 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightweight Structure-Aware Attention for Visual Understanding
Nov 29, 2022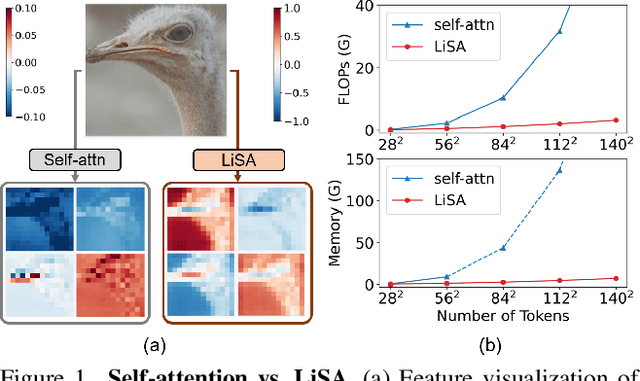
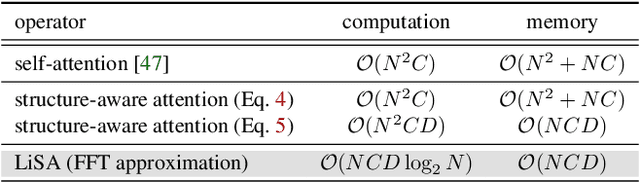
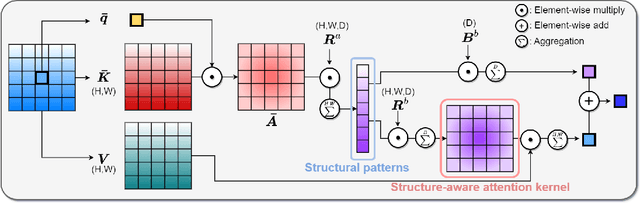
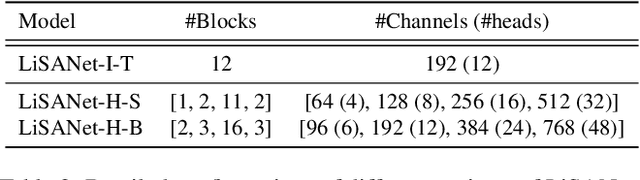
Vision Transformers (ViTs) have become a dominant paradigm for visual representation learning with self-attention operators. Although these operators provide flexibility to the model with their adjustable attention kernels, they suffer from inherent limitations: (1) the attention kernel is not discriminative enough, resulting in high redundancy of the ViT layers, and (2) the complexity in computation and memory is quadratic in the sequence length. In this paper, we propose a novel attention operator, called lightweight structure-aware attention (LiSA), which has a better representation power with log-linear complexity. Our operator learns structural patterns by using a set of relative position embeddings (RPEs). To achieve log-linear complexity, the RPEs are approximated with fast Fourier transforms. Our experiments and ablation studies demonstrate that ViTs based on the proposed operator outperform self-attention and other existing operators, achieving state-of-the-art results on ImageNet, and competitive results on other visual understanding benchmarks such as COCO and Something-Something-V2. The source code of our approach will be released online.
iLGaCo: Incremental Learning of Gait Covariate Factors
Aug 31, 2020
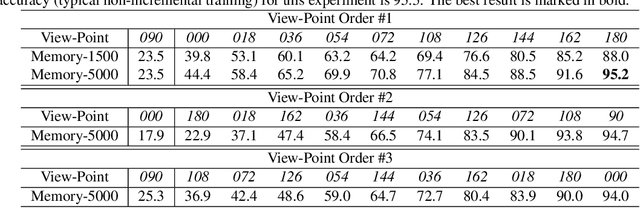
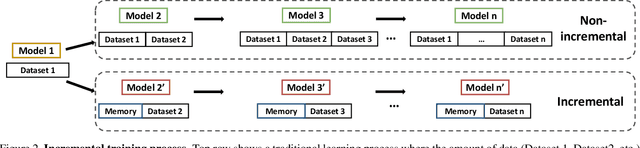
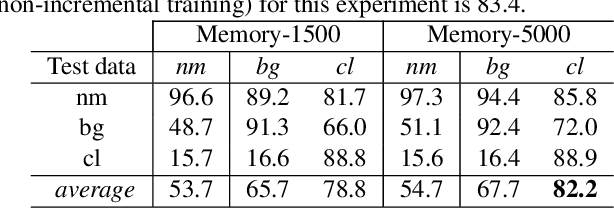
Gait is a popular biometric pattern used for identifying people based on their way of walking. Traditionally, gait recognition approaches based on deep learning are trained using the whole training dataset. In fact, if new data (classes, view-points, walking conditions, etc.) need to be included, it is necessary to re-train again the model with old and new data samples. In this paper, we propose iLGaCo, the first incremental learning approach of covariate factors for gait recognition, where the deep model can be updated with new information without re-training it from scratch by using the whole dataset. Instead, our approach performs a shorter training process with the new data and a small subset of previous samples. This way, our model learns new information while retaining previous knowledge. We evaluate iLGaCo on CASIA-B dataset in two incremental ways: adding new view-points and adding new walking conditions. In both cases, our results are close to the classical `training-from-scratch' approach, obtaining a marginal drop in accuracy ranging from 0.2% to 1.2%, what shows the efficacy of our approach. In addition, the comparison of iLGaCo with other incremental learning methods, such as LwF and iCarl, shows a significant improvement in accuracy, between 6% and 15% depending on the experiment.