 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoT-ICL Lab: A Petri Dish for Studying Chain-of-Thought Learning from In-Context Demonstrations
Feb 21, 2025


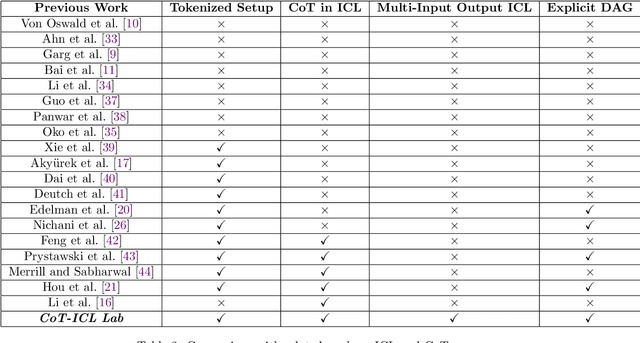
We introduce CoT-ICL Lab, a framework and methodology to generate synthetic tokenized datasets and systematically study chain-of-thought (CoT) in-context learning (ICL) in language models. CoT-ICL Lab allows fine grained control over the complexity of in-context examples by decoupling (1) the causal structure involved in chain token generation from (2) the underlying token processing functions. We train decoder-only transformers (up to 700M parameters) on these datasets and show that CoT accelerates the accuracy transition to higher values across model sizes. In particular, we find that model depth is crucial for leveraging CoT with limited in-context examples, while more examples help shallow models match deeper model performance. Additionally, limiting the diversity of token processing functions throughout training improves causal structure learning via ICL. We also interpret these transitions by analyzing transformer embeddings and attention maps. Overall, CoT-ICL Lab serves as a simple yet powerful testbed for theoretical and empirical insights into ICL and CoT in language models.
Efficient AI in Practice: Training and Deployment of Efficient LLMs for Industry Applications
Feb 20, 2025Large language models (LLMs) have demonstrated remarkable performance across a wide range of industrial applications, from search and recommendations to generative tasks. Although scaling laws indicate that larger models generally yield better generalization and performance, their substantial computational requirements often render them impractical for many real-world scenarios at scale. In this paper, we present methods and insights for training small language models (SLMs) that deliver high performance and efficiency in deployment. We focus on two key techniques: (1) knowledge distillation and (2) model compression via quantization and pruning. These approaches enable SLMs to retain much of the quality of their larger counterparts while significantly reducing training, serving costs, and latency. We detail the impact of these techniques on a variety of use cases at a large professional social network platform and share deployment lessons - including hardware optimization strategies that enhance speed and throughput for both predictive and reasoning-based applications.
360Brew: A Decoder-only Foundation Model for Personalized Ranking and Recommendation
Jan 27, 2025



Ranking and recommendation systems are the foundation for numerous online experiences, ranging from search results to personalized content delivery. These systems have evolved into complex, multilayered architectures that leverage vast datasets and often incorporate thousands of predictive models. The maintenance and enhancement of these models is a labor intensive process that requires extensive feature engineering. This approach not only exacerbates technical debt but also hampers innovation in extending these systems to emerging problem domains. In this report, we present our research to address these challenges by utilizing a large foundation model with a textual interface for ranking and recommendation tasks. We illustrate several key advantages of our approach: (1) a single model can manage multiple predictive tasks involved in ranking and recommendation, (2) decoder models with textual interface due to their comprehension of reasoning capabilities, can generalize to new recommendation surfaces and out-of-domain problems, and (3) by employing natural language interfaces for task definitions and verbalizing member behaviors and their social connections, we eliminate the need for feature engineering and the maintenance of complex directed acyclic graphs of model dependencies. We introduce our research pre-production model, 360Brew V1.0, a 150B parameter, decoder-only model that has been trained and fine-tuned on LinkedIn's data and tasks. This model is capable of solving over 30 predictive tasks across various segments of the LinkedIn platform, achieving performance levels comparable to or exceeding those of current production systems based on offline metrics, without task-specific fine-tuning. Notably, each of these tasks is conventionally addressed by dedicated models that have been developed and maintained over multiple years by teams of a similar or larger size than our own.
Lost-in-Distance: Impact of Contextual Proximity on LLM Performance in Graph Tasks
Oct 02, 2024



Despite significant advancements, Large Language Models (LLMs) exhibit blind spots that impair their ability to retrieve and process relevant contextual data effectively. We demonstrate that LLM performance in graph tasks with complexities beyond the "needle-in-a-haystack" scenario-where solving the problem requires cross-referencing and reasoning across multiple subproblems jointly-is influenced by the proximity of relevant information within the context, a phenomenon we term "lost-in-distance". We examine two fundamental graph tasks: identifying common connections between two nodes and assessing similarity among three nodes, and show that the model's performance in these tasks significantly depends on the relative positioning of common edges. We evaluate three publicly available LLMs-Llama-3-8B, Llama-3-70B, and GPT-4-using various graph encoding techniques that represent graph structures for LLM input. We propose a formulation for the lost-in-distance phenomenon and demonstrate that lost-in-distance and lost-in-the middle phenomenas occur independently. Results indicate that model accuracy can decline by up to 6x as the distance between node connections increases, independent of graph encoding and model size.
DP-RDM: Adapting Diffusion Models to Private Domains Without Fine-Tuning
Mar 21, 2024



Text-to-image diffusion models have been shown to suffer from sample-level memorization, possibly reproducing near-perfect replica of images that they are trained on, which may be undesirable. To remedy this issue, we develop the first differentially private (DP) retrieval-augmented generation algorithm that is capable of generating high-quality image samples while providing provable privacy guarantees. Specifically, we assume access to a text-to-image diffusion model trained on a small amount of public data, and design a DP retrieval mechanism to augment the text prompt with samples retrieved from a private retrieval dataset. Our \emph{differentially private retrieval-augmented diffusion model} (DP-RDM) requires no fine-tuning on the retrieval dataset to adapt to another domain, and can use state-of-the-art generative models to generate high-quality image samples while satisfying rigorous DP guarantees. For instance, when evaluated on MS-COCO, our DP-RDM can generate samples with a privacy budget of $\epsilon=10$, while providing a $3.5$ point improvement in FID compared to public-only retrieval for up to $10,000$ queries.
Differentially Private Representation Learning via Image Captioning
Mar 04, 2024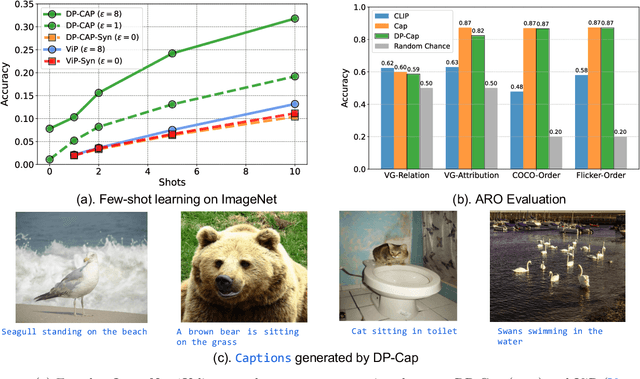
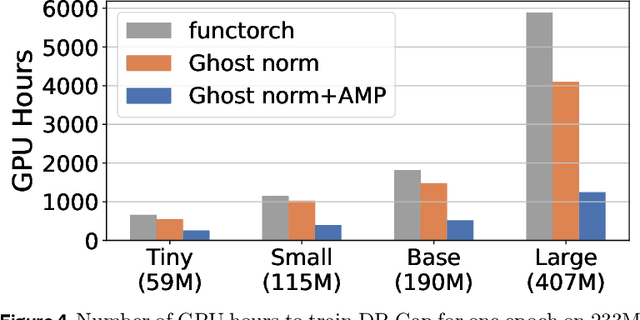
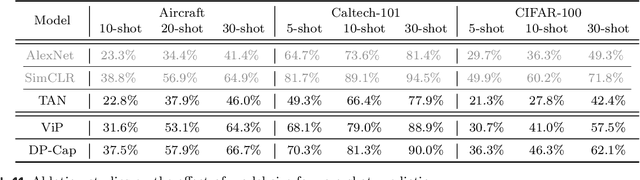
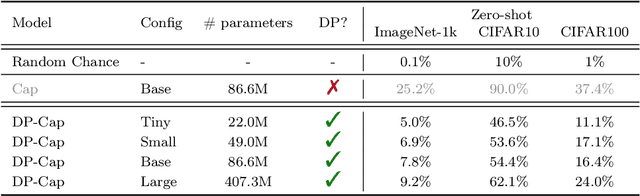
Differentially private (DP) machine learning is considered the gold-standard solution for training a model from sensitive data while still preserving privacy. However, a major barrier to achieving this ideal is its sub-optimal privacy-accuracy trade-off, which is particularly visible in DP representation learning. Specifically, it has been shown that under modest privacy budgets, most models learn representations that are not significantly better than hand-crafted features. In this work, we show that effective DP representation learning can be done via image captioning and scaling up to internet-scale multimodal datasets. Through a series of engineering tricks, we successfully train a DP image captioner (DP-Cap) on a 233M subset of LAION-2B from scratch using a reasonable amount of computation, and obtaining unprecedented high-quality image features that can be used in a variety of downstream vision and vision-language tasks. For example, under a privacy budget of $\varepsilon=8$, a linear classifier trained on top of learned DP-Cap features attains 65.8% accuracy on ImageNet-1K, considerably improving the previous SOTA of 56.5%. Our work challenges the prevailing sentiment that high-utility DP representation learning cannot be achieved by training from scratch.
Text-to-Sticker: Style Tailoring Latent Diffusion Models for Human Expression
Nov 17, 2023



We introduce Style Tailoring, a recipe to finetune Latent Diffusion Models (LDMs) in a distinct domain with high visual quality, prompt alignment and scene diversity. We choose sticker image generation as the target domain, as the images significantly differ from photorealistic samples typically generated by large-scale LDMs. We start with a competent text-to-image model, like Emu, and show that relying on prompt engineering with a photorealistic model to generate stickers leads to poor prompt alignment and scene diversity. To overcome these drawbacks, we first finetune Emu on millions of sticker-like images collected using weak supervision to elicit diversity. Next, we curate human-in-the-loop (HITL) Alignment and Style datasets from model generations, and finetune to improve prompt alignment and style alignment respectively. Sequential finetuning on these datasets poses a tradeoff between better style alignment and prompt alignment gains. To address this tradeoff, we propose a novel fine-tuning method called Style Tailoring, which jointly fits the content and style distribution and achieves best tradeoff. Evaluation results show our method improves visual quality by 14%, prompt alignment by 16.2% and scene diversity by 15.3%, compared to prompt engineering the base Emu model for stickers generation.
Resprompt: Residual Connection Prompting Advances Multi-Step Reasoning in Large Language Models
Oct 07, 2023Chain-of-thought (CoT) prompting, which offers step-by-step problem-solving rationales, has impressively unlocked the reasoning potential of large language models (LLMs). Yet, the standard CoT is less effective in problems demanding multiple reasoning steps. This limitation arises from the complex reasoning process in multi-step problems: later stages often depend on the results of several steps earlier, not just the results of the immediately preceding step. Such complexities suggest the reasoning process is naturally represented as a graph. The almost linear and straightforward structure of CoT prompting, however, struggles to capture this complex reasoning graph. To address this challenge, we propose Residual Connection Prompting (RESPROMPT), a new prompting strategy that advances multi-step reasoning in LLMs. Our key idea is to reconstruct the reasoning graph within prompts. We achieve this by integrating necessary connections-links present in the reasoning graph but missing in the linear CoT flow-into the prompts. Termed "residual connections", these links are pivotal in morphing the linear CoT structure into a graph representation, effectively capturing the complex reasoning graphs inherent in multi-step problems. We evaluate RESPROMPT on six benchmarks across three diverse domains: math, sequential, and commonsense reasoning. For the open-sourced LLaMA family of models, RESPROMPT yields a significant average reasoning accuracy improvement of 12.5% on LLaMA-65B and 6.8% on LLaMA2-70B. Breakdown analysis further highlights RESPROMPT particularly excels in complex multi-step reasoning: for questions demanding at least five reasoning steps, RESPROMPT outperforms the best CoT based benchmarks by a remarkable average improvement of 21.1% on LLaMA-65B and 14.3% on LLaMA2-70B. Through extensive ablation studies and analyses, we pinpoint how to most effectively build residual connections.
EditVal: Benchmarking Diffusion Based Text-Guided Image Editing Methods
Oct 03, 2023
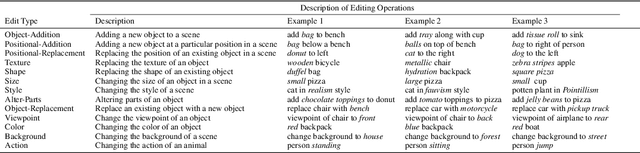
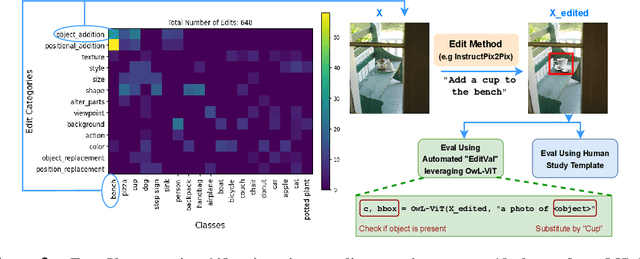
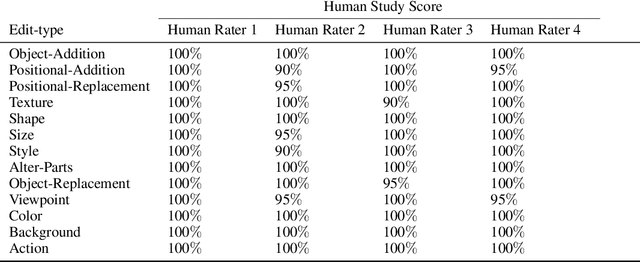
A plethora of text-guided image editing methods have recently been developed by leveraging the impressive capabilities of large-scale diffusion-based generative models such as Imagen and Stable Diffusion. A standardized evaluation protocol, however, does not exist to compare methods across different types of fine-grained edits. To address this gap, we introduce EditVal, a standardized benchmark for quantitatively evaluating text-guided image editing methods. EditVal consists of a curated dataset of images, a set of editable attributes for each image drawn from 13 possible edit types, and an automated evaluation pipeline that uses pre-trained vision-language models to assess the fidelity of generated images for each edit type. We use EditVal to benchmark 8 cutting-edge diffusion-based editing methods including SINE, Imagic and Instruct-Pix2Pix. We complement this with a large-scale human study where we show that EditVall's automated evaluation pipeline is strongly correlated with human-preferences for the edit types we considered. From both the human study and automated evaluation, we find that: (i) Instruct-Pix2Pix, Null-Text and SINE are the top-performing methods averaged across different edit types, however {\it only} Instruct-Pix2Pix and Null-Text are able to preserve original image properties; (ii) Most of the editing methods fail at edits involving spatial operations (e.g., changing the position of an object). (iii) There is no `winner' method which ranks the best individually across a range of different edit types. We hope that our benchmark can pave the way to developing more reliable text-guided image editing tools in the future. We will publicly release EditVal, and all associated code and human-study templates to support these research directions in https://deep-ml-research.github.io/editval/.
Augmenting CLIP with Improved Visio-Linguistic Reasoning
Jul 27, 2023Image-text contrastive models such as CLIP are useful for a variety of downstream applications including zero-shot classification, image-text retrieval and transfer learning. However, these contrastively trained vision-language models often fail on compositional visio-linguistic tasks such as Winoground with performance equivalent to random chance. In our paper, we address this issue and propose a sample-efficient light-weight method called SDS-CLIP to improve the compositional visio-linguistic reasoning capabilities of CLIP. The core idea of our method is to use differentiable image parameterizations to fine-tune CLIP with a distillation objective from large text-to-image generative models such as Stable-Diffusion which are relatively good at visio-linguistic reasoning tasks. On the challenging Winoground compositional reasoning benchmark, our method improves the absolute visio-linguistic performance of different CLIP models by up to 7%, while on the ARO dataset, our method improves the visio-linguistic performance by upto 3%. As a byproduct of inducing visio-linguistic reasoning into CLIP, we also find that the zero-shot performance improves marginally on a variety of downstream datasets. Our method reinforces that carefully designed distillation objectives from generative models can be leveraged to extend existing contrastive image-text models with improved visio-linguistic reasoning capabilities.