 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA-BDD: Leveraging Data Augmentations for Safe Autonomous Driving in Adverse Weather and Lighting
Aug 12, 2024



High-autonomy vehicle functions rely on machine learning (ML) algorithms to understand the environment. Despite displaying remarkable performance in fair weather scenarios, perception algorithms are heavily affected by adverse weather and lighting conditions. To overcome these difficulties, ML engineers mainly rely on comprehensive real-world datasets. However, the difficulties in real-world data collection for critical areas of the operational design domain (ODD) often means synthetic data is required for perception training and safety validation. Thus, we present A-BDD, a large set of over 60,000 synthetically augmented images based on BDD100K that are equipped with semantic segmentation and bounding box annotations (inherited from the BDD100K dataset). The dataset contains augmented data for rain, fog, overcast and sunglare/shadow with varying intensity levels. We further introduce novel strategies utilizing feature-based image quality metrics like FID and CMMD, which help identify useful augmented and real-world data for ML training and testing. By conducting experiments on A-BDD, we provide evidence that data augmentations can play a pivotal role in closing performance gaps in adverse weather and lighting conditions.
Selecting Models based on the Risk of Damage Caused by Adversarial Attacks
Jan 28, 2023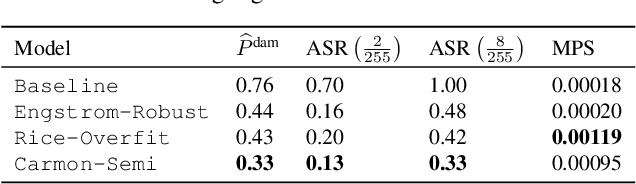
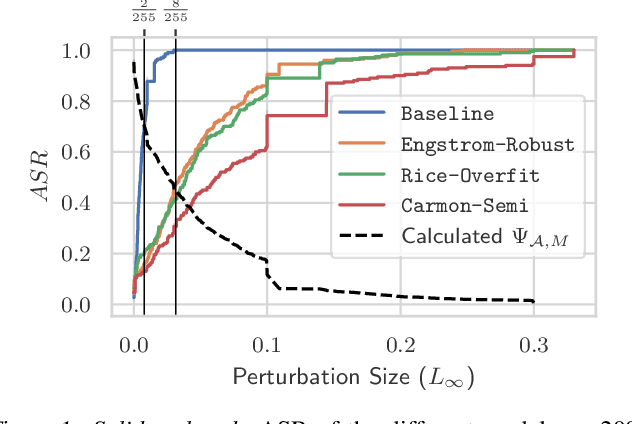
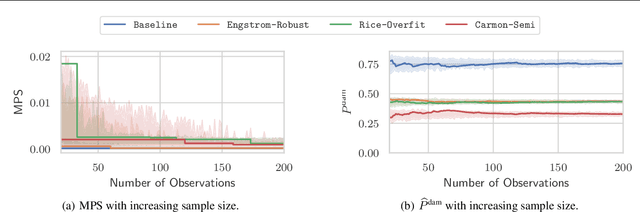
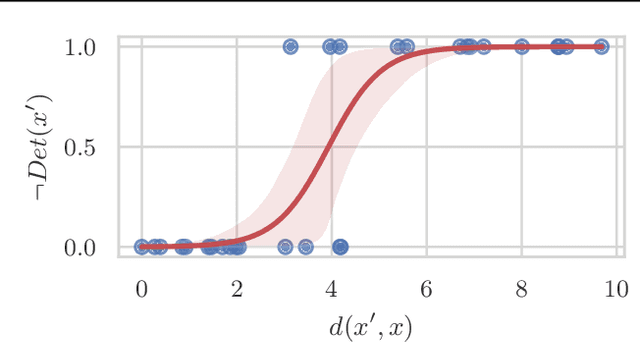
Regulation, legal liabilities, and societal concerns challenge the adoption of AI in safety and security-critical applications. One of the key concerns is that adversaries can cause harm by manipulating model predictions without being detected. Regulation hence demands an assessment of the risk of damage caused by adversaries. Yet, there is no method to translate this high-level demand into actionable metrics that quantify the risk of damage. In this article, we propose a method to model and statistically estimate the probability of damage arising from adversarial attacks. We show that our proposed estimator is statistically consistent and unbiased. In experiments, we demonstrate that the estimation results of our method have a clear and actionable interpretation and outperform conventional metrics. We then show how operators can use the estimation results to reliably select the model with the lowest risk.
Explaining Any ML Model? -- On Goals and Capabilities of XAI
Jun 28, 2022An increasing ubiquity of machine learning (ML) motivates research on algorithms to explain ML models and their predictions -- so-called eXplainable Artificial Intelligence (XAI). Despite many survey papers and discussions, the goals and capabilities of XAI algorithms are far from being well understood. We argue that this is because of a problematic reasoning scheme in XAI literature: XAI algorithms are said to complement ML models with desired properties, such as "interpretability", or "explainability". These properties are in turn assumed to contribute to a goal, like "trust" in an ML system. But most properties lack precise definitions and their relationship to such goals is far from obvious. The result is a reasoning scheme that obfuscates research results and leaves an important question unanswered: What can one expect from XAI algorithms? In this article, we clarify the goals and capabilities of XAI algorithms from a concrete perspective: that of their users. Explaining ML models is only necessary if users have questions about them. We show that users can ask diverse questions, but that only one of them can be answered by current XAI algorithms. Answering this core question can be trivial, difficult or even impossible, depending on the ML application. Based on these insights, we outline which capabilities policymakers, researchers and society can reasonably expect from XAI algorithms.
Efficient SVDD Sampling with Approximation Guarantees for the Decision Boundary
Sep 29, 2020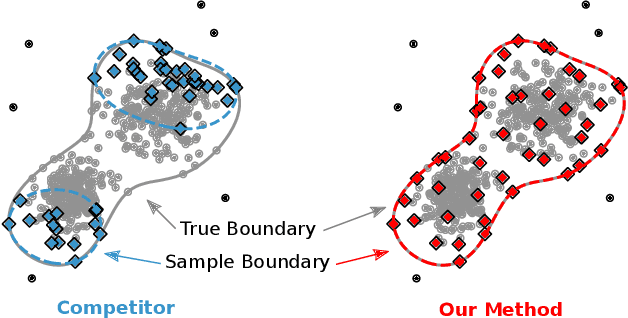
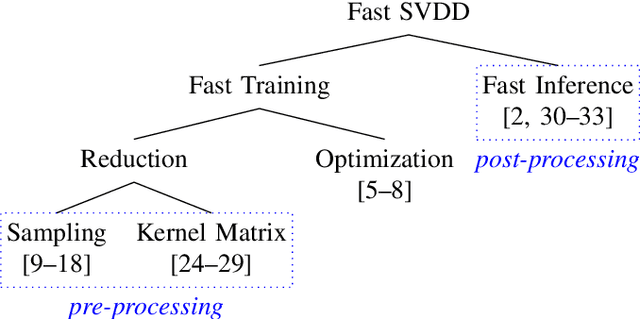
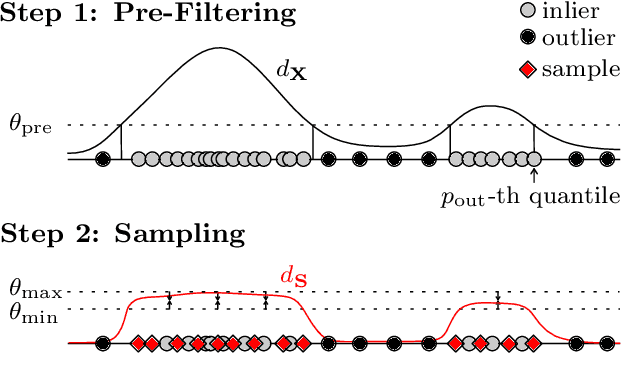
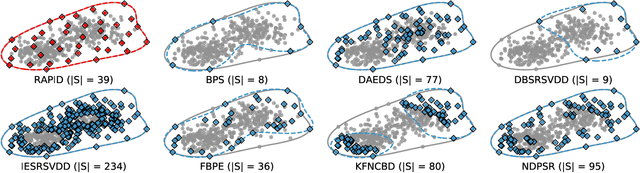
Support Vector Data Description (SVDD) is a popular one-class classifiers for anomaly and novelty detection. But despite its effectiveness, SVDD does not scale well with data size. To avoid prohibitive training times, sampling methods select small subsets of the training data on which SVDD trains a decision boundary hopefully equivalent to the one obtained on the full data set. According to the literature, a good sample should therefore contain so-called boundary observations that SVDD would select as support vectors on the full data set. However, non-boundary observations also are essential to not fragment contiguous inlier regions and avoid poor classification accuracy. Other aspects, such as selecting a sufficiently representative sample, are important as well. But existing sampling methods largely overlook them, resulting in poor classification accuracy. In this article, we study how to select a sample considering these points. Our approach is to frame SVDD sampling as an optimization problem, where constraints guarantee that sampling indeed approximates the original decision boundary. We then propose RAPID, an efficient algorithm to solve this optimization problem. RAPID does not require any tuning of parameters, is easy to implement and scales well to large data sets. We evaluate our approach on real-world and synthetic data. Our evaluation is the most comprehensive one for SVDD sampling so far. Our results show that RAPID outperforms its competitors in classification accuracy, in sample size, and in runtime.
Active Learning of SVDD Hyperparameter Values
Dec 04, 2019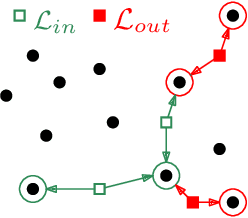
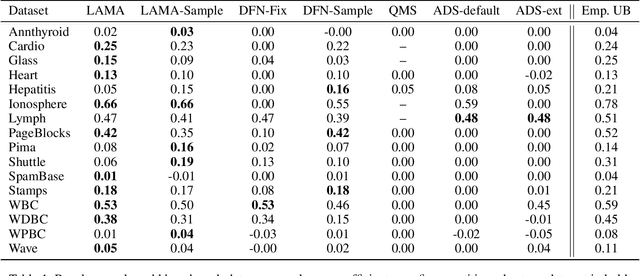
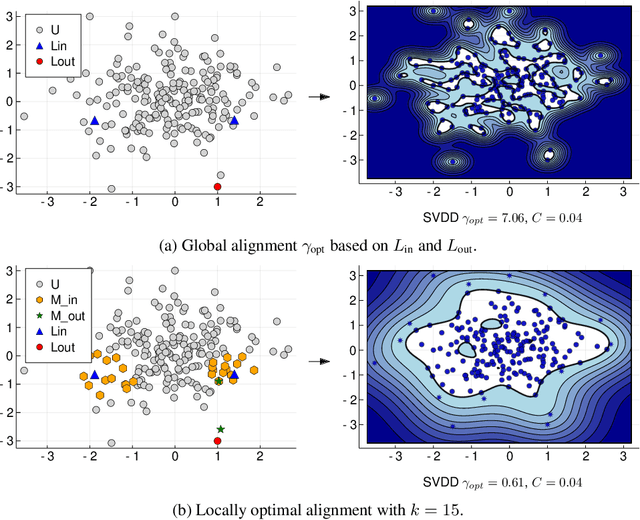
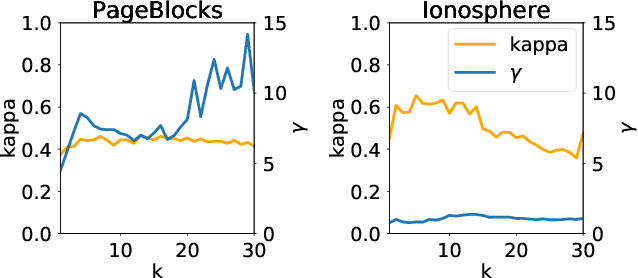
Support Vector Data Description is a popular method for outlier detection. However, its usefulness largely depends on selecting good hyperparameter values -- a difficult problem that has received significant attention in literature. Existing methods to estimate hyperparameter values are purely heuristic, and the conditions under which they work well are unclear. In this article, we propose LAMA (Local Active Min-Max Alignment), the first principled approach to estimate SVDD hyperparameter values by active learning. The core idea bases on kernel alignment, which we adapt to active learning with small sample sizes. In contrast to many existing approaches, LAMA provides estimates for both SVDD hyperparameters. These estimates are evidence-based, i.e., rely on actual class labels, and come with a quality score. This eliminates the need for manual validation, an issue with current heuristics. LAMA outperforms state-of-the-art competitors in extensive experiments on real-world data. In several cases, LAMA even yields results close to the empirical upper bound.
An Overview and a Benchmark of Active Learning for One-Class Classification
Aug 14, 2018

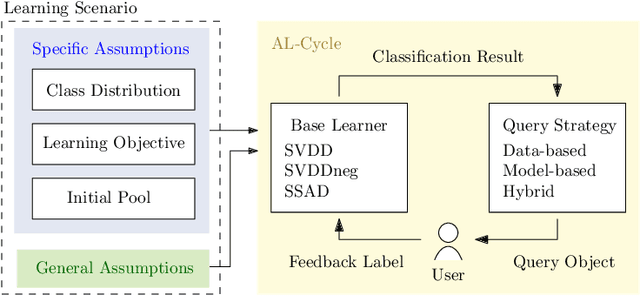

Active learning stands for methods which increase classification quality by means of user feedback. An important subcategory is active learning for one-class classifiers, i.e., for imbalanced class distributions. While various methods in this category exist, selecting one for a given application scenario is difficult. This is because existing methods rely on different assumptions, have different objectives, and often are tailored to a specific use case. All this calls for a comprehensive comparison, the topic of this article. This article starts with a categorization of the various methods. We then propose ways to evaluate active learning results. Next, we run extensive experiments to compare existing methods, for a broad variety of scenarios. One result is that the practicality and the performance of an active learning method strongly depend on its category and on the assumptions behind it. Another observation is that there only is a small subset of our experiments where existing approaches outperform random baselines. Finally, we show that a well-laid-out categorization and a rigorous specification of assumptions can facilitate the selection of a good method for one-class classification.