 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelational Embedding for Few-Shot Classification
Paper and Code
Aug 22, 2021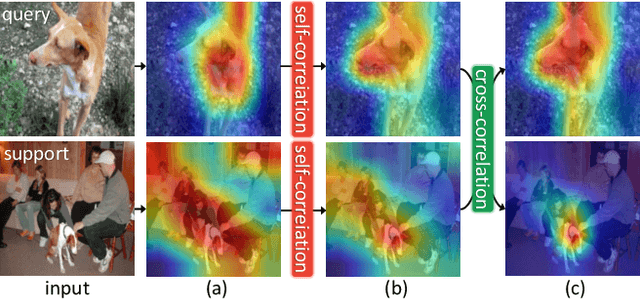
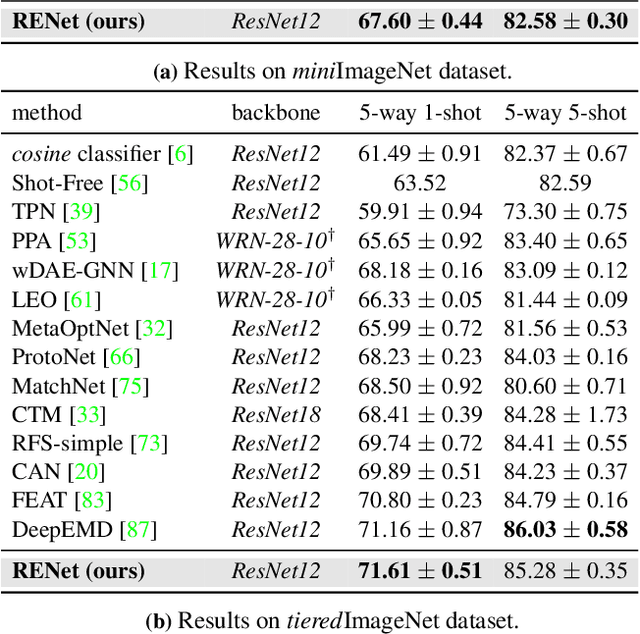


We propose to address the problem of few-shot classification by meta-learning "what to observe" and "where to attend" in a relational perspective. Our method leverages relational patterns within and between images via self-correlational representation (SCR) and cross-correlational attention (CCA). Within each image, the SCR module transforms a base feature map into a self-correlation tensor and learns to extract structural patterns from the tensor. Between the images, the CCA module computes cross-correlation between two image representations and learns to produce co-attention between them. Our Relational Embedding Network (RENet) combines the two relational modules to learn relational embedding in an end-to-end manner. In experimental evaluation, it achieves consistent improvements over state-of-the-art methods on four widely used few-shot classification benchmarks of miniImageNet, tieredImageNet, CUB-200-2011, and CIFAR-FS.