 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient AI in Practice: Training and Deployment of Efficient LLMs for Industry Applications
Feb 20, 2025Large language models (LLMs) have demonstrated remarkable performance across a wide range of industrial applications, from search and recommendations to generative tasks. Although scaling laws indicate that larger models generally yield better generalization and performance, their substantial computational requirements often render them impractical for many real-world scenarios at scale. In this paper, we present methods and insights for training small language models (SLMs) that deliver high performance and efficiency in deployment. We focus on two key techniques: (1) knowledge distillation and (2) model compression via quantization and pruning. These approaches enable SLMs to retain much of the quality of their larger counterparts while significantly reducing training, serving costs, and latency. We detail the impact of these techniques on a variety of use cases at a large professional social network platform and share deployment lessons - including hardware optimization strategies that enhance speed and throughput for both predictive and reasoning-based applications.
From Features to Transformers: Redefining Ranking for Scalable Impact
Feb 05, 2025We present LiGR, a large-scale ranking framework developed at LinkedIn that brings state-of-the-art transformer-based modeling architectures into production. We introduce a modified transformer architecture that incorporates learned normalization and simultaneous set-wise attention to user history and ranked items. This architecture enables several breakthrough achievements, including: (1) the deprecation of most manually designed feature engineering, outperforming the prior state-of-the-art system using only few features (compared to hundreds in the baseline), (2) validation of the scaling law for ranking systems, showing improved performance with larger models, more training data, and longer context sequences, and (3) simultaneous joint scoring of items in a set-wise manner, leading to automated improvements in diversity. To enable efficient serving of large ranking models, we describe techniques to scale inference effectively using single-pass processing of user history and set-wise attention. We also summarize key insights from various ablation studies and A/B tests, highlighting the most impactful technical approaches.
360Brew: A Decoder-only Foundation Model for Personalized Ranking and Recommendation
Jan 27, 2025



Ranking and recommendation systems are the foundation for numerous online experiences, ranging from search results to personalized content delivery. These systems have evolved into complex, multilayered architectures that leverage vast datasets and often incorporate thousands of predictive models. The maintenance and enhancement of these models is a labor intensive process that requires extensive feature engineering. This approach not only exacerbates technical debt but also hampers innovation in extending these systems to emerging problem domains. In this report, we present our research to address these challenges by utilizing a large foundation model with a textual interface for ranking and recommendation tasks. We illustrate several key advantages of our approach: (1) a single model can manage multiple predictive tasks involved in ranking and recommendation, (2) decoder models with textual interface due to their comprehension of reasoning capabilities, can generalize to new recommendation surfaces and out-of-domain problems, and (3) by employing natural language interfaces for task definitions and verbalizing member behaviors and their social connections, we eliminate the need for feature engineering and the maintenance of complex directed acyclic graphs of model dependencies. We introduce our research pre-production model, 360Brew V1.0, a 150B parameter, decoder-only model that has been trained and fine-tuned on LinkedIn's data and tasks. This model is capable of solving over 30 predictive tasks across various segments of the LinkedIn platform, achieving performance levels comparable to or exceeding those of current production systems based on offline metrics, without task-specific fine-tuning. Notably, each of these tasks is conventionally addressed by dedicated models that have been developed and maintained over multiple years by teams of a similar or larger size than our own.
Liger Kernel: Efficient Triton Kernels for LLM Training
Oct 14, 2024



Training Large Language Models (LLMs) efficiently at scale presents a formidable challenge, driven by their ever-increasing computational demands and the need for enhanced performance. In this work, we introduce Liger-Kernel, an open-sourced set of Triton kernels developed specifically for LLM training. With kernel optimization techniques like kernel operation fusing and input chunking, our kernels achieve on average a 20% increase in training throughput and a 60% reduction in GPU memory usage for popular LLMs compared to HuggingFace implementations. In addition, Liger-Kernel is designed with modularity, accessibility, and adaptability in mind, catering to both casual and expert users. Comprehensive benchmarks and integration tests are built in to ensure compatibility, performance, correctness, and convergence across diverse computing environments and model architectures. The source code is available under a permissive license at: github.com/linkedin/Liger-Kernel.
Enhancing Stability for Large Models Training in Constrained Bandwidth Networks
Jun 28, 2024Training extremely large language models with billions of parameters is a computationally intensive task that pushes the limits of current data parallel training systems. While techniques like ZeRO++ have enabled efficient distributed training of such giant models on inexpensive low-bandwidth clusters, they can suffer from convergence issues due to potential race conditions in the hierarchical partitioning (hpZ) scheme employed to reduce cross-machine communication. In this work, we first show how these race conditions cause instability when training models with billions of parameters. We then propose a modification to the partitioning algorithm that addresses these convergence challenges while maintaining competitive training efficiency. Empirical evaluation on training the multi-billion parameters Falcon Models and Llama-2 models demonstrates the updated algorithm's ability to achieve reliable convergence on these massive models, where stock ZeRO++ hpZ fails to converge. The updated algorithm enables robust training of larger models with 98\% throughput and model training speed improvement without sacrificing the quality of convergence.
LiRank: Industrial Large Scale Ranking Models at LinkedIn
Feb 10, 2024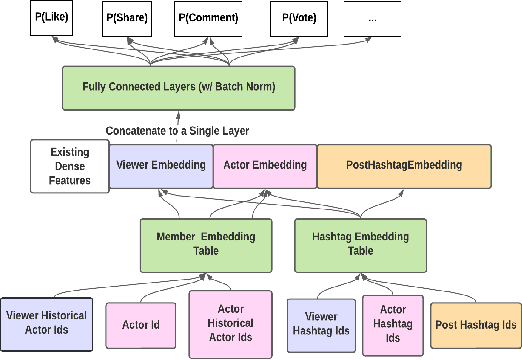

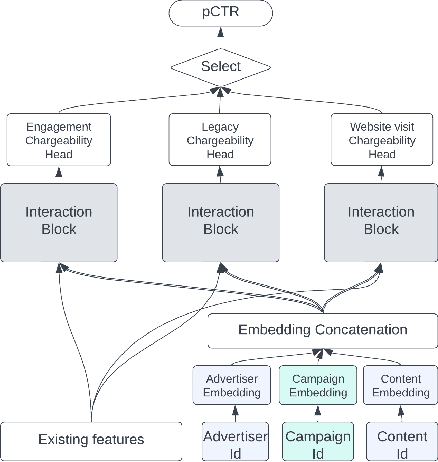

We present LiRank, a large-scale ranking framework at LinkedIn that brings to production state-of-the-art modeling architectures and optimization methods. We unveil several modeling improvements, including Residual DCN, which adds attention and residual connections to the famous DCNv2 architecture. We share insights into combining and tuning SOTA architectures to create a unified model, including Dense Gating, Transformers and Residual DCN. We also propose novel techniques for calibration and describe how we productionalized deep learning based explore/exploit methods. To enable effective, production-grade serving of large ranking models, we detail how to train and compress models using quantization and vocabulary compression. We provide details about the deployment setup for large-scale use cases of Feed ranking, Jobs Recommendations, and Ads click-through rate (CTR) prediction. We summarize our learnings from various A/B tests by elucidating the most effective technical approaches. These ideas have contributed to relative metrics improvements across the board at LinkedIn: +0.5% member sessions in the Feed, +1.76% qualified job applications for Jobs search and recommendations, and +4.3% for Ads CTR. We hope this work can provide practical insights and solutions for practitioners interested in leveraging large-scale deep ranking systems.