 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-Free Metrics for Synthetic Object Detection Data: A Proxy for Detector Performance
Jun 18, 2026With the recent advent of image generative models, synthetic data are increasingly being used to supplement limited real datasets for training computer vision models. However, not all synthetic datasets improve performance equally, and their effectiveness can only be assessed by training a downstream model, which is computationally expensive and time-consuming. This problem is pronounced in the task of object detection, where the required annotations are much more dense due to bounding boxes. In this paper, we propose a pre-computable metric family, dubbed Conditional-Composition Domain Match (CCDM), which serves as a proxy for the relative utility of candidate synthetic training sets for downstream detection. Experiments on the VisDrone-DET dataset show that the CCDM metric families achieve a Spearman correlation of 1.0 with the downstream performance of YOLOv8, clearly outperforming existing metrics for synthetic image evaluation.
Improving Text-to-Image Generation with Intrinsic Self-Confidence Rewards
Mar 05, 2026Text-to-image generation powers content creation across design, media, and data augmentation. Post-training of text-to-image generative models is a promising path to better match human preferences, factuality, and improved aesthetics. We introduce SOLACE (Adaptive Rewarding by self-Confidence), a post-training framework that replaces external reward supervision with an internal self-confidence signal, obtained by evaluating how accurately the model recovers injected noise under self-denoising probes. SOLACE converts this intrinsic signal into scalar rewards, enabling fully unsupervised optimization without additional datasets, annotators, or reward models. Empirically, by reinforcing high-confidence generations, SOLACE delivers consistent gains in compositional generation, text rendering and text-image alignment over the baseline. We also find that integrating SOLACE with external rewards results in a complementary improvement, with alleviated reward hacking.
Harnessing the Power of Training-Free Techniques in Text-to-2D Generation for Text-to-3D Generation via Score Distillation Sampling
May 26, 2025Recent studies show that simple training-free techniques can dramatically improve the quality of text-to-2D generation outputs, e.g. Classifier-Free Guidance (CFG) or FreeU. However, these training-free techniques have been underexplored in the lens of Score Distillation Sampling (SDS), which is a popular and effective technique to leverage the power of pretrained text-to-2D diffusion models for various tasks. In this paper, we aim to shed light on the effect such training-free techniques have on SDS, via a particular application of text-to-3D generation via 2D lifting. We present our findings, which show that varying the scales of CFG presents a trade-off between object size and surface smoothness, while varying the scales of FreeU presents a trade-off between texture details and geometric errors. Based on these findings, we provide insights into how we can effectively harness training-free techniques for SDS, via a strategic scaling of such techniques in a dynamic manner with respect to the timestep or optimization iteration step. We show that using our proposed scheme strikes a favorable balance between texture details and surface smoothness in text-to-3D generations, while preserving the size of the output and mitigating the occurrence of geometric defects.
3D Geometric Shape Assembly via Efficient Point Cloud Matching
Jul 15, 2024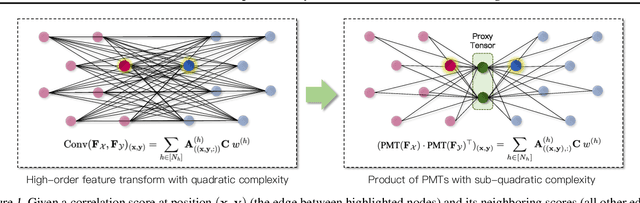
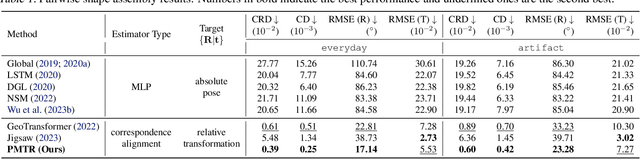
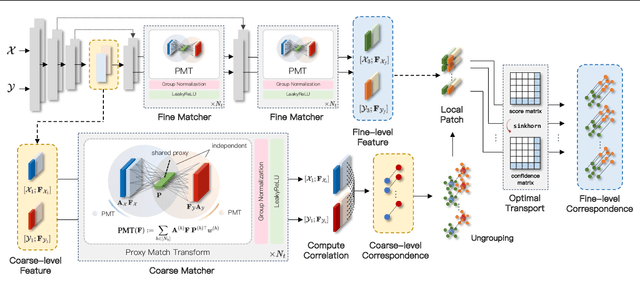
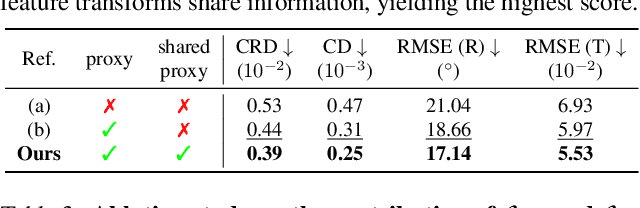
Learning to assemble geometric shapes into a larger target structure is a pivotal task in various practical applications. In this work, we tackle this problem by establishing local correspondences between point clouds of part shapes in both coarse- and fine-levels. To this end, we introduce Proxy Match Transform (PMT), an approximate high-order feature transform layer that enables reliable matching between mating surfaces of parts while incurring low costs in memory and computation. Building upon PMT, we introduce a new framework, dubbed Proxy Match TransformeR (PMTR), for the geometric assembly task. We evaluate the proposed PMTR on the large-scale 3D geometric shape assembly benchmark dataset of Breaking Bad and demonstrate its superior performance and efficiency compared to state-of-the-art methods. Project page: https://nahyuklee.github.io/pmtr.
Multi-view Image Prompted Multi-view Diffusion for Improved 3D Generation
Apr 26, 2024Using image as prompts for 3D generation demonstrate particularly strong performances compared to using text prompts alone, for images provide a more intuitive guidance for the 3D generation process. In this work, we delve into the potential of using multiple image prompts, instead of a single image prompt, for 3D generation. Specifically, we build on ImageDream, a novel image-prompt multi-view diffusion model, to support multi-view images as the input prompt. Our method, dubbed MultiImageDream, reveals that transitioning from a single-image prompt to multiple-image prompts enhances the performance of multi-view and 3D object generation according to various quantitative evaluation metrics and qualitative assessments. This advancement is achieved without the necessity of fine-tuning the pre-trained ImageDream multi-view diffusion model.
Enhancing 3D Fidelity of Text-to-3D using Cross-View Correspondences
Apr 16, 2024

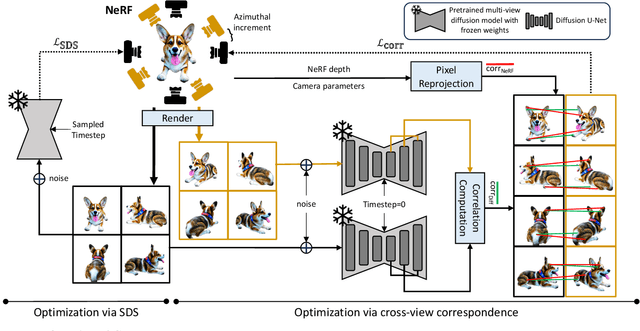

Leveraging multi-view diffusion models as priors for 3D optimization have alleviated the problem of 3D consistency, e.g., the Janus face problem or the content drift problem, in zero-shot text-to-3D models. However, the 3D geometric fidelity of the output remains an unresolved issue; albeit the rendered 2D views are realistic, the underlying geometry may contain errors such as unreasonable concavities. In this work, we propose CorrespondentDream, an effective method to leverage annotation-free, cross-view correspondences yielded from the diffusion U-Net to provide additional 3D prior to the NeRF optimization process. We find that these correspondences are strongly consistent with human perception, and by adopting it in our loss design, we are able to produce NeRF models with geometries that are more coherent with common sense, e.g., more smoothed object surface, yielding higher 3D fidelity. We demonstrate the efficacy of our approach through various comparative qualitative results and a solid user study.
Efficient Semantic Matching with Hypercolumn Correlation
Nov 07, 2023Recent studies show that leveraging the match-wise relationships within the 4D correlation map yields significant improvements in establishing semantic correspondences - but at the cost of increased computation and latency. In this work, we focus on the aspect that the performance improvements of recent methods can also largely be attributed to the usage of multi-scale correlation maps, which hold various information ranging from low-level geometric cues to high-level semantic contexts. To this end, we propose HCCNet, an efficient yet effective semantic matching method which exploits the full potential of multi-scale correlation maps, while eschewing the reliance on expensive match-wise relationship mining on the 4D correlation map. Specifically, HCCNet performs feature slicing on the bottleneck features to yield a richer set of intermediate features, which are used to construct a hypercolumn correlation. HCCNet can consequently establish semantic correspondences in an effective manner by reducing the volume of conventional high-dimensional convolution or self-attention operations to efficient point-wise convolutions. HCCNet demonstrates state-of-the-art or competitive performances on the standard benchmarks of semantic matching, while incurring a notably lower latency and computation overhead compared to the existing SoTA methods.
Stable and Consistent Prediction of 3D Characteristic Orientation via Invariant Residual Learning
Jun 20, 2023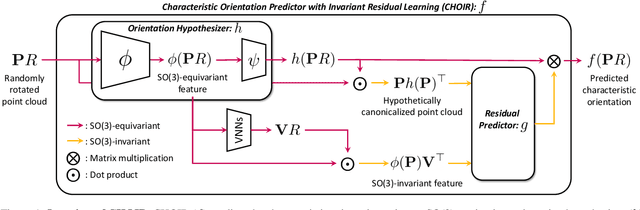

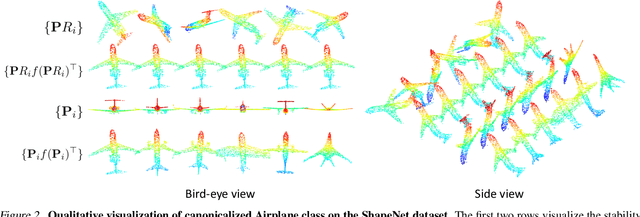

Learning to predict reliable characteristic orientations of 3D point clouds is an important yet challenging problem, as different point clouds of the same class may have largely varying appearances. In this work, we introduce a novel method to decouple the shape geometry and semantics of the input point cloud to achieve both stability and consistency. The proposed method integrates shape-geometry-based SO(3)-equivariant learning and shape-semantics-based SO(3)-invariant residual learning, where a final characteristic orientation is obtained by calibrating an SO(3)-equivariant orientation hypothesis using an SO(3)-invariant residual rotation. In experiments, the proposed method not only demonstrates superior stability and consistency but also exhibits state-of-the-art performances when applied to point cloud part segmentation, given randomly rotated inputs.
Learning Rotation-Equivariant Features for Visual Correspondence
Mar 25, 2023Extracting discriminative local features that are invariant to imaging variations is an integral part of establishing correspondences between images. In this work, we introduce a self-supervised learning framework to extract discriminative rotation-invariant descriptors using group-equivariant CNNs. Thanks to employing group-equivariant CNNs, our method effectively learns to obtain rotation-equivariant features and their orientations explicitly, without having to perform sophisticated data augmentations. The resultant features and their orientations are further processed by group aligning, a novel invariant mapping technique that shifts the group-equivariant features by their orientations along the group dimension. Our group aligning technique achieves rotation-invariance without any collapse of the group dimension and thus eschews loss of discriminability. The proposed method is trained end-to-end in a self-supervised manner, where we use an orientation alignment loss for the orientation estimation and a contrastive descriptor loss for robust local descriptors to geometric/photometric variations. Our method demonstrates state-of-the-art matching accuracy among existing rotation-invariant descriptors under varying rotation and also shows competitive results when transferred to the task of keypoint matching and camera pose estimation.
TransforMatcher: Match-to-Match Attention for Semantic Correspondence
May 23, 2022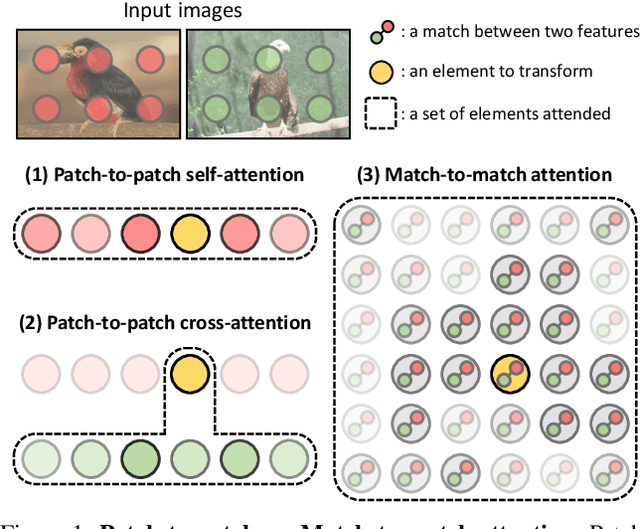
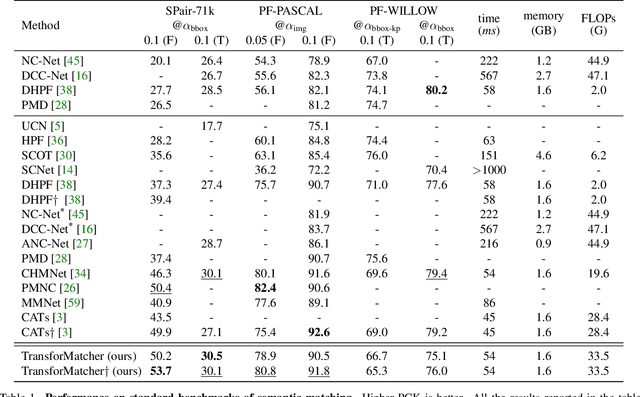
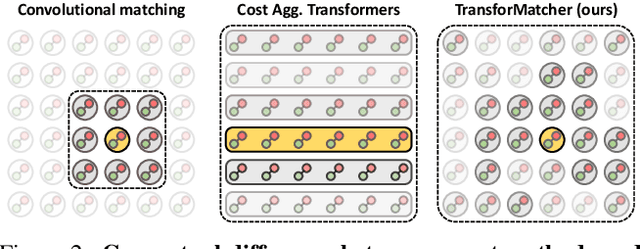
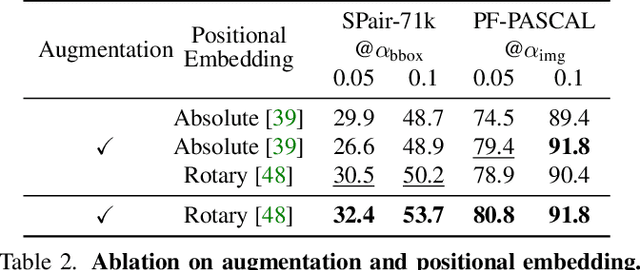
Establishing correspondences between images remains a challenging task, especially under large appearance changes due to different viewpoints or intra-class variations. In this work, we introduce a strong semantic image matching learner, dubbed TransforMatcher, which builds on the success of transformer networks in vision domains. Unlike existing convolution- or attention-based schemes for correspondence, TransforMatcher performs global match-to-match attention for precise match localization and dynamic refinement. To handle a large number of matches in a dense correlation map, we develop a light-weight attention architecture to consider the global match-to-match interactions. We also propose to utilize a multi-channel correlation map for refinement, treating the multi-level scores as features instead of a single score to fully exploit the richer layer-wise semantics. In experiments, TransforMatcher sets a new state of the art on SPair-71k while performing on par with existing SOTA methods on the PF-PASCAL dataset.