 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Scaling Laws of Synthetic Data with Deliberate Practice
Feb 21, 2025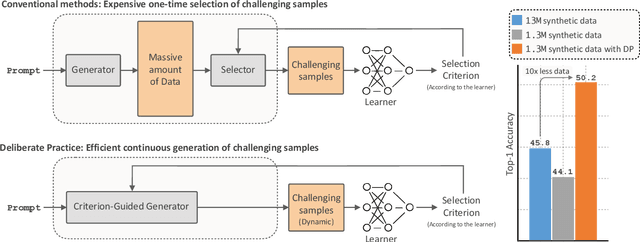
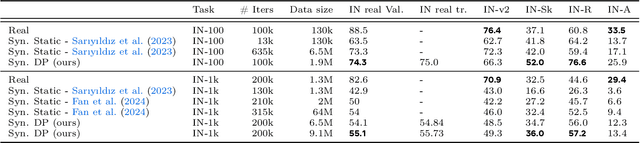
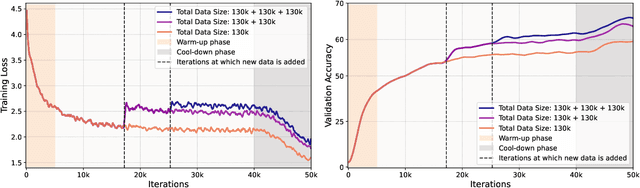

Inspired by the principle of deliberate practice in human learning, we propose Deliberate Practice for Synthetic Data Generation (DP), a novel framework that improves sample efficiency through dynamic synthetic data generation. Prior work has shown that scaling synthetic data is inherently challenging, as naively adding new data leads to diminishing returns. To address this, pruning has been identified as a key mechanism for improving scaling, enabling models to focus on the most informative synthetic samples. Rather than generating a large dataset and pruning it afterward, DP efficiently approximates the direct generation of informative samples. We theoretically show how training on challenging, informative examples improves scaling laws and empirically validate that DP achieves better scaling performance with significantly fewer training samples and iterations. On ImageNet-100, DP generates 3.4x fewer samples and requires six times fewer iterations, while on ImageNet-1k, it generates 8x fewer samples with a 30 percent reduction in iterations, all while achieving superior performance compared to prior work.
Object-centric Binding in Contrastive Language-Image Pretraining
Feb 19, 2025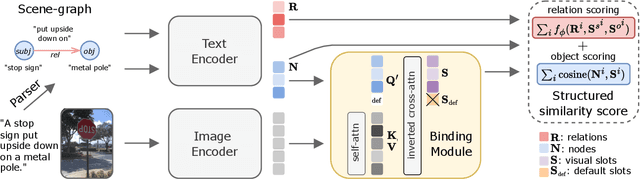
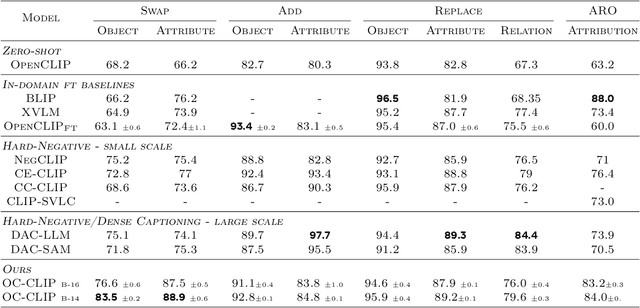
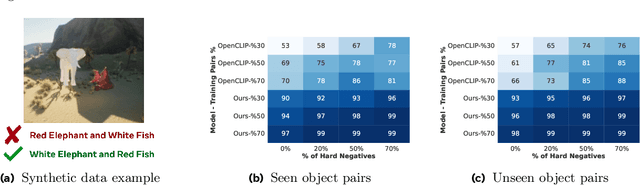
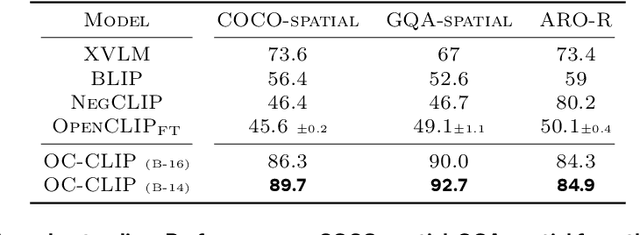
Recent advances in vision language models (VLM) have been driven by contrastive models such as CLIP, which learn to associate visual information with their corresponding text descriptions. However, these models have limitations in understanding complex compositional scenes involving multiple objects and their spatial relationships. To address these challenges, we propose a novel approach that diverges from commonly used strategies, which rely on the design of hard-negative augmentations. Instead, our work focuses on integrating inductive biases into pre-trained CLIP-like models to improve their compositional understanding without using any additional hard-negatives. To that end, we introduce a binding module that connects a scene graph, derived from a text description, with a slot-structured image representation, facilitating a structured similarity assessment between the two modalities. We also leverage relationships as text-conditioned visual constraints, thereby capturing the intricate interactions between objects and their contextual relationships more effectively. Our resulting model not only enhances the performance of CLIP-based models in multi-object compositional understanding but also paves the way towards more accurate and sample-efficient image-text matching of complex scenes.
EvalGIM: A Library for Evaluating Generative Image Models
Dec 18, 2024



As the use of text-to-image generative models increases, so does the adoption of automatic benchmarking methods used in their evaluation. However, while metrics and datasets abound, there are few unified benchmarking libraries that provide a framework for performing evaluations across many datasets and metrics. Furthermore, the rapid introduction of increasingly robust benchmarking methods requires that evaluation libraries remain flexible to new datasets and metrics. Finally, there remains a gap in synthesizing evaluations in order to deliver actionable takeaways about model performance. To enable unified, flexible, and actionable evaluations, we introduce EvalGIM (pronounced ''EvalGym''), a library for evaluating generative image models. EvalGIM contains broad support for datasets and metrics used to measure quality, diversity, and consistency of text-to-image generative models. In addition, EvalGIM is designed with flexibility for user customization as a top priority and contains a structure that allows plug-and-play additions of new datasets and metrics. To enable actionable evaluation insights, we introduce ''Evaluation Exercises'' that highlight takeaways for specific evaluation questions. The Evaluation Exercises contain easy-to-use and reproducible implementations of two state-of-the-art evaluation methods of text-to-image generative models: consistency-diversity-realism Pareto Fronts and disaggregated measurements of performance disparities across groups. EvalGIM also contains Evaluation Exercises that introduce two new analysis methods for text-to-image generative models: robustness analyses of model rankings and balanced evaluations across different prompt styles. We encourage text-to-image model exploration with EvalGIM and invite contributions at https://github.com/facebookresearch/EvalGIM/.
Boosting Latent Diffusion with Perceptual Objectives
Nov 06, 2024Latent diffusion models (LDMs) power state-of-the-art high-resolution generative image models. LDMs learn the data distribution in the latent space of an autoencoder (AE) and produce images by mapping the generated latents into RGB image space using the AE decoder. While this approach allows for efficient model training and sampling, it induces a disconnect between the training of the diffusion model and the decoder, resulting in a loss of detail in the generated images. To remediate this disconnect, we propose to leverage the internal features of the decoder to define a latent perceptual loss (LPL). This loss encourages the models to create sharper and more realistic images. Our loss can be seamlessly integrated with common autoencoders used in latent diffusion models, and can be applied to different generative modeling paradigms such as DDPM with epsilon and velocity prediction, as well as flow matching. Extensive experiments with models trained on three datasets at 256 and 512 resolution show improved quantitative -- with boosts between 6% and 20% in FID -- and qualitative results when using our perceptual loss.
On Improved Conditioning Mechanisms and Pre-training Strategies for Diffusion Models
Nov 05, 2024Large-scale training of latent diffusion models (LDMs) has enabled unprecedented quality in image generation. However, the key components of the best performing LDM training recipes are oftentimes not available to the research community, preventing apple-to-apple comparisons and hindering the validation of progress in the field. In this work, we perform an in-depth study of LDM training recipes focusing on the performance of models and their training efficiency. To ensure apple-to-apple comparisons, we re-implement five previously published models with their corresponding recipes. Through our study, we explore the effects of (i)~the mechanisms used to condition the generative model on semantic information (e.g., text prompt) and control metadata (e.g., crop size, random flip flag, etc.) on the model performance, and (ii)~the transfer of the representations learned on smaller and lower-resolution datasets to larger ones on the training efficiency and model performance. We then propose a novel conditioning mechanism that disentangles semantic and control metadata conditionings and sets a new state-of-the-art in class-conditional generation on the ImageNet-1k dataset -- with FID improvements of 7% on 256 and 8% on 512 resolutions -- as well as text-to-image generation on the CC12M dataset -- with FID improvements of 8% on 256 and 23% on 512 resolution.
$\mathbb{X}$-Sample Contrastive Loss: Improving Contrastive Learning with Sample Similarity Graphs
Jul 25, 2024



Learning good representations involves capturing the diverse ways in which data samples relate. Contrastive loss - an objective matching related samples - underlies methods from self-supervised to multimodal learning. Contrastive losses, however, can be viewed more broadly as modifying a similarity graph to indicate how samples should relate in the embedding space. This view reveals a shortcoming in contrastive learning: the similarity graph is binary, as only one sample is the related positive sample. Crucially, similarities \textit{across} samples are ignored. Based on this observation, we revise the standard contrastive loss to explicitly encode how a sample relates to others. We experiment with this new objective, called $\mathbb{X}$-Sample Contrastive, to train vision models based on similarities in class or text caption descriptions. Our study spans three scales: ImageNet-1k with 1 million, CC3M with 3 million, and CC12M with 12 million samples. The representations learned via our objective outperform both contrastive self-supervised and vision-language models trained on the same data across a range of tasks. When training on CC12M, we outperform CLIP by $0.6\%$ on both ImageNet and ImageNet Real. Our objective appears to work particularly well in lower-data regimes, with gains over CLIP of $16.8\%$ on ImageNet and $18.1\%$ on ImageNet Real when training with CC3M. Finally, our objective seems to encourage the model to learn representations that separate objects from their attributes and backgrounds, with gains of $3.3$-$5.6$\% over CLIP on ImageNet9. We hope the proposed solution takes a small step towards developing richer learning objectives for understanding sample relations in foundation models.
Consistency-diversity-realism Pareto fronts of conditional image generative models
Jun 14, 2024



Building world models that accurately and comprehensively represent the real world is the utmost aspiration for conditional image generative models as it would enable their use as world simulators. For these models to be successful world models, they should not only excel at image quality and prompt-image consistency but also ensure high representation diversity. However, current research in generative models mostly focuses on creative applications that are predominantly concerned with human preferences of image quality and aesthetics. We note that generative models have inference time mechanisms - or knobs - that allow the control of generation consistency, quality, and diversity. In this paper, we use state-of-the-art text-to-image and image-and-text-to-image models and their knobs to draw consistency-diversity-realism Pareto fronts that provide a holistic view on consistency-diversity-realism multi-objective. Our experiments suggest that realism and consistency can both be improved simultaneously; however there exists a clear tradeoff between realism/consistency and diversity. By looking at Pareto optimal points, we note that earlier models are better at representation diversity and worse in consistency/realism, and more recent models excel in consistency/realism while decreasing significantly the representation diversity. By computing Pareto fronts on a geodiverse dataset, we find that the first version of latent diffusion models tends to perform better than more recent models in all axes of evaluation, and there exist pronounced consistency-diversity-realism disparities between geographical regions. Overall, our analysis clearly shows that there is no best model and the choice of model should be determined by the downstream application. With this analysis, we invite the research community to consider Pareto fronts as an analytical tool to measure progress towards world models.
An Introduction to Vision-Language Modeling
May 27, 2024


Following the recent popularity of Large Language Models (LLMs), several attempts have been made to extend them to the visual domain. From having a visual assistant that could guide us through unfamiliar environments to generative models that produce images using only a high-level text description, the vision-language model (VLM) applications will significantly impact our relationship with technology. However, there are many challenges that need to be addressed to improve the reliability of those models. While language is discrete, vision evolves in a much higher dimensional space in which concepts cannot always be easily discretized. To better understand the mechanics behind mapping vision to language, we present this introduction to VLMs which we hope will help anyone who would like to enter the field. First, we introduce what VLMs are, how they work, and how to train them. Then, we present and discuss approaches to evaluate VLMs. Although this work primarily focuses on mapping images to language, we also discuss extending VLMs to videos.
Improving Text-to-Image Consistency via Automatic Prompt Optimization
Mar 26, 2024



Impressive advances in text-to-image (T2I) generative models have yielded a plethora of high performing models which are able to generate aesthetically appealing, photorealistic images. Despite the progress, these models still struggle to produce images that are consistent with the input prompt, oftentimes failing to capture object quantities, relations and attributes properly. Existing solutions to improve prompt-image consistency suffer from the following challenges: (1) they oftentimes require model fine-tuning, (2) they only focus on nearby prompt samples, and (3) they are affected by unfavorable trade-offs among image quality, representation diversity, and prompt-image consistency. In this paper, we address these challenges and introduce a T2I optimization-by-prompting framework, OPT2I, which leverages a large language model (LLM) to improve prompt-image consistency in T2I models. Our framework starts from a user prompt and iteratively generates revised prompts with the goal of maximizing a consistency score. Our extensive validation on two datasets, MSCOCO and PartiPrompts, shows that OPT2I can boost the initial consistency score by up to 24.9% in terms of DSG score while preserving the FID and increasing the recall between generated and real data. Our work paves the way toward building more reliable and robust T2I systems by harnessing the power of LLMs.
DP-RDM: Adapting Diffusion Models to Private Domains Without Fine-Tuning
Mar 21, 2024



Text-to-image diffusion models have been shown to suffer from sample-level memorization, possibly reproducing near-perfect replica of images that they are trained on, which may be undesirable. To remedy this issue, we develop the first differentially private (DP) retrieval-augmented generation algorithm that is capable of generating high-quality image samples while providing provable privacy guarantees. Specifically, we assume access to a text-to-image diffusion model trained on a small amount of public data, and design a DP retrieval mechanism to augment the text prompt with samples retrieved from a private retrieval dataset. Our \emph{differentially private retrieval-augmented diffusion model} (DP-RDM) requires no fine-tuning on the retrieval dataset to adapt to another domain, and can use state-of-the-art generative models to generate high-quality image samples while satisfying rigorous DP guarantees. For instance, when evaluated on MS-COCO, our DP-RDM can generate samples with a privacy budget of $\epsilon=10$, while providing a $3.5$ point improvement in FID compared to public-only retrieval for up to $10,000$ queries.