 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextVLA: Vision-Language-Action Model with Amortized Multi-Frame Context
Oct 05, 2025Leveraging temporal context is crucial for success in partially observable robotic tasks. However, prior work in behavior cloning has demonstrated inconsistent performance gains when using multi-frame observations. In this paper, we introduce ContextVLA, a policy model that robustly improves robotic task performance by effectively leveraging multi-frame observations. Our approach is motivated by the key observation that Vision-Language-Action models (VLA), i.e., policy models built upon a Vision-Language Model (VLM), more effectively utilize multi-frame observations for action generation. This suggests that VLMs' inherent temporal understanding capability enables them to extract more meaningful context from multi-frame observations. However, the high dimensionality of video inputs introduces significant computational overhead, making VLA training and inference inefficient. To address this, ContextVLA compresses past observations into a single context token, allowing the policy to efficiently leverage temporal context for action generation. Our experiments show that ContextVLA consistently improves over single-frame VLAs and achieves the benefits of full multi-frame training but with reduced training and inference times.
Lightweight Structure-Aware Attention for Visual Understanding
Nov 29, 2022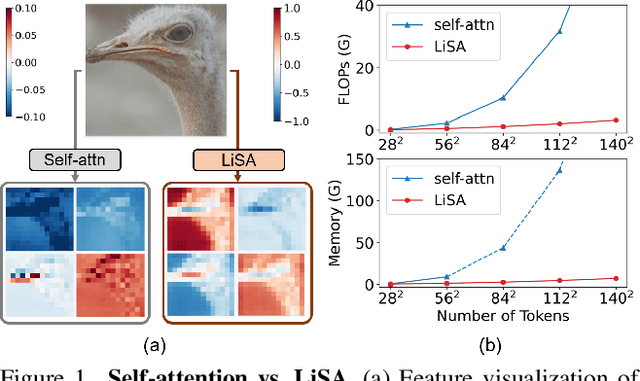
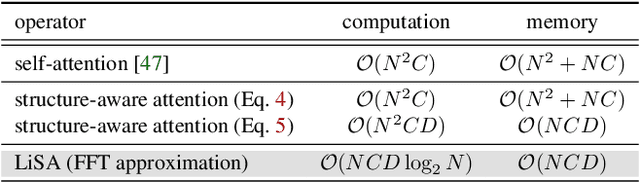
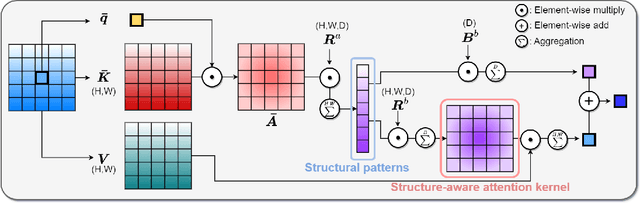
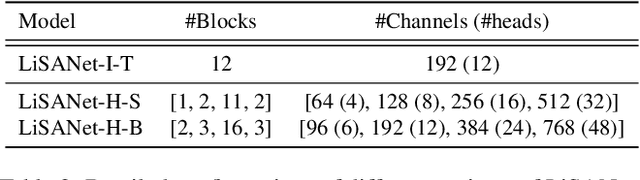
Vision Transformers (ViTs) have become a dominant paradigm for visual representation learning with self-attention operators. Although these operators provide flexibility to the model with their adjustable attention kernels, they suffer from inherent limitations: (1) the attention kernel is not discriminative enough, resulting in high redundancy of the ViT layers, and (2) the complexity in computation and memory is quadratic in the sequence length. In this paper, we propose a novel attention operator, called lightweight structure-aware attention (LiSA), which has a better representation power with log-linear complexity. Our operator learns structural patterns by using a set of relative position embeddings (RPEs). To achieve log-linear complexity, the RPEs are approximated with fast Fourier transforms. Our experiments and ablation studies demonstrate that ViTs based on the proposed operator outperform self-attention and other existing operators, achieving state-of-the-art results on ImageNet, and competitive results on other visual understanding benchmarks such as COCO and Something-Something-V2. The source code of our approach will be released online.
Relational Self-Attention: What's Missing in Attention for Video Understanding
Nov 02, 2021

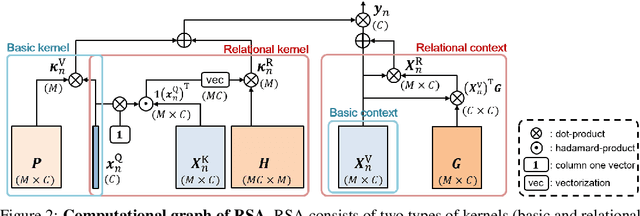

Convolution has been arguably the most important feature transform for modern neural networks, leading to the advance of deep learning. Recent emergence of Transformer networks, which replace convolution layers with self-attention blocks, has revealed the limitation of stationary convolution kernels and opened the door to the era of dynamic feature transforms. The existing dynamic transforms, including self-attention, however, are all limited for video understanding where correspondence relations in space and time, i.e., motion information, are crucial for effective representation. In this work, we introduce a relational feature transform, dubbed the relational self-attention (RSA), that leverages rich structures of spatio-temporal relations in videos by dynamically generating relational kernels and aggregating relational contexts. Our experiments and ablation studies show that the RSA network substantially outperforms convolution and self-attention counterparts, achieving the state of the art on the standard motion-centric benchmarks for video action recognition, such as Something-Something-V1 & V2, Diving48, and FineGym.
Relational Embedding for Few-Shot Classification
Aug 22, 2021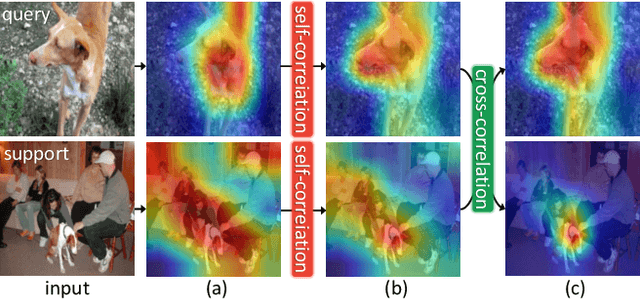
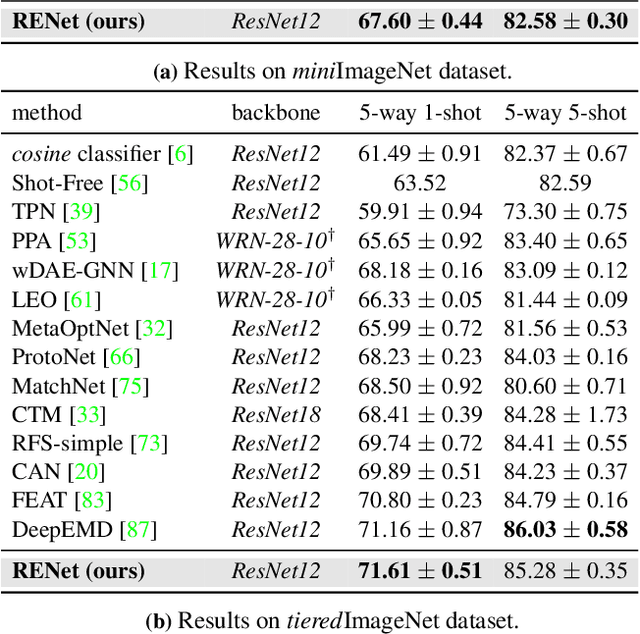


We propose to address the problem of few-shot classification by meta-learning "what to observe" and "where to attend" in a relational perspective. Our method leverages relational patterns within and between images via self-correlational representation (SCR) and cross-correlational attention (CCA). Within each image, the SCR module transforms a base feature map into a self-correlation tensor and learns to extract structural patterns from the tensor. Between the images, the CCA module computes cross-correlation between two image representations and learns to produce co-attention between them. Our Relational Embedding Network (RENet) combines the two relational modules to learn relational embedding in an end-to-end manner. In experimental evaluation, it achieves consistent improvements over state-of-the-art methods on four widely used few-shot classification benchmarks of miniImageNet, tieredImageNet, CUB-200-2011, and CIFAR-FS.
Learning Self-Similarity in Space and Time as Generalized Motion for Action Recognition
Feb 14, 2021



Spatio-temporal convolution often fails to learn motion dynamics in videos and thus an effective motion representation is required for video understanding in the wild. In this paper, we propose a rich and robust motion representation based on spatio-temporal self-similarity (STSS). Given a sequence of frames, STSS represents each local region as similarities to its neighbors in space and time. By converting appearance features into relational values, it enables the learner to better recognize structural patterns in space and time. We leverage the whole volume of STSS and let our model learn to extract an effective motion representation from it. The proposed neural block, dubbed SELFY, can be easily inserted into neural architectures and trained end-to-end without additional supervision. With a sufficient volume of the neighborhood in space and time, it effectively captures long-term interaction and fast motion in the video, leading to robust action recognition. Our experimental analysis demonstrates its superiority over previous methods for motion modeling as well as its complementarity to spatio-temporal features from direct convolution. On the standard action recognition benchmarks, Something-Something-V1 & V2, Diving-48, and FineGym, the proposed method achieves the state-of-the-art results.
MotionSqueeze: Neural Motion Feature Learning for Video Understanding
Jul 20, 2020

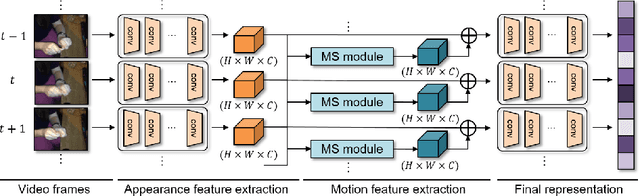
Motion plays a crucial role in understanding videos and most state-of-the-art neural models for video classification incorporate motion information typically using optical flows extracted by a separate off-the-shelf method. As the frame-by-frame optical flows require heavy computation, incorporating motion information has remained a major computational bottleneck for video understanding. In this work, we replace external and heavy computation of optical flows with internal and light-weight learning of motion features. We propose a trainable neural module, dubbed MotionSqueeze, for effective motion feature extraction. Inserted in the middle of any neural network, it learns to establish correspondences across frames and convert them into motion features, which are readily fed to the next downstream layer for better prediction. We demonstrate that the proposed method provides a significant gain on four standard benchmarks for action recognition with only a small amount of additional cost, outperforming the state of the art on Something-Something-V1&V2 datasets.
IntegralAction: Pose-driven Feature Integration for Robust Human Action Recognition in Videos
Jul 13, 2020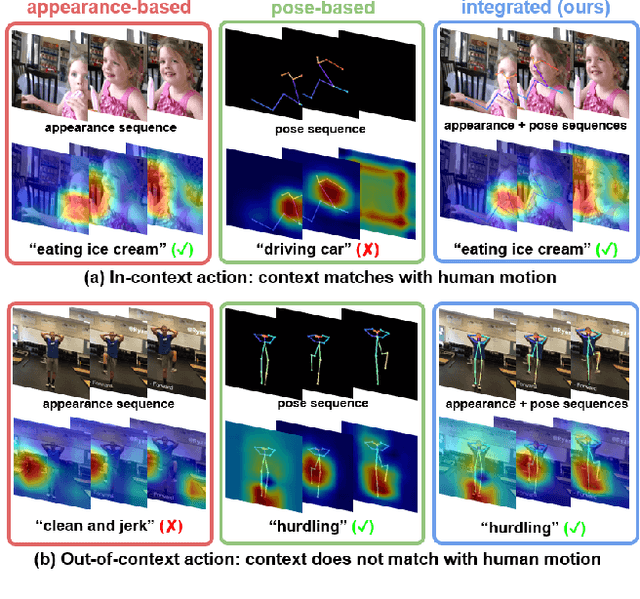
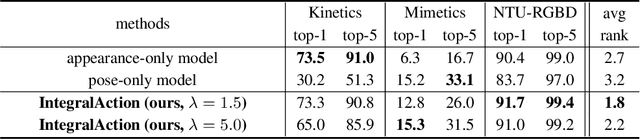
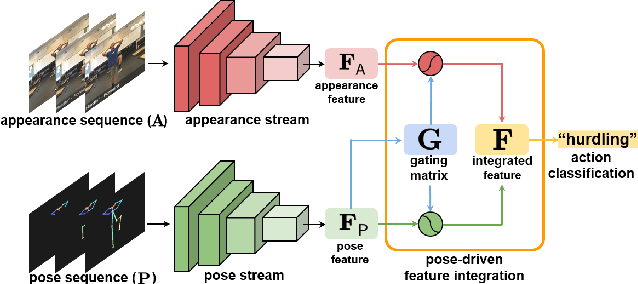

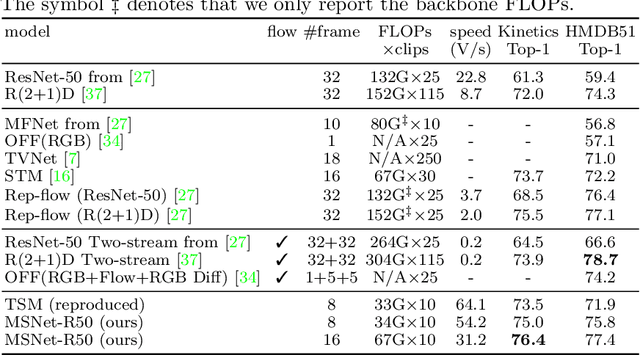
Most current action recognition methods heavily rely on appearance information by taking an RGB sequence of entire image regions as input. While being effective in exploiting contextual information around humans, e.g., human appearance and scene category, they are easily fooled by out-of-context action videos where the contexts do not exactly match with target actions. In contrast, pose-based methods, which takes a sequence of human skeletons only as input, suffer from inaccurate pose estimation or ambiguity of human pose per se. Integrating these two approaches has turned out to be non-trivial; training a model with both appearance and pose ends up with a strong bias towards appearance and does not generalize well to unseen videos. To address this problem, we propose to learn pose-driven feature integration that dynamically combines appearance and pose streams by observing pose features on the fly. The main idea is to let the pose stream decide how much and which appearance information is used in integration based on whether the given pose information is reliable or not. We show that the proposed IntegralAction achieves highly robust performance across in-context and out-of-context action video datasets.