 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowception: Temporally Expansive Flow Matching for Video Generation
Dec 12, 2025We present Flowception, a novel non-autoregressive and variable-length video generation framework. Flowception learns a probability path that interleaves discrete frame insertions with continuous frame denoising. Compared to autoregressive methods, Flowception alleviates error accumulation/drift as the frame insertion mechanism during sampling serves as an efficient compression mechanism to handle long-term context. Compared to full-sequence flows, our method reduces FLOPs for training three-fold, while also being more amenable to local attention variants, and allowing to learn the length of videos jointly with their content. Quantitative experimental results show improved FVD and VBench metrics over autoregressive and full-sequence baselines, which is further validated with qualitative results. Finally, by learning to insert and denoise frames in a sequence, Flowception seamlessly integrates different tasks such as image-to-video generation and video interpolation.
Entropy Rectifying Guidance for Diffusion and Flow Models
Apr 18, 2025Guidance techniques are commonly used in diffusion and flow models to improve image quality and consistency for conditional generative tasks such as class-conditional and text-to-image generation. In particular, classifier-free guidance (CFG) -- the most widely adopted guidance technique -- contrasts conditional and unconditional predictions to improve the generated images. This results, however, in trade-offs across quality, diversity and consistency, improving some at the expense of others. While recent work has shown that it is possible to disentangle these factors to some extent, such methods come with an overhead of requiring an additional (weaker) model, or require more forward passes per sampling step. In this paper, we propose Entropy Rectifying Guidance (ERG), a simple and effective guidance mechanism based on inference-time changes in the attention mechanism of state-of-the-art diffusion transformer architectures, which allows for simultaneous improvements over image quality, diversity and prompt consistency. ERG is more general than CFG and similar guidance techniques, as it extends to unconditional sampling. ERG results in significant improvements in various generation tasks such as text-to-image, class-conditional and unconditional image generation. We also show that ERG can be seamlessly combined with other recent guidance methods such as CADS and APG, further boosting generation performance.
Boosting Latent Diffusion with Perceptual Objectives
Nov 06, 2024Latent diffusion models (LDMs) power state-of-the-art high-resolution generative image models. LDMs learn the data distribution in the latent space of an autoencoder (AE) and produce images by mapping the generated latents into RGB image space using the AE decoder. While this approach allows for efficient model training and sampling, it induces a disconnect between the training of the diffusion model and the decoder, resulting in a loss of detail in the generated images. To remediate this disconnect, we propose to leverage the internal features of the decoder to define a latent perceptual loss (LPL). This loss encourages the models to create sharper and more realistic images. Our loss can be seamlessly integrated with common autoencoders used in latent diffusion models, and can be applied to different generative modeling paradigms such as DDPM with epsilon and velocity prediction, as well as flow matching. Extensive experiments with models trained on three datasets at 256 and 512 resolution show improved quantitative -- with boosts between 6% and 20% in FID -- and qualitative results when using our perceptual loss.
On Improved Conditioning Mechanisms and Pre-training Strategies for Diffusion Models
Nov 05, 2024Large-scale training of latent diffusion models (LDMs) has enabled unprecedented quality in image generation. However, the key components of the best performing LDM training recipes are oftentimes not available to the research community, preventing apple-to-apple comparisons and hindering the validation of progress in the field. In this work, we perform an in-depth study of LDM training recipes focusing on the performance of models and their training efficiency. To ensure apple-to-apple comparisons, we re-implement five previously published models with their corresponding recipes. Through our study, we explore the effects of (i)~the mechanisms used to condition the generative model on semantic information (e.g., text prompt) and control metadata (e.g., crop size, random flip flag, etc.) on the model performance, and (ii)~the transfer of the representations learned on smaller and lower-resolution datasets to larger ones on the training efficiency and model performance. We then propose a novel conditioning mechanism that disentangles semantic and control metadata conditionings and sets a new state-of-the-art in class-conditional generation on the ImageNet-1k dataset -- with FID improvements of 7% on 256 and 8% on 512 resolutions -- as well as text-to-image generation on the CC12M dataset -- with FID improvements of 8% on 256 and 23% on 512 resolution.
Unlocking Pre-trained Image Backbones for Semantic Image Synthesis
Jan 08, 2024
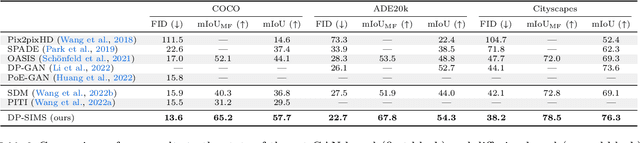
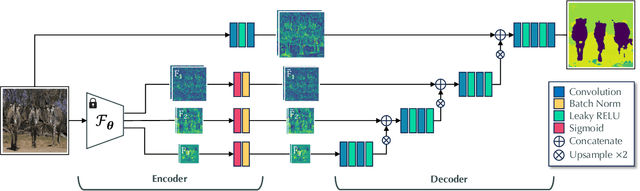
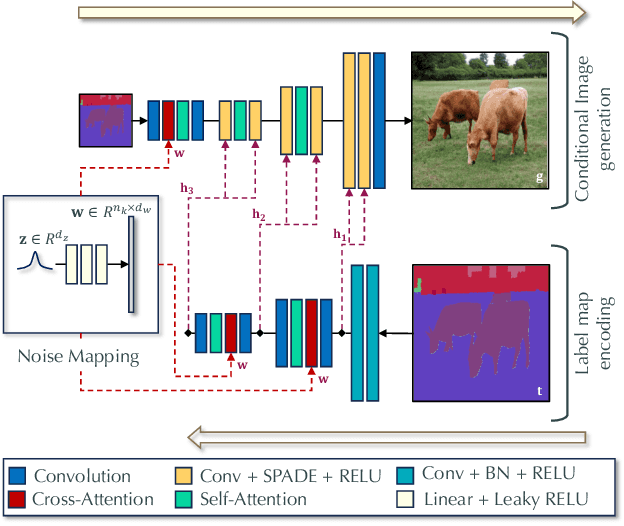
Semantic image synthesis, i.e., generating images from user-provided semantic label maps, is an important conditional image generation task as it allows to control both the content as well as the spatial layout of generated images. Although diffusion models have pushed the state of the art in generative image modeling, the iterative nature of their inference process makes them computationally demanding. Other approaches such as GANs are more efficient as they only need a single feed-forward pass for generation, but the image quality tends to suffer on large and diverse datasets. In this work, we propose a new class of GAN discriminators for semantic image synthesis that generates highly realistic images by exploiting feature backbone networks pre-trained for tasks such as image classification. We also introduce a new generator architecture with better context modeling and using cross-attention to inject noise into latent variables, leading to more diverse generated images. Our model, which we dub DP-SIMS, achieves state-of-the-art results in terms of image quality and consistency with the input label maps on ADE-20K, COCO-Stuff, and Cityscapes, surpassing recent diffusion models while requiring two orders of magnitude less compute for inference.
Overcoming Label Noise for Source-free Unsupervised Video Domain Adaptation
Nov 30, 2023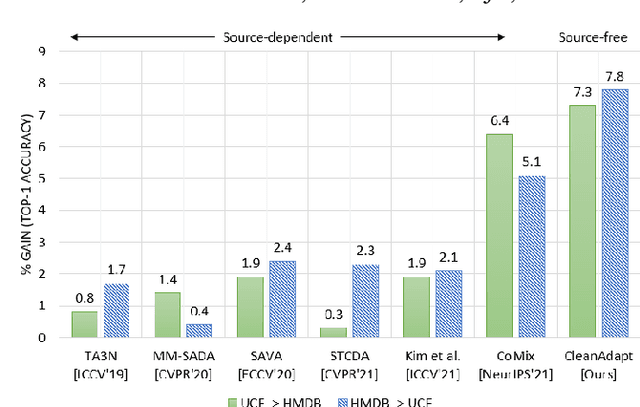
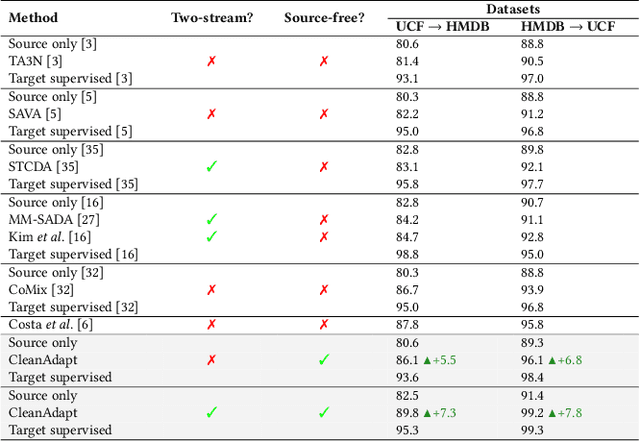
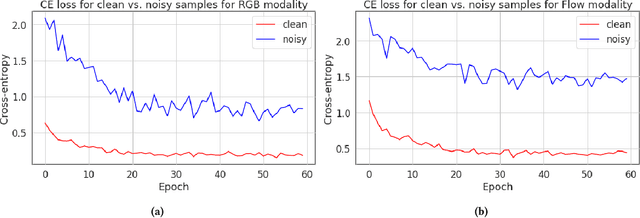
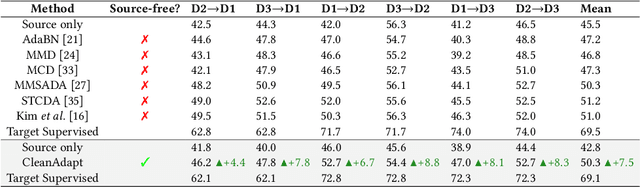
Despite the progress seen in classification methods, current approaches for handling videos with distribution shifts in source and target domains remain source-dependent as they require access to the source data during the adaptation stage. In this paper, we present a self-training based source-free video domain adaptation approach to address this challenge by bridging the gap between the source and the target domains. We use the source pre-trained model to generate pseudo-labels for the target domain samples, which are inevitably noisy. Thus, we treat the problem of source-free video domain adaptation as learning from noisy labels and argue that the samples with correct pseudo-labels can help us in adaptation. To this end, we leverage the cross-entropy loss as an indicator of the correctness of the pseudo-labels and use the resulting small-loss samples from the target domain for fine-tuning the model. We further enhance the adaptation performance by implementing a teacher-student framework, in which the teacher, which is updated gradually, produces reliable pseudo-labels. Meanwhile, the student undergoes fine-tuning on the target domain videos using these generated pseudo-labels to improve its performance. Extensive experimental evaluations show that our methods, termed as CleanAdapt, CleanAdapt + TS, achieve state-of-the-art results, outperforming the existing approaches on various open datasets. Our source code is publicly available at https://avijit9.github.io/CleanAdapt.
On the Effectiveness of LayerNorm Tuning for Continual Learning in Vision Transformers
Aug 18, 2023



State-of-the-art rehearsal-free continual learning methods exploit the peculiarities of Vision Transformers to learn task-specific prompts, drastically reducing catastrophic forgetting. However, there is a tradeoff between the number of learned parameters and the performance, making such models computationally expensive. In this work, we aim to reduce this cost while maintaining competitive performance. We achieve this by revisiting and extending a simple transfer learning idea: learning task-specific normalization layers. Specifically, we tune the scale and bias parameters of LayerNorm for each continual learning task, selecting them at inference time based on the similarity between task-specific keys and the output of the pre-trained model. To make the classifier robust to incorrect selection of parameters during inference, we introduce a two-stage training procedure, where we first optimize the task-specific parameters and then train the classifier with the same selection procedure of the inference time. Experiments on ImageNet-R and CIFAR-100 show that our method achieves results that are either superior or on par with {the state of the art} while being computationally cheaper.
Guided Distillation for Semi-Supervised Instance Segmentation
Aug 03, 2023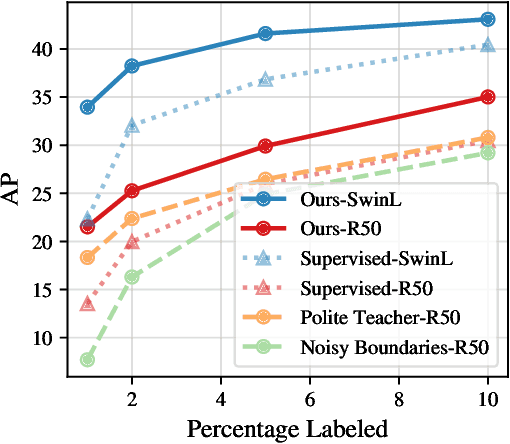
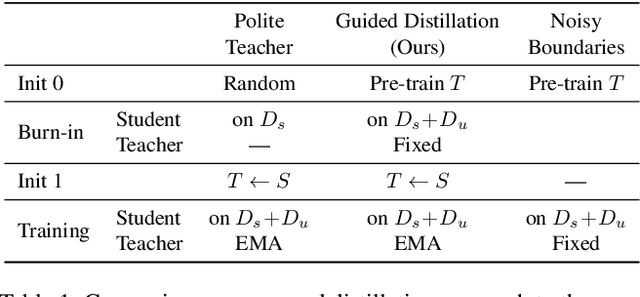


Although instance segmentation methods have improved considerably, the dominant paradigm is to rely on fully-annotated training images, which are tedious to obtain. To alleviate this reliance, and boost results, semi-supervised approaches leverage unlabeled data as an additional training signal that limits overfitting to the labeled samples. In this context, we present novel design choices to significantly improve teacher-student distillation models. In particular, we (i) improve the distillation approach by introducing a novel "guided burn-in" stage, and (ii) evaluate different instance segmentation architectures, as well as backbone networks and pre-training strategies. Contrary to previous work which uses only supervised data for the burn-in period of the student model, we also use guidance of the teacher model to exploit unlabeled data in the burn-in period. Our improved distillation approach leads to substantial improvements over previous state-of-the-art results. For example, on the Cityscapes dataset we improve mask-AP from 23.7 to 33.9 when using labels for 10\% of images, and on the COCO dataset we improve mask-AP from 18.3 to 34.1 when using labels for only 1\% of the training data.
Multi-Domain Learning with Modulation Adapters
Jul 17, 2023

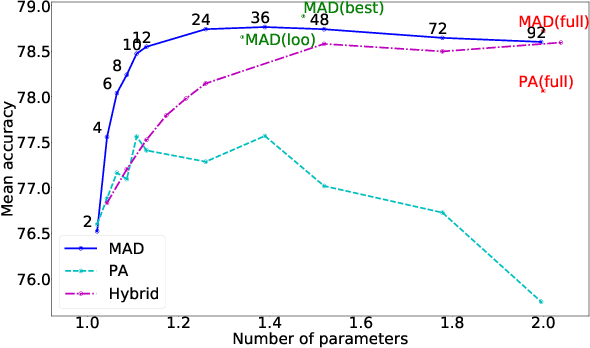

Deep convolutional networks are ubiquitous in computer vision, due to their excellent performance across different tasks for various domains. Models are, however, often trained in isolation for each task, failing to exploit relatedness between tasks and domains to learn more compact models that generalise better in low-data regimes. Multi-domain learning aims to handle related tasks, such as image classification across multiple domains, simultaneously. Previous work on this problem explored the use of a pre-trained and fixed domain-agnostic base network, in combination with smaller learnable domain-specific adaptation modules. In this paper, we introduce Modulation Adapters, which update the convolutional filter weights of the model in a multiplicative manner for each task. Parameterising these adaptation weights in a factored manner allows us to scale the number of per-task parameters in a flexible manner, and to strike different parameter-accuracy trade-offs. We evaluate our approach on the Visual Decathlon challenge, composed of ten image classification tasks across different domains, and on the ImageNet-to-Sketch benchmark, which consists of six image classification tasks. Our approach yields excellent results, with accuracies that are comparable to or better than those of existing state-of-the-art approaches.
Semi-supervised learning made simple with self-supervised clustering
Jun 13, 2023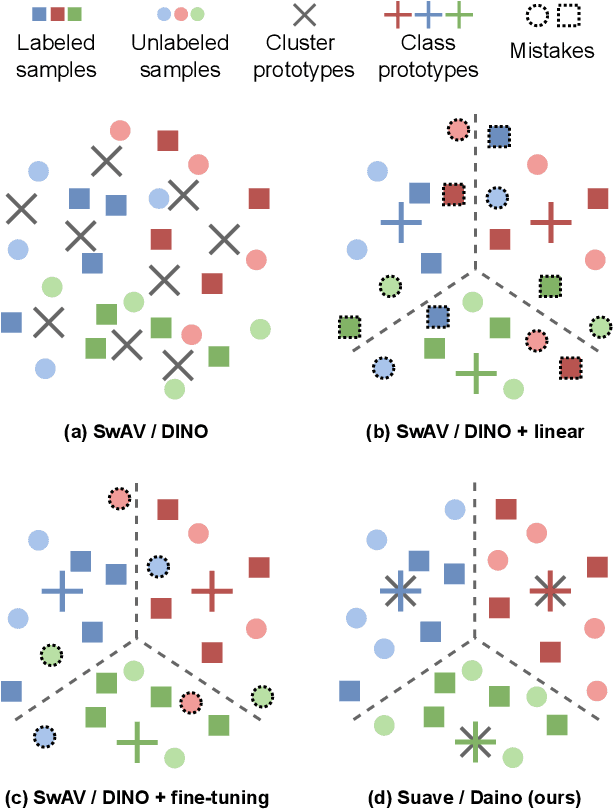
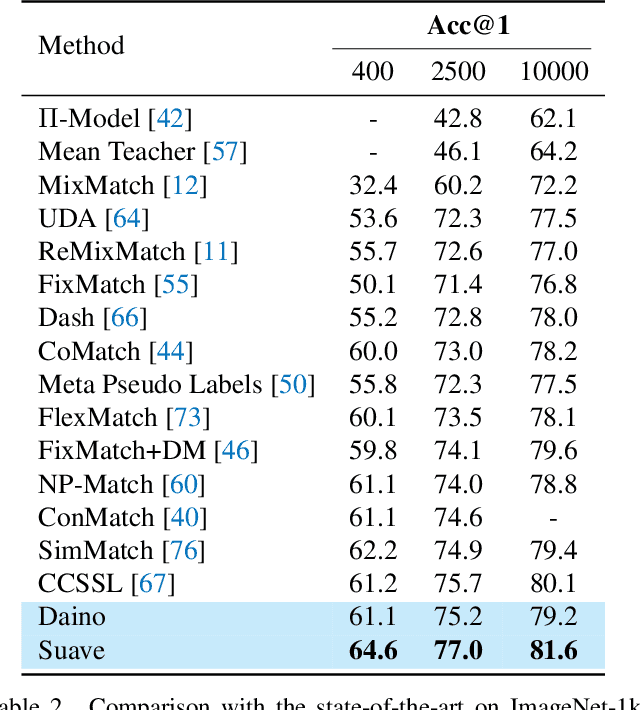
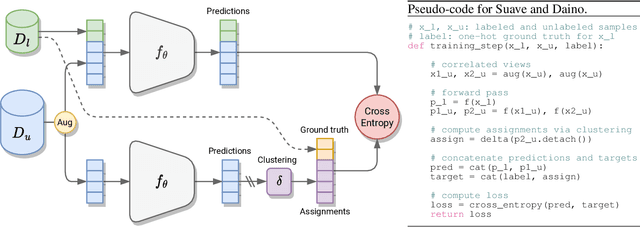
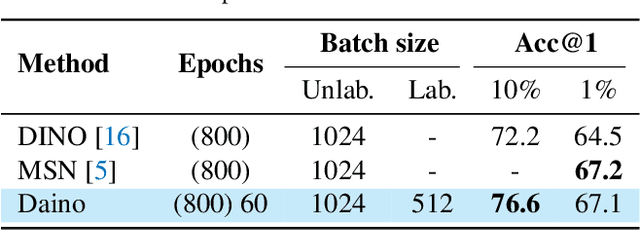
Self-supervised learning models have been shown to learn rich visual representations without requiring human annotations. However, in many real-world scenarios, labels are partially available, motivating a recent line of work on semi-supervised methods inspired by self-supervised principles. In this paper, we propose a conceptually simple yet empirically powerful approach to turn clustering-based self-supervised methods such as SwAV or DINO into semi-supervised learners. More precisely, we introduce a multi-task framework merging a supervised objective using ground-truth labels and a self-supervised objective relying on clustering assignments with a single cross-entropy loss. This approach may be interpreted as imposing the cluster centroids to be class prototypes. Despite its simplicity, we provide empirical evidence that our approach is highly effective and achieves state-of-the-art performance on CIFAR100 and ImageNet.
* CVPR 2023 - Code available at https://github.com/pietroastolfi/suave-daino