding context that need further analysis. A regional level model focuses on these difficult regions to provide a significantly improved segmentation. All the models in NightLab are trained end-to-end using a set of proposed night-aware losses without handcrafted heuristics. Extensive experiments on the NightCity and BDD100K datasets show NightLab achieves SoTA performance compared to concurrent methods.
Image Search with Text Feedback by Additive Attention Compositional Learning
Mar 08, 2022
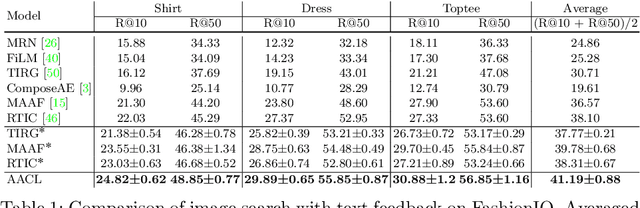
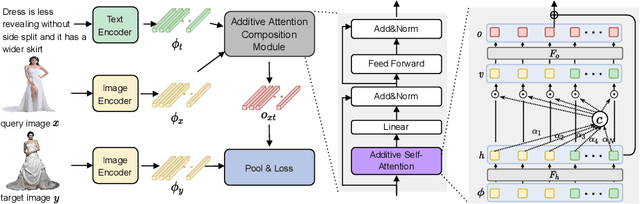
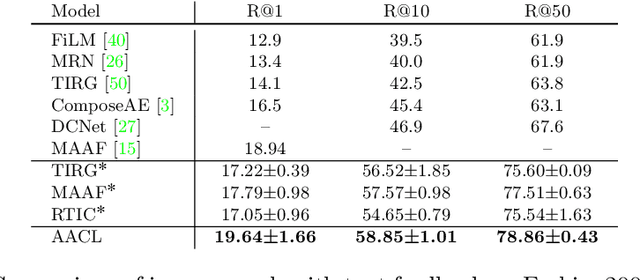
Effective image retrieval with text feedback stands to impact a range of real-world applications, such as e-commerce. Given a source image and text feedback that describes the desired modifications to that image, the goal is to retrieve the target images that resemble the source yet satisfy the given modifications by composing a multi-modal (image-text) query. We propose a novel solution to this problem, Additive Attention Compositional Learning (AACL), that uses a multi-modal transformer-based architecture and effectively models the image-text contexts. Specifically, we propose a novel image-text composition module based on additive attention that can be seamlessly plugged into deep neural networks. We also introduce a new challenging benchmark derived from the Shopping100k dataset. AACL is evaluated on three large-scale datasets (FashionIQ, Fashion200k, and Shopping100k), each with strong baselines. Extensive experiments show that AACL achieves new state-of-the-art results on all three datasets.
AutoAdapt: Automated Segmentation Network Search for Unsupervised Domain Adaptation
Jun 24, 2021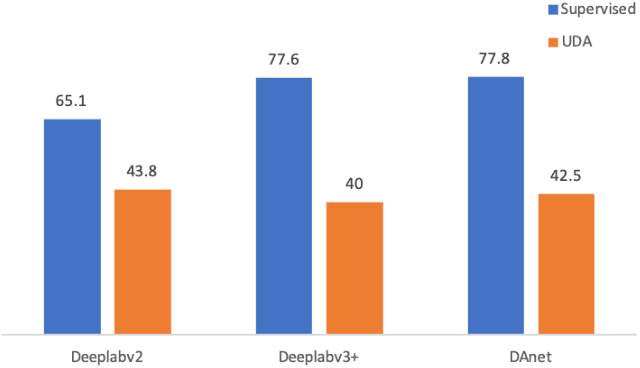
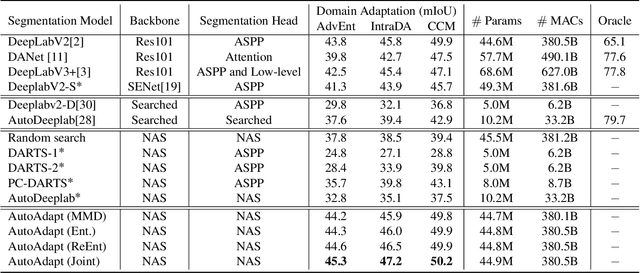

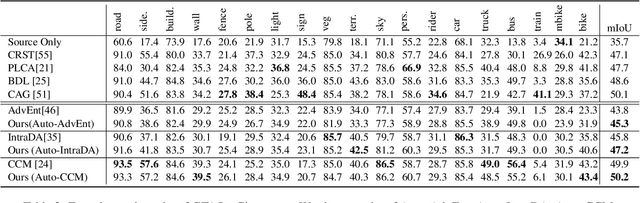
Neural network-based semantic segmentation has achieved remarkable results when large amounts of annotated data are available, that is, in the supervised case. However, such data is expensive to collect and so methods have been developed to adapt models trained on related, often synthetic data for which labels are readily available. Current adaptation approaches do not consider the dependence of the generalization/transferability of these models on network architecture. In this paper, we perform neural architecture search (NAS) to provide architecture-level perspective and analysis for domain adaptation. We identify the optimization gap that exists when searching architectures for unsupervised domain adaptation which makes this NAS problem uniquely difficult. We propose bridging this gap by using maximum mean discrepancy and regional weighted entropy to estimate the accuracy metric. Experimental results on several widely adopted benchmarks show that our proposed AutoAdapt framework indeed discovers architectures that improve the performance of a number of existing adaptation techniques.
Scale Aware Adaptation for Land-Cover Classification in Remote Sensing Imagery
Dec 08, 2020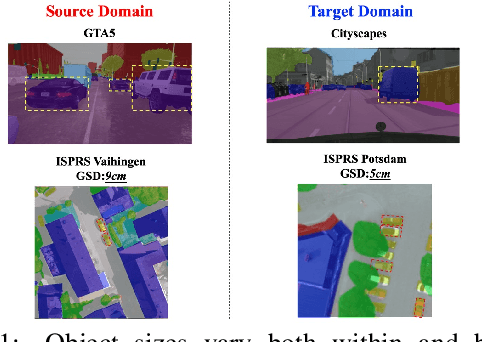

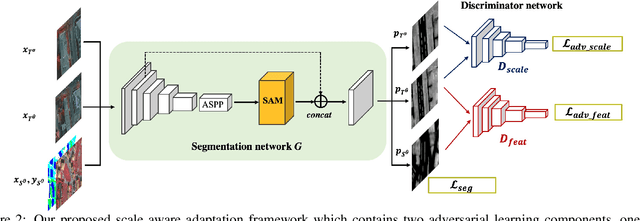

Land-cover classification using remote sensing imagery is an important Earth observation task. Recently, land cover classification has benefited from the development of fully connected neural networks for semantic segmentation. The benchmark datasets available for training deep segmentation models in remote sensing imagery tend to be small, however, often consisting of only a handful of images from a single location with a single scale. This limits the models' ability to generalize to other datasets. Domain adaptation has been proposed to improve the models' generalization but we find these approaches are not effective for dealing with the scale variation commonly found between remote sensing image collections. We therefore propose a scale aware adversarial learning framework to perform joint cross-location and cross-scale land-cover classification. The framework has a dual discriminator architecture with a standard feature discriminator as well as a novel scale discriminator. We also introduce a scale attention module which produces scale-enhanced features. Experimental results show that the proposed framework outperforms state-of-the-art domain adaptation methods by a large margin.
Generalizing Deep Models for Overhead Image Segmentation Through Getis-Ord Gi* Pooling
Dec 23, 2019
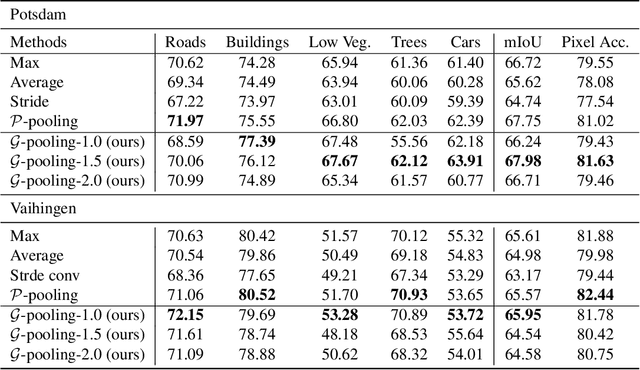

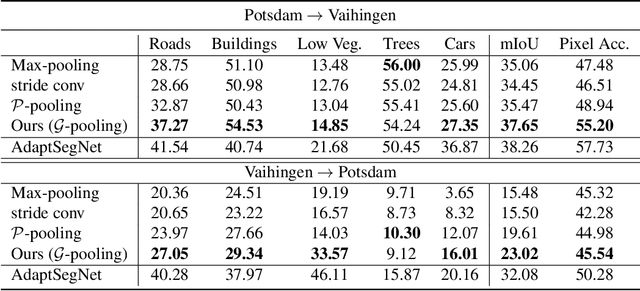
That most deep learning models are purely data driven is both a strength and a weakness. Given sufficient training data, the optimal model for a particular problem can be learned. However, this is usually not the case and so instead the model is either learned from scratch from a limited amount of training data or pre-trained on a different problem and then fine-tuned. Both of these situations are potentially suboptimal and limit the generalizability of the model. Inspired by this, we investigate methods to inform or guide deep learning models for geospatial image analysis to increase their performance when a limited amount of training data is available or when they are applied to scenarios other than which they were trained on. In particular, we exploit the fact that there are certain fundamental rules as to how things are distributed on the surface of the Earth and these rules do not vary substantially between locations. Based on this, we develop a novel feature pooling method for convolutional neural networks using Getis-Ord Gi* analysis from geostatistics. Experimental results show our proposed pooling function has significantly better generalization performance compared to a standard data-driven approach when applied to overhead image segmentation.
Motion-Aware Feature for Improved Video Anomaly Detection
Jul 24, 2019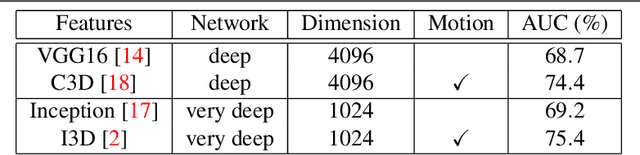
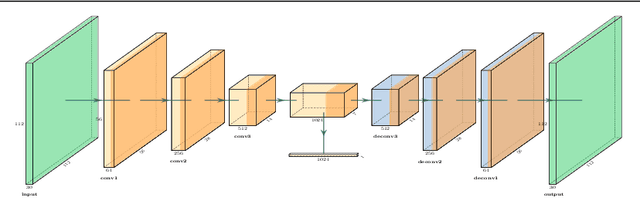
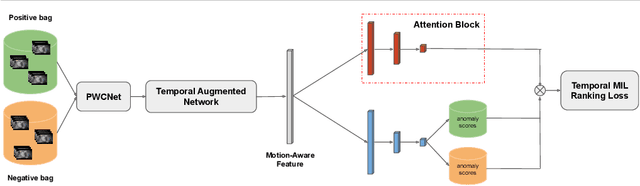
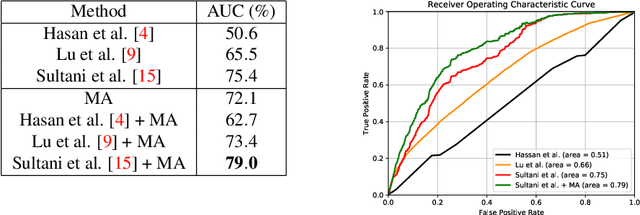
Motivated by our observation that motion information is the key to good anomaly detection performance in video, we propose a temporal augmented network to learn a motion-aware feature. This feature alone can achieve competitive performance with previous state-of-the-art methods, and when combined with them, can achieve significant performance improvements. Furthermore, we incorporate temporal context into the Multiple Instance Learning (MIL) ranking model by using an attention block. The learned attention weights can help to differentiate between anomalous and normal video segments better. With the proposed motion-aware feature and the temporal MIL ranking model, we outperform previous approaches by a large margin on both anomaly detection and anomalous action recognition tasks in the UCF Crime dataset.
Using Conditional Generative Adversarial Networks to Generate Ground-Level Views From Overhead Imagery
Feb 19, 2019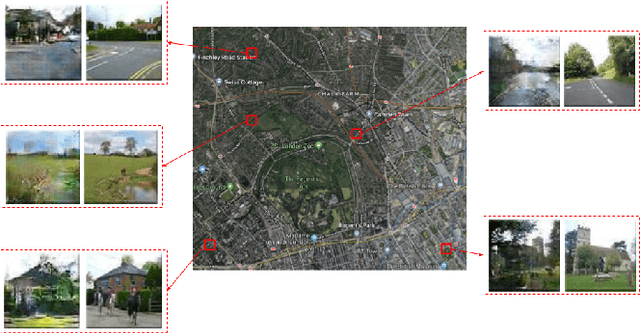
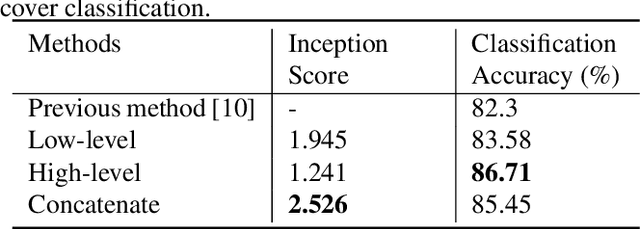
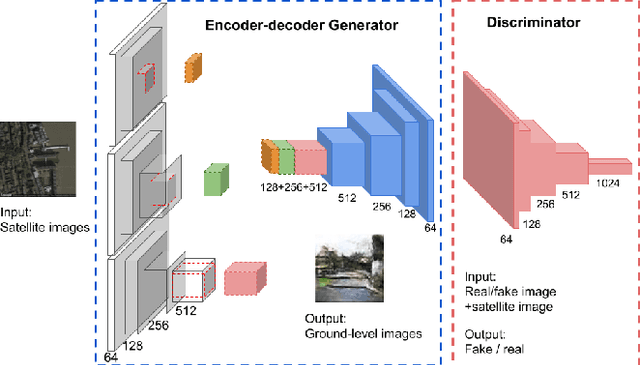

This paper develops a deep-learning framework to synthesize a ground-level view of a location given an overhead image. We propose a novel conditional generative adversarial network (cGAN) in which the trained generator generates realistic looking and representative ground-level images using overhead imagery as auxiliary information. The generator is an encoder-decoder network which allows us to compare low- and high-level features as well as their concatenation for encoding the overhead imagery. We also demonstrate how our framework can be used to perform land cover classification by modifying the trained cGAN to extract features from overhead imagery. This is interesting because, although we are using this modified cGAN as a feature extractor for overhead imagery, it incorporates knowledge of how locations look from the ground.
Improving Semantic Segmentation via Video Propagation and Label Relaxation
Dec 04, 2018
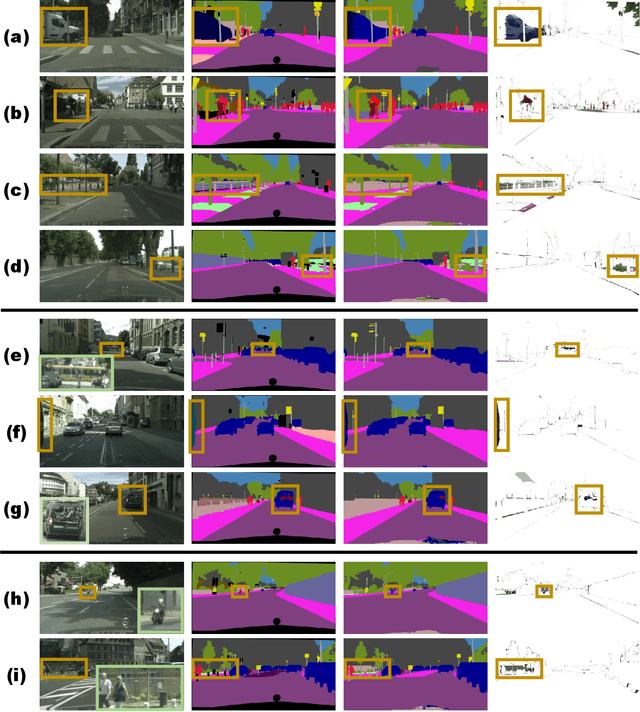

Semantic segmentation requires large amounts of pixel-wise annotations to learn accurate models. In this paper, we present a video prediction-based methodology to scale up training sets by synthesizing new training samples in order to improve the accuracy of semantic segmentation networks. We exploit video prediction models' ability to predict future frames in order to also predict future labels. A joint propagation strategy is also proposed to alleviate mis-alignments in synthesized samples. We demonstrate that training segmentation models on datasets augmented by the synthesized samples leads to significant improvements in accuracy. Furthermore, we introduce a novel boundary label relaxation technique that makes training robust to annotation noise and propagation artifacts along object boundaries. Our proposed methods achieve state-of-the-art mIoUs of 83.5% on Cityscapes and 82.9% on CamVid. Our single model, without model ensembles, achieves 72.8% mIoU on the KITTI semantic segmentation test set, which surpasses the winning entry of the ROB challenge 2018. Our code and videos can be found at https://nv-adlr.github.io/publication/2018-Segmentation.