 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistPro: Searching A Fast Knowledge Distillation Process via Meta Optimization
Paper and Code
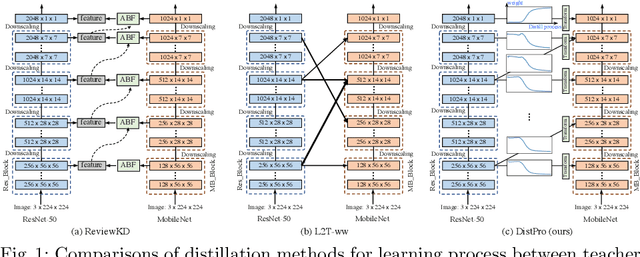
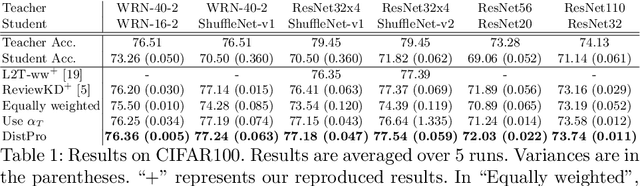
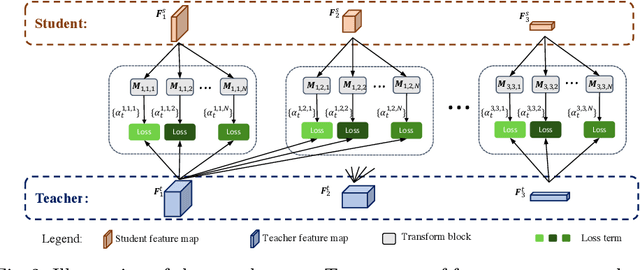

Recent Knowledge distillation (KD) studies show that different manually designed schemes impact the learned results significantly. Yet, in KD, automatically searching an optimal distillation scheme has not yet been well explored. In this paper, we propose DistPro, a novel framework which searches for an optimal KD process via differentiable meta-learning. Specifically, given a pair of student and teacher networks, DistPro first sets up a rich set of KD connection from the transmitting layers of the teacher to the receiving layers of the student, and in the meanwhile, various transforms are also proposed for comparing feature maps along its pathway for the distillation. Then, each combination of a connection and a transform choice (pathway) is associated with a stochastic weighting process which indicates its importance at every step during the distillation. In the searching stage, the process can be effectively learned through our proposed bi-level meta-optimization strategy. In the distillation stage, DistPro adopts the learned processes for knowledge distillation, which significantly improves the student accuracy especially when faster training is required. Lastly, we find the learned processes can be generalized between similar tasks and networks. In our experiments, DistPro produces state-of-the-art (SoTA) accuracy under varying number of learning epochs on popular datasets, i.e. CIFAR100 and ImageNet, which demonstrate the effectiveness of our framework.