 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Industrial-Scale Sequential Recommender for LinkedIn Feed Ranking
Feb 12, 2026LinkedIn Feed enables professionals worldwide to discover relevant content, build connections, and share knowledge at scale. We present Feed Sequential Recommender (Feed-SR), a transformer-based sequential ranking model for LinkedIn Feed that replaces a DCNv2-based ranker and meets strict production constraints. We detail the modeling choices, training techniques, and serving optimizations that enable deployment at LinkedIn scale. Feed-SR is currently the primary member experience on LinkedIn's Feed and shows significant improvements in member engagement (+2.10% time spent) in online A/B tests compared to the existing production model. We also describe our deployment experience with alternative sequential and LLM-based ranking architectures and why Feed-SR provided the best combination of online metrics and production efficiency.
360Brew: A Decoder-only Foundation Model for Personalized Ranking and Recommendation
Jan 27, 2025



Ranking and recommendation systems are the foundation for numerous online experiences, ranging from search results to personalized content delivery. These systems have evolved into complex, multilayered architectures that leverage vast datasets and often incorporate thousands of predictive models. The maintenance and enhancement of these models is a labor intensive process that requires extensive feature engineering. This approach not only exacerbates technical debt but also hampers innovation in extending these systems to emerging problem domains. In this report, we present our research to address these challenges by utilizing a large foundation model with a textual interface for ranking and recommendation tasks. We illustrate several key advantages of our approach: (1) a single model can manage multiple predictive tasks involved in ranking and recommendation, (2) decoder models with textual interface due to their comprehension of reasoning capabilities, can generalize to new recommendation surfaces and out-of-domain problems, and (3) by employing natural language interfaces for task definitions and verbalizing member behaviors and their social connections, we eliminate the need for feature engineering and the maintenance of complex directed acyclic graphs of model dependencies. We introduce our research pre-production model, 360Brew V1.0, a 150B parameter, decoder-only model that has been trained and fine-tuned on LinkedIn's data and tasks. This model is capable of solving over 30 predictive tasks across various segments of the LinkedIn platform, achieving performance levels comparable to or exceeding those of current production systems based on offline metrics, without task-specific fine-tuning. Notably, each of these tasks is conventionally addressed by dedicated models that have been developed and maintained over multiple years by teams of a similar or larger size than our own.
Efficient SVDD Sampling with Approximation Guarantees for the Decision Boundary
Sep 29, 2020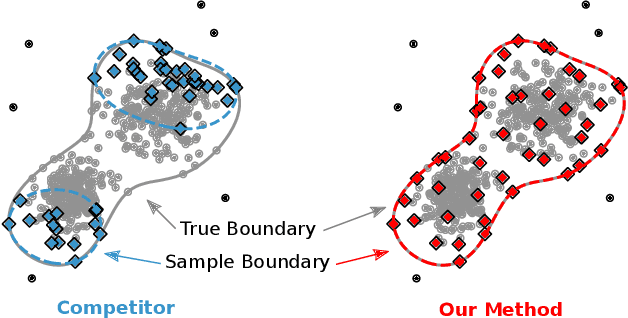
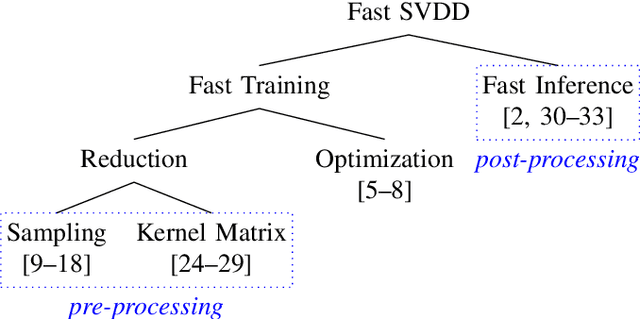
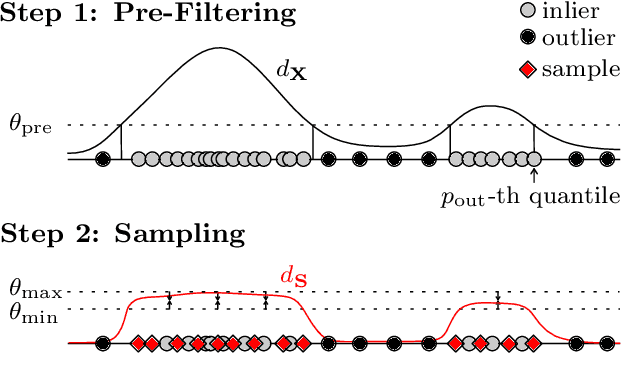
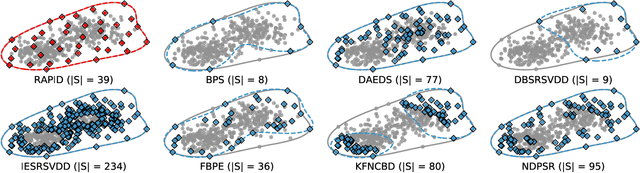
Support Vector Data Description (SVDD) is a popular one-class classifiers for anomaly and novelty detection. But despite its effectiveness, SVDD does not scale well with data size. To avoid prohibitive training times, sampling methods select small subsets of the training data on which SVDD trains a decision boundary hopefully equivalent to the one obtained on the full data set. According to the literature, a good sample should therefore contain so-called boundary observations that SVDD would select as support vectors on the full data set. However, non-boundary observations also are essential to not fragment contiguous inlier regions and avoid poor classification accuracy. Other aspects, such as selecting a sufficiently representative sample, are important as well. But existing sampling methods largely overlook them, resulting in poor classification accuracy. In this article, we study how to select a sample considering these points. Our approach is to frame SVDD sampling as an optimization problem, where constraints guarantee that sampling indeed approximates the original decision boundary. We then propose RAPID, an efficient algorithm to solve this optimization problem. RAPID does not require any tuning of parameters, is easy to implement and scales well to large data sets. We evaluate our approach on real-world and synthetic data. Our evaluation is the most comprehensive one for SVDD sampling so far. Our results show that RAPID outperforms its competitors in classification accuracy, in sample size, and in runtime.
An Overview and a Benchmark of Active Learning for One-Class Classification
Aug 14, 2018

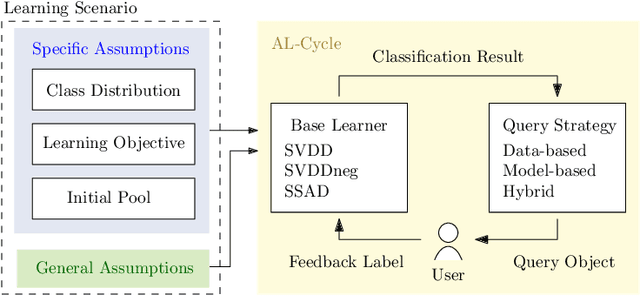

Active learning stands for methods which increase classification quality by means of user feedback. An important subcategory is active learning for one-class classifiers, i.e., for imbalanced class distributions. While various methods in this category exist, selecting one for a given application scenario is difficult. This is because existing methods rely on different assumptions, have different objectives, and often are tailored to a specific use case. All this calls for a comprehensive comparison, the topic of this article. This article starts with a categorization of the various methods. We then propose ways to evaluate active learning results. Next, we run extensive experiments to compare existing methods, for a broad variety of scenarios. One result is that the practicality and the performance of an active learning method strongly depend on its category and on the assumptions behind it. Another observation is that there only is a small subset of our experiments where existing approaches outperform random baselines. Finally, we show that a well-laid-out categorization and a rigorous specification of assumptions can facilitate the selection of a good method for one-class classification.