 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixel-SAIL: Single Transformer For Pixel-Grounded Understanding
Apr 14, 2025



Multimodal Large Language Models (MLLMs) achieve remarkable performance for fine-grained pixel-level understanding tasks. However, all the works rely heavily on extra components, such as vision encoder (CLIP), segmentation experts, leading to high system complexity and limiting model scaling. In this work, our goal is to explore a highly simplified MLLM without introducing extra components. Our work is motivated by the recent works on Single trAnsformer as a unified vIsion-Language Model (SAIL) design, where these works jointly learn vision tokens and text tokens in transformers. We present Pixel-SAIL, a single transformer for pixel-wise MLLM tasks. In particular, we present three technical improvements on the plain baseline. First, we design a learnable upsampling module to refine visual token features. Secondly, we propose a novel visual prompt injection strategy to enable the single transformer to understand visual prompt inputs and benefit from the early fusion of visual prompt embeddings and vision tokens. Thirdly, we introduce a vision expert distillation strategy to efficiently enhance the single transformer's fine-grained feature extraction capability. In addition, we have collected a comprehensive pixel understanding benchmark (PerBench), using a manual check. It includes three tasks: detailed object description, visual prompt-based question answering, and visual-text referring segmentation. Extensive experiments on four referring segmentation benchmarks, one visual prompt benchmark, and our PerBench show that our Pixel-SAIL achieves comparable or even better results with a much simpler pipeline. Code and model will be released at https://github.com/magic-research/Sa2VA.
COCONut-PanCap: Joint Panoptic Segmentation and Grounded Captions for Fine-Grained Understanding and Generation
Feb 04, 2025This paper introduces the COCONut-PanCap dataset, created to enhance panoptic segmentation and grounded image captioning. Building upon the COCO dataset with advanced COCONut panoptic masks, this dataset aims to overcome limitations in existing image-text datasets that often lack detailed, scene-comprehensive descriptions. The COCONut-PanCap dataset incorporates fine-grained, region-level captions grounded in panoptic segmentation masks, ensuring consistency and improving the detail of generated captions. Through human-edited, densely annotated descriptions, COCONut-PanCap supports improved training of vision-language models (VLMs) for image understanding and generative models for text-to-image tasks. Experimental results demonstrate that COCONut-PanCap significantly boosts performance across understanding and generation tasks, offering complementary benefits to large-scale datasets. This dataset sets a new benchmark for evaluating models on joint panoptic segmentation and grounded captioning tasks, addressing the need for high-quality, detailed image-text annotations in multi-modal learning.
1.58-bit FLUX
Dec 24, 2024We present 1.58-bit FLUX, the first successful approach to quantizing the state-of-the-art text-to-image generation model, FLUX.1-dev, using 1.58-bit weights (i.e., values in {-1, 0, +1}) while maintaining comparable performance for generating 1024 x 1024 images. Notably, our quantization method operates without access to image data, relying solely on self-supervision from the FLUX.1-dev model. Additionally, we develop a custom kernel optimized for 1.58-bit operations, achieving a 7.7x reduction in model storage, a 5.1x reduction in inference memory, and improved inference latency. Extensive evaluations on the GenEval and T2I Compbench benchmarks demonstrate the effectiveness of 1.58-bit FLUX in maintaining generation quality while significantly enhancing computational efficiency.
ViCaS: A Dataset for Combining Holistic and Pixel-level Video Understanding using Captions with Grounded Segmentation
Dec 12, 2024



Recent advances in multimodal large language models (MLLMs) have expanded research in video understanding, primarily focusing on high-level tasks such as video captioning and question-answering. Meanwhile, a smaller body of work addresses dense, pixel-precise segmentation tasks, which typically involve category-guided or referral-based object segmentation. Although both research directions are essential for developing models with human-level video comprehension, they have largely evolved separately, with distinct benchmarks and architectures. This paper aims to unify these efforts by introducing ViCaS, a new dataset containing thousands of challenging videos, each annotated with detailed, human-written captions and temporally consistent, pixel-accurate masks for multiple objects with phrase grounding. Our benchmark evaluates models on both holistic/high-level understanding and language-guided, pixel-precise segmentation. We also present carefully validated evaluation measures and propose an effective model architecture that can tackle our benchmark. Project page: https://ali2500.github.io/vicas-project/
Randomized Autoregressive Visual Generation
Nov 01, 2024This paper presents Randomized AutoRegressive modeling (RAR) for visual generation, which sets a new state-of-the-art performance on the image generation task while maintaining full compatibility with language modeling frameworks. The proposed RAR is simple: during a standard autoregressive training process with a next-token prediction objective, the input sequence-typically ordered in raster form-is randomly permuted into different factorization orders with a probability r, where r starts at 1 and linearly decays to 0 over the course of training. This annealing training strategy enables the model to learn to maximize the expected likelihood over all factorization orders and thus effectively improve the model's capability of modeling bidirectional contexts. Importantly, RAR preserves the integrity of the autoregressive modeling framework, ensuring full compatibility with language modeling while significantly improving performance in image generation. On the ImageNet-256 benchmark, RAR achieves an FID score of 1.48, not only surpassing prior state-of-the-art autoregressive image generators but also outperforming leading diffusion-based and masked transformer-based methods. Code and models will be made available at https://github.com/bytedance/1d-tokenizer
MaskBit: Embedding-free Image Generation via Bit Tokens
Sep 24, 2024



Masked transformer models for class-conditional image generation have become a compelling alternative to diffusion models. Typically comprising two stages - an initial VQGAN model for transitioning between latent space and image space, and a subsequent Transformer model for image generation within latent space - these frameworks offer promising avenues for image synthesis. In this study, we present two primary contributions: Firstly, an empirical and systematic examination of VQGANs, leading to a modernized VQGAN. Secondly, a novel embedding-free generation network operating directly on bit tokens - a binary quantized representation of tokens with rich semantics. The first contribution furnishes a transparent, reproducible, and high-performing VQGAN model, enhancing accessibility and matching the performance of current state-of-the-art methods while revealing previously undisclosed details. The second contribution demonstrates that embedding-free image generation using bit tokens achieves a new state-of-the-art FID of 1.52 on the ImageNet 256x256 benchmark, with a compact generator model of mere 305M parameters.
An Image is Worth 32 Tokens for Reconstruction and Generation
Jun 11, 2024



Recent advancements in generative models have highlighted the crucial role of image tokenization in the efficient synthesis of high-resolution images. Tokenization, which transforms images into latent representations, reduces computational demands compared to directly processing pixels and enhances the effectiveness and efficiency of the generation process. Prior methods, such as VQGAN, typically utilize 2D latent grids with fixed downsampling factors. However, these 2D tokenizations face challenges in managing the inherent redundancies present in images, where adjacent regions frequently display similarities. To overcome this issue, we introduce Transformer-based 1-Dimensional Tokenizer (TiTok), an innovative approach that tokenizes images into 1D latent sequences. TiTok provides a more compact latent representation, yielding substantially more efficient and effective representations than conventional techniques. For example, a 256 x 256 x 3 image can be reduced to just 32 discrete tokens, a significant reduction from the 256 or 1024 tokens obtained by prior methods. Despite its compact nature, TiTok achieves competitive performance to state-of-the-art approaches. Specifically, using the same generator framework, TiTok attains 1.97 gFID, outperforming MaskGIT baseline significantly by 4.21 at ImageNet 256 x 256 benchmark. The advantages of TiTok become even more significant when it comes to higher resolution. At ImageNet 512 x 512 benchmark, TiTok not only outperforms state-of-the-art diffusion model DiT-XL/2 (gFID 2.74 vs. 3.04), but also reduces the image tokens by 64x, leading to 410x faster generation process. Our best-performing variant can significantly surpasses DiT-XL/2 (gFID 2.13 vs. 3.04) while still generating high-quality samples 74x faster.
Enhancing 3D Fidelity of Text-to-3D using Cross-View Correspondences
Apr 16, 2024

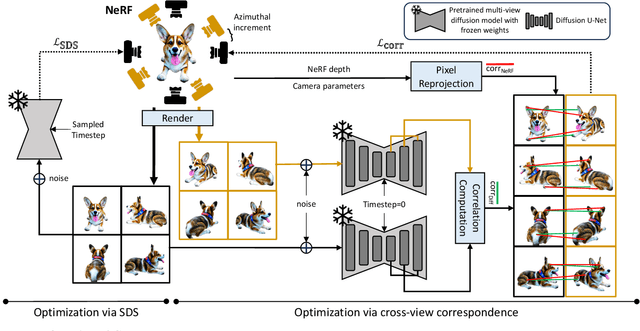

Leveraging multi-view diffusion models as priors for 3D optimization have alleviated the problem of 3D consistency, e.g., the Janus face problem or the content drift problem, in zero-shot text-to-3D models. However, the 3D geometric fidelity of the output remains an unresolved issue; albeit the rendered 2D views are realistic, the underlying geometry may contain errors such as unreasonable concavities. In this work, we propose CorrespondentDream, an effective method to leverage annotation-free, cross-view correspondences yielded from the diffusion U-Net to provide additional 3D prior to the NeRF optimization process. We find that these correspondences are strongly consistent with human perception, and by adopting it in our loss design, we are able to produce NeRF models with geometries that are more coherent with common sense, e.g., more smoothed object surface, yielding higher 3D fidelity. We demonstrate the efficacy of our approach through various comparative qualitative results and a solid user study.
COCONut: Modernizing COCO Segmentation
Apr 12, 2024



In recent decades, the vision community has witnessed remarkable progress in visual recognition, partially owing to advancements in dataset benchmarks. Notably, the established COCO benchmark has propelled the development of modern detection and segmentation systems. However, the COCO segmentation benchmark has seen comparatively slow improvement over the last decade. Originally equipped with coarse polygon annotations for thing instances, it gradually incorporated coarse superpixel annotations for stuff regions, which were subsequently heuristically amalgamated to yield panoptic segmentation annotations. These annotations, executed by different groups of raters, have resulted not only in coarse segmentation masks but also in inconsistencies between segmentation types. In this study, we undertake a comprehensive reevaluation of the COCO segmentation annotations. By enhancing the annotation quality and expanding the dataset to encompass 383K images with more than 5.18M panoptic masks, we introduce COCONut, the COCO Next Universal segmenTation dataset. COCONut harmonizes segmentation annotations across semantic, instance, and panoptic segmentation with meticulously crafted high-quality masks, and establishes a robust benchmark for all segmentation tasks. To our knowledge, COCONut stands as the inaugural large-scale universal segmentation dataset, verified by human raters. We anticipate that the release of COCONut will significantly contribute to the community's ability to assess the progress of novel neural networks.
MaXTron: Mask Transformer with Trajectory Attention for Video Panoptic Segmentation
Nov 30, 2023Video panoptic segmentation requires consistently segmenting (for both `thing' and `stuff' classes) and tracking objects in a video over time. In this work, we present MaXTron, a general framework that exploits Mask XFormer with Trajectory Attention to tackle the task. MaXTron enriches an off-the-shelf mask transformer by leveraging trajectory attention. The deployed mask transformer takes as input a short clip consisting of only a few frames and predicts the clip-level segmentation. To enhance the temporal consistency, MaXTron employs within-clip and cross-clip tracking modules, efficiently utilizing trajectory attention. Originally designed for video classification, trajectory attention learns to model the temporal correspondences between neighboring frames and aggregates information along the estimated motion paths. However, it is nontrivial to directly extend trajectory attention to the per-pixel dense prediction tasks due to its quadratic dependency on input size. To alleviate the issue, we propose to adapt the trajectory attention for both the dense pixel features and object queries, aiming to improve the short-term and long-term tracking results, respectively. Particularly, in our within-clip tracking module, we propose axial-trajectory attention that effectively computes the trajectory attention for tracking dense pixels sequentially along the height- and width-axes. The axial decomposition significantly reduces the computational complexity for dense pixel features. In our cross-clip tracking module, since the object queries in mask transformer are learned to encode the object information, we are able to capture the long-term temporal connections by applying trajectory attention to object queries, which learns to track each object across different clips. Without bells and whistles, MaXTron demonstrates state-of-the-art performances on video segmentation benchmarks.