 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoveated Reasoning: Stateful, Action-based Visual Focusing for Vision-Language Models
Apr 22, 2026Vision-language models benefit from high-resolution images, but the increase in visual-token count incurs high compute overhead. Humans resolve this tension via foveation: a coarse view guides "where to look", while selectively acquired high-acuity evidence refines "what to think". We introduce Foveated Reasoner, an autoregressive vision-language framework that unifies foveation and reasoning within a single decoding trajectory. Starting from a low-resolution view, the model triggers foveation only when needed, retrieves high-resolution evidence from selected regions, and injects it back into the same decoding trajectory. We train the method with a two-stage pipeline: coldstart supervision to bootstrap foveation behavior, followed by reinforcement learning to jointly improve evidence acquisition and task accuracy while discouraging trivial "see-everything" solutions. Experiments show that the method learns effective foveation policies and achieves stronger accuracy under tight visual-token budgets across multiple vision-language benchmarks.
GoldiCLIP: The Goldilocks Approach for Balancing Explicit Supervision for Language-Image Pretraining
Mar 25, 2026Until recently, the success of large-scale vision-language models (VLMs) has primarily relied on billion-sample datasets, posing a significant barrier to progress. Latest works have begun to close this gap by improving supervision quality, but each addresses only a subset of the weaknesses in contrastive pretraining. We present GoldiCLIP, a framework built on a Goldilocks principle of finding the right balance of supervision signals. Our multifaceted training framework synergistically combines three key innovations: (1) a text-conditioned self-distillation method to align both text-agnostic and text-conditioned features; (2) an encoder integrated decoder with Visual Question Answering (VQA) objective that enables the encoder to generalize beyond the caption-like queries; and (3) an uncertainty-based weighting mechanism that automatically balances all heterogeneous losses. Trained on just 30 million images, 300x less data than leading methods, GoldiCLIP achieves state-of-the-art among data-efficient approaches, improving over the best comparable baseline by 2.2 points on MSCOCO retrieval, 2.0 on fine-grained retrieval, and 5.9 on question-based retrieval, while remaining competitive with billion-scale models. Project page: https://petsi.uk/goldiclip.
3D Geometric Shape Assembly via Efficient Point Cloud Matching
Jul 15, 2024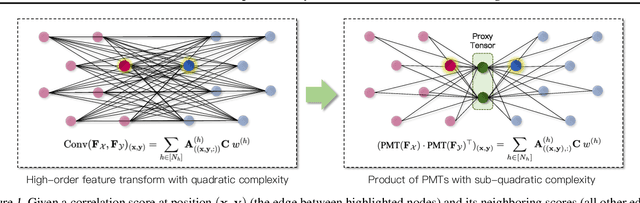
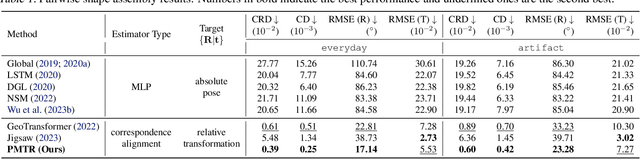
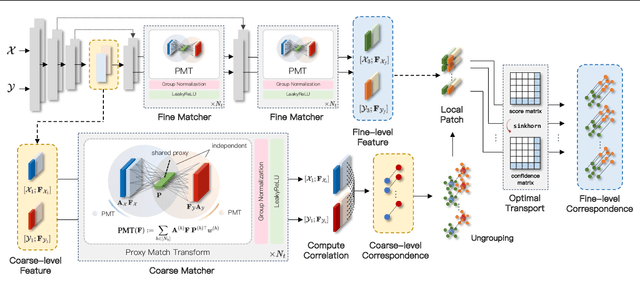
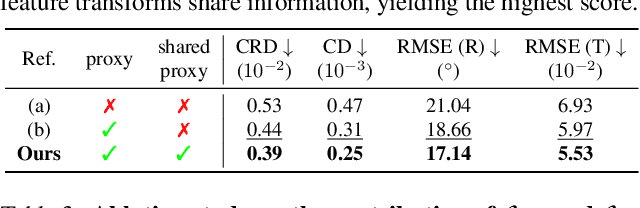
Learning to assemble geometric shapes into a larger target structure is a pivotal task in various practical applications. In this work, we tackle this problem by establishing local correspondences between point clouds of part shapes in both coarse- and fine-levels. To this end, we introduce Proxy Match Transform (PMT), an approximate high-order feature transform layer that enables reliable matching between mating surfaces of parts while incurring low costs in memory and computation. Building upon PMT, we introduce a new framework, dubbed Proxy Match TransformeR (PMTR), for the geometric assembly task. We evaluate the proposed PMTR on the large-scale 3D geometric shape assembly benchmark dataset of Breaking Bad and demonstrate its superior performance and efficiency compared to state-of-the-art methods. Project page: https://nahyuklee.github.io/pmtr.
MoReVQA: Exploring Modular Reasoning Models for Video Question Answering
Apr 09, 2024This paper addresses the task of video question answering (videoQA) via a decomposed multi-stage, modular reasoning framework. Previous modular methods have shown promise with a single planning stage ungrounded in visual content. However, through a simple and effective baseline, we find that such systems can lead to brittle behavior in practice for challenging videoQA settings. Thus, unlike traditional single-stage planning methods, we propose a multi-stage system consisting of an event parser, a grounding stage, and a final reasoning stage in conjunction with an external memory. All stages are training-free, and performed using few-shot prompting of large models, creating interpretable intermediate outputs at each stage. By decomposing the underlying planning and task complexity, our method, MoReVQA, improves over prior work on standard videoQA benchmarks (NExT-QA, iVQA, EgoSchema, ActivityNet-QA) with state-of-the-art results, and extensions to related tasks (grounded videoQA, paragraph captioning).
Efficient Semantic Matching with Hypercolumn Correlation
Nov 07, 2023Recent studies show that leveraging the match-wise relationships within the 4D correlation map yields significant improvements in establishing semantic correspondences - but at the cost of increased computation and latency. In this work, we focus on the aspect that the performance improvements of recent methods can also largely be attributed to the usage of multi-scale correlation maps, which hold various information ranging from low-level geometric cues to high-level semantic contexts. To this end, we propose HCCNet, an efficient yet effective semantic matching method which exploits the full potential of multi-scale correlation maps, while eschewing the reliance on expensive match-wise relationship mining on the 4D correlation map. Specifically, HCCNet performs feature slicing on the bottleneck features to yield a richer set of intermediate features, which are used to construct a hypercolumn correlation. HCCNet can consequently establish semantic correspondences in an effective manner by reducing the volume of conventional high-dimensional convolution or self-attention operations to efficient point-wise convolutions. HCCNet demonstrates state-of-the-art or competitive performances on the standard benchmarks of semantic matching, while incurring a notably lower latency and computation overhead compared to the existing SoTA methods.
Peripheral Vision Transformer
Jun 14, 2022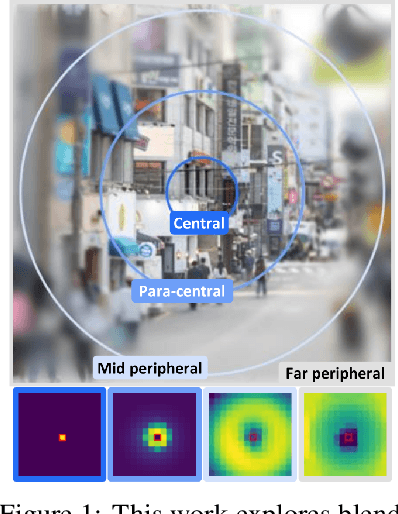

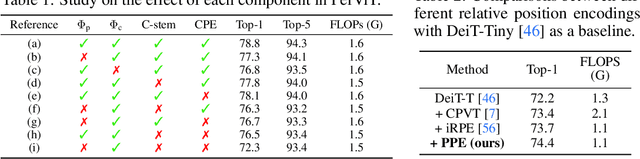
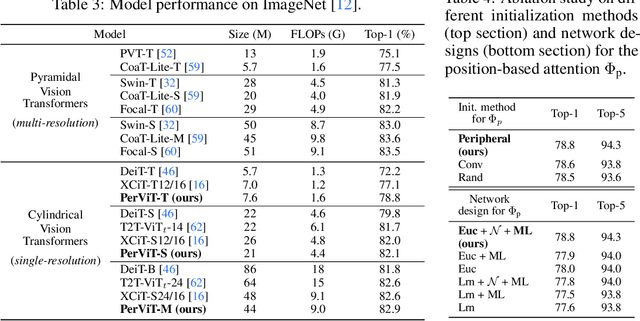
Human vision possesses a special type of visual processing systems called peripheral vision. Partitioning the entire visual field into multiple contour regions based on the distance to the center of our gaze, the peripheral vision provides us the ability to perceive various visual features at different regions. In this work, we take a biologically inspired approach and explore to model peripheral vision in deep neural networks for visual recognition. We propose to incorporate peripheral position encoding to the multi-head self-attention layers to let the network learn to partition the visual field into diverse peripheral regions given training data. We evaluate the proposed network, dubbed PerViT, on the large-scale ImageNet dataset and systematically investigate the inner workings of the model for machine perception, showing that the network learns to perceive visual data similarly to the way that human vision does. The state-of-the-art performance in image classification task across various model sizes demonstrates the efficacy of the proposed method.
TransforMatcher: Match-to-Match Attention for Semantic Correspondence
May 23, 2022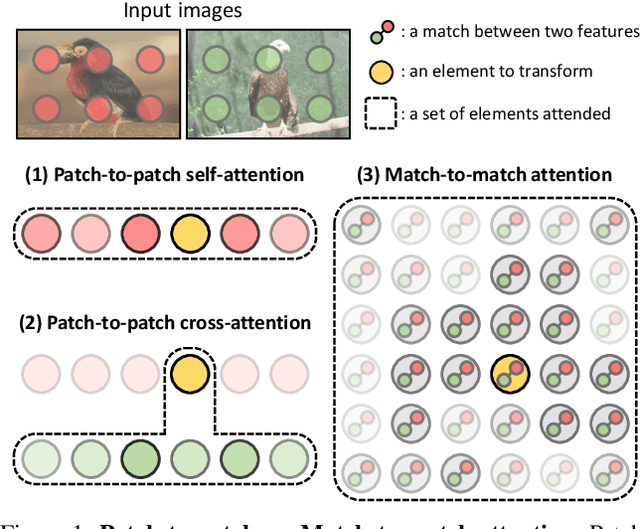
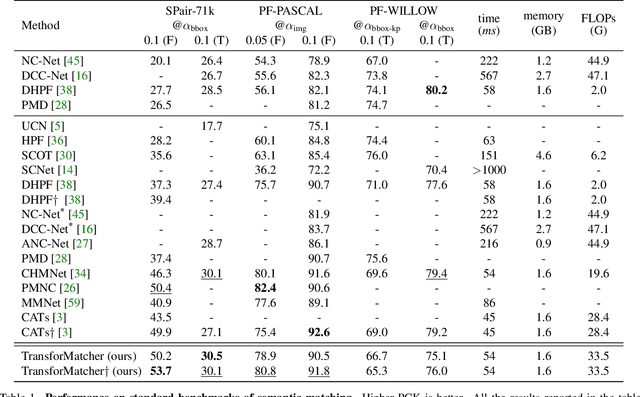
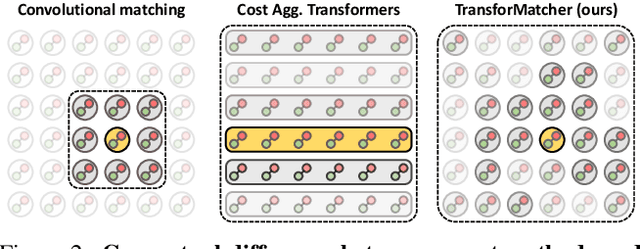
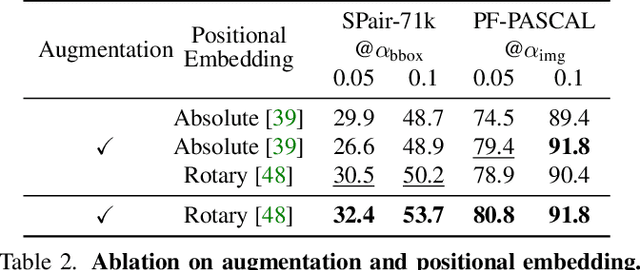
Establishing correspondences between images remains a challenging task, especially under large appearance changes due to different viewpoints or intra-class variations. In this work, we introduce a strong semantic image matching learner, dubbed TransforMatcher, which builds on the success of transformer networks in vision domains. Unlike existing convolution- or attention-based schemes for correspondence, TransforMatcher performs global match-to-match attention for precise match localization and dynamic refinement. To handle a large number of matches in a dense correlation map, we develop a light-weight attention architecture to consider the global match-to-match interactions. We also propose to utilize a multi-channel correlation map for refinement, treating the multi-level scores as features instead of a single score to fully exploit the richer layer-wise semantics. In experiments, TransforMatcher sets a new state of the art on SPair-71k while performing on par with existing SOTA methods on the PF-PASCAL dataset.
Convolutional Hough Matching Networks for Robust and Efficient Visual Correspondence
Sep 11, 2021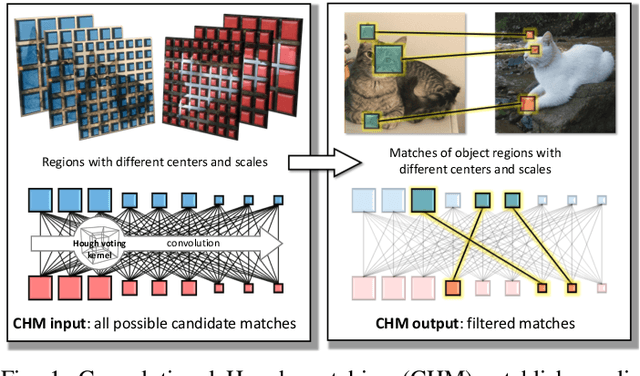
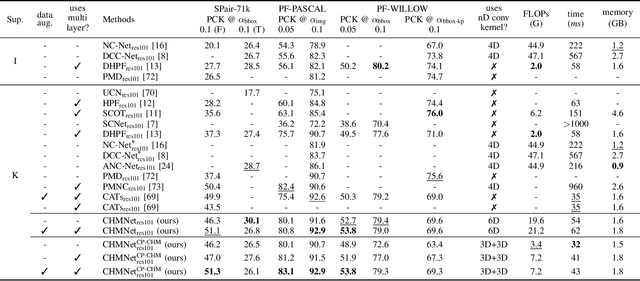
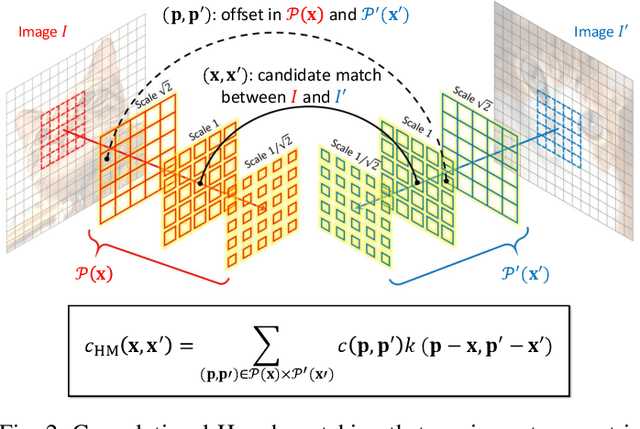

Despite advances in feature representation, leveraging geometric relations is crucial for establishing reliable visual correspondences under large variations of images. In this work we introduce a Hough transform perspective on convolutional matching and propose an effective geometric matching algorithm, dubbed Convolutional Hough Matching (CHM). The method distributes similarities of candidate matches over a geometric transformation space and evaluates them in a convolutional manner. We cast it into a trainable neural layer with a semi-isotropic high-dimensional kernel, which learns non-rigid matching with a small number of interpretable parameters. To further improve the efficiency of high-dimensional voting, we also propose to use an efficient kernel decomposition with center-pivot neighbors, which significantly sparsifies the proposed semi-isotropic kernels without performance degradation. To validate the proposed techniques, we develop the neural network with CHM layers that perform convolutional matching in the space of translation and scaling. Our method sets a new state of the art on standard benchmarks for semantic visual correspondence, proving its strong robustness to challenging intra-class variations.
Relational Embedding for Few-Shot Classification
Aug 22, 2021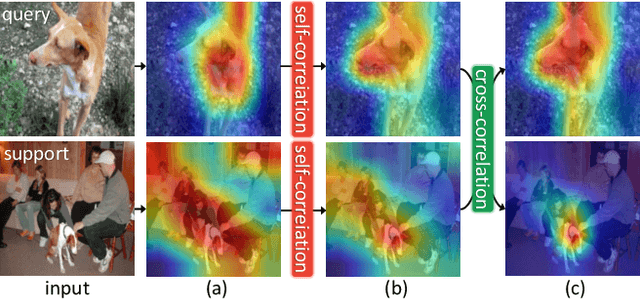
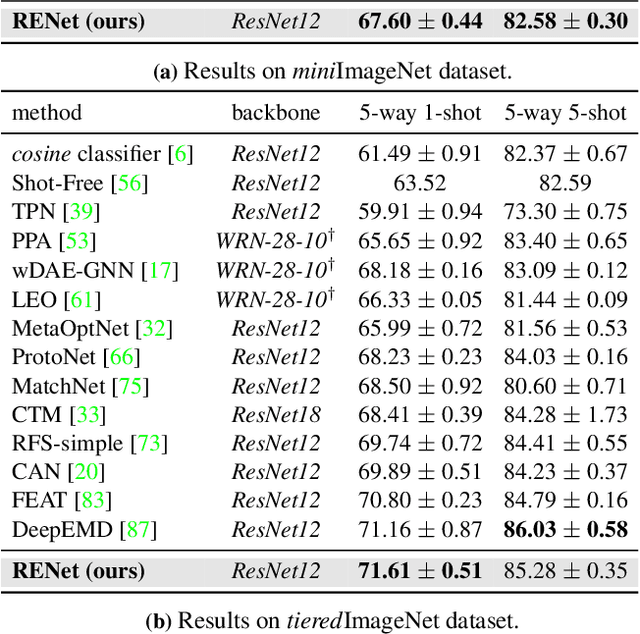


We propose to address the problem of few-shot classification by meta-learning "what to observe" and "where to attend" in a relational perspective. Our method leverages relational patterns within and between images via self-correlational representation (SCR) and cross-correlational attention (CCA). Within each image, the SCR module transforms a base feature map into a self-correlation tensor and learns to extract structural patterns from the tensor. Between the images, the CCA module computes cross-correlation between two image representations and learns to produce co-attention between them. Our Relational Embedding Network (RENet) combines the two relational modules to learn relational embedding in an end-to-end manner. In experimental evaluation, it achieves consistent improvements over state-of-the-art methods on four widely used few-shot classification benchmarks of miniImageNet, tieredImageNet, CUB-200-2011, and CIFAR-FS.
Hypercorrelation Squeeze for Few-Shot Segmentation
Apr 04, 2021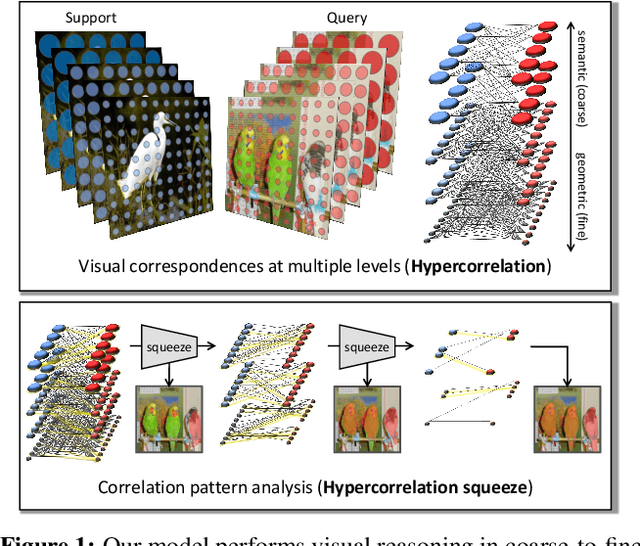
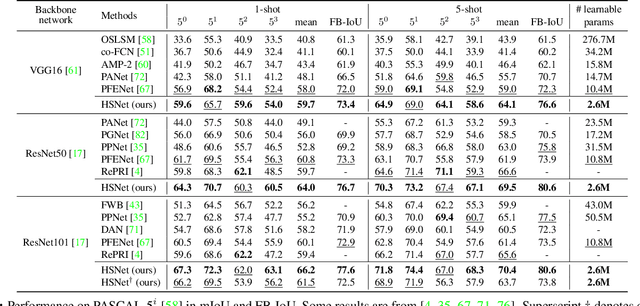
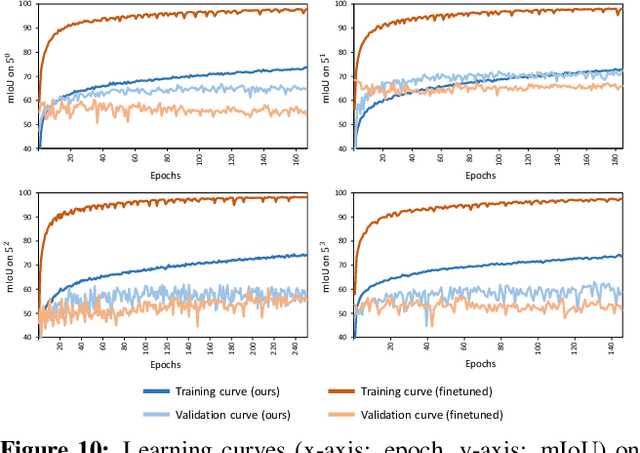
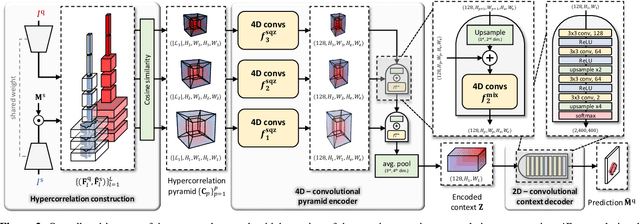
Few-shot semantic segmentation aims at learning to segment a target object from a query image using only a few annotated support images of the target class. This challenging task requires to understand diverse levels of visual cues and analyze fine-grained correspondence relations between the query and the support images. To address the problem, we propose Hypercorrelation Squeeze Networks (HSNet) that leverages multi-level feature correlation and efficient 4D convolutions. It extracts diverse features from different levels of intermediate convolutional layers and constructs a collection of 4D correlation tensors, i.e., hypercorrelations. Using efficient center-pivot 4D convolutions in a pyramidal architecture, the method gradually squeezes high-level semantic and low-level geometric cues of the hypercorrelation into precise segmentation masks in coarse-to-fine manner. The significant performance improvements on standard few-shot segmentation benchmarks of PASCAL-5i, COCO-20i, and FSS-1000 verify the efficacy of the proposed method.