 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoSS: A Best-of-Strategies Selector as an Oracle for Deep Active Learning
Mar 13, 2026Active learning (AL) aims to reduce annotation costs while maximizing model performance by iteratively selecting valuable instances. While foundation models have made it easier to identify these instances, existing selection strategies still lack robustness across different models, annotation budgets, and datasets. To highlight the potential weaknesses of existing AL strategies and provide a reference point for research, we explore oracle strategies, i.e., strategies that approximate the optimal selection by accessing ground-truth information unavailable in practical AL scenarios. Current oracle strategies, however, fail to scale effectively to large datasets and complex deep neural networks. To tackle these limitations, we introduce the Best-of-Strategy Selector (BoSS), a scalable oracle strategy designed for large-scale AL scenarios. BoSS constructs a set of candidate batches through an ensemble of selection strategies and then selects the batch yielding the highest performance gain. As an ensemble of selection strategies, BoSS can be easily extended with new state-of-the-art strategies as they emerge, ensuring it remains a reliable oracle strategy in the future. Our evaluation demonstrates that i) BoSS outperforms existing oracle strategies, ii) state-of-the-art AL strategies still fall noticeably short of oracle performance, especially in large-scale datasets with many classes, and iii) one possible solution to counteract the inconsistent performance of AL strategies might be to employ an ensemble-based approach for the selection.
DD-MDN: Human Trajectory Forecasting with Diffusion-Based Dual Mixture Density Networks and Uncertainty Self-Calibration
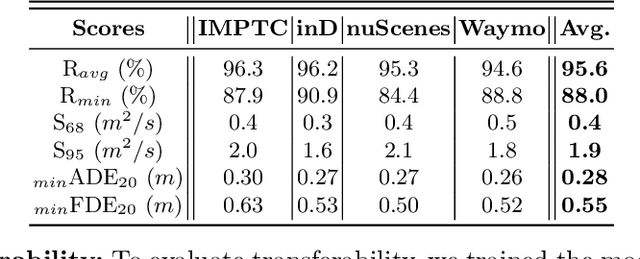
Feb 11, 2026Human Trajectory Forecasting (HTF) predicts future human movements from past trajectories and environmental context, with applications in Autonomous Driving, Smart Surveillance, and Human-Robot Interaction. While prior work has focused on accuracy, social interaction modeling, and diversity, little attention has been paid to uncertainty modeling, calibration, and forecasts from short observation periods, which are crucial for downstream tasks such as path planning and collision avoidance. We propose DD-MDN, an end-to-end probabilistic HTF model that combines high positional accuracy, calibrated uncertainty, and robustness to short observations. Using a few-shot denoising diffusion backbone and a dual mixture density network, our method learns self-calibrated residence areas and probability-ranked anchor paths, from which diverse trajectory hypotheses are derived, without predefined anchors or endpoints. Experiments on the ETH/UCY, SDD, inD, and IMPTC datasets demonstrate state-of-the-art accuracy, robustness at short observation intervals, and reliable uncertainty modeling. The code is available at: https://github.com/kav-institute/ddmdn.
Graph Neural Networks for Automatic Addition of Optimizing Components in Printed Circuit Board Schematics
Jun 12, 2025The design and optimization of Printed Circuit Board (PCB) schematics is crucial for the development of high-quality electronic devices. Thereby, an important task is to optimize drafts by adding components that improve the robustness and reliability of the circuit, e.g., pull-up resistors or decoupling capacitors. Since there is a shortage of skilled engineers and manual optimizations are very time-consuming, these best practices are often neglected. However, this typically leads to higher costs for troubleshooting in later development stages as well as shortened product life cycles, resulting in an increased amount of electronic waste that is difficult to recycle. Here, we present an approach for automating the addition of new components into PCB schematics by representing them as bipartite graphs and utilizing a node pair prediction model based on Graph Neural Networks (GNNs). We apply our approach to three highly relevant PCB design optimization tasks and compare the performance of several popular GNN architectures on real-world datasets labeled by human experts. We show that GNNs can solve these problems with high accuracy and demonstrate that our approach offers the potential to automate PCB design optimizations in a time- and cost-efficient manner.
Flow-Attentional Graph Neural Networks
Jun 06, 2025Graph Neural Networks (GNNs) have become essential for learning from graph-structured data. However, existing GNNs do not consider the conservation law inherent in graphs associated with a flow of physical resources, such as electrical current in power grids or traffic in transportation networks, which can lead to reduced model performance. To address this, we propose flow attention, which adapts existing graph attention mechanisms to satisfy Kirchhoff\'s first law. Furthermore, we discuss how this modification influences the expressivity and identify sets of non-isomorphic graphs that can be discriminated by flow attention but not by standard attention. Through extensive experiments on two flow graph datasets (electronic circuits and power grids), we demonstrate that flow attention enhances the performance of attention-based GNNs on both graph-level classification and regression tasks.
Real Time Semantic Segmentation of High Resolution Automotive LiDAR Scans
Apr 30, 2025In recent studies, numerous previous works emphasize the importance of semantic segmentation of LiDAR data as a critical component to the development of driver-assistance systems and autonomous vehicles. However, many state-of-the-art methods are tested on outdated, lower-resolution LiDAR sensors and struggle with real-time constraints. This study introduces a novel semantic segmentation framework tailored for modern high-resolution LiDAR sensors that addresses both accuracy and real-time processing demands. We propose a novel LiDAR dataset collected by a cutting-edge automotive 128 layer LiDAR in urban traffic scenes. Furthermore, we propose a semantic segmentation method utilizing surface normals as strong input features. Our approach is bridging the gap between cutting-edge research and practical automotive applications. Additionaly, we provide a Robot Operating System (ROS2) implementation that we operate on our research vehicle. Our dataset and code are publicly available: https://github.com/kav-institute/SemanticLiDAR.
Can Masked Autoencoders Also Listen to Birds?
Apr 17, 2025Masked Autoencoders (MAEs) pretrained on AudioSet fail to capture the fine-grained acoustic characteristics of specialized domains such as bioacoustic monitoring. Bird sound classification is critical for assessing environmental health, yet general-purpose models inadequately address its unique acoustic challenges. To address this, we introduce Bird-MAE, a domain-specialized MAE pretrained on the large-scale BirdSet dataset. We explore adjustments to pretraining, fine-tuning and utilizing frozen representations. Bird-MAE achieves state-of-the-art results across all BirdSet downstream tasks, substantially improving multi-label classification performance compared to the general-purpose Audio-MAE baseline. Additionally, we propose prototypical probing, a parameter-efficient method for leveraging MAEs' frozen representations. Bird-MAE's prototypical probes outperform linear probing by up to 37\% in MAP and narrow the gap to fine-tuning to approximately 3\% on average on BirdSet.
crowd-hpo: Realistic Hyperparameter Optimization and Benchmarking for Learning from Crowds with Noisy Labels
Apr 12, 2025Crowdworking is a cost-efficient solution to acquire class labels. Since these labels are subject to noise, various approaches to learning from crowds have been proposed. Typically, these approaches are evaluated with default hyperparameters, resulting in suboptimal performance, or with hyperparameters tuned using a validation set with ground truth class labels, representing an often unrealistic scenario. Moreover, both experimental setups can produce different rankings of approaches, complicating comparisons between studies. Therefore, we introduce crowd-hpo as a realistic benchmark and experimentation protocol including hyperparameter optimization under noisy crowd-labeled data. At its core, crowd-hpo investigates model selection criteria to identify well-performing hyperparameter configurations only with access to noisy crowd-labeled validation data. Extensive experimental evaluations with neural networks show that these criteria are effective for optimizing hyperparameters in learning from crowds approaches. Accordingly, incorporating such criteria into experimentation protocols is essential for enabling more realistic and fair benchmarking.
Learning Topology Actions for Power Grid Control: A Graph-Based Soft-Label Imitation Learning Approach
Mar 19, 2025The rising proportion of renewable energy in the electricity mix introduces significant operational challenges for power grid operators. Effective power grid management demands adaptive decision-making strategies capable of handling dynamic conditions. With the increase in complexity, more and more Deep Learning (DL) approaches have been proposed to find suitable grid topologies for congestion management. In this work, we contribute to this research by introducing a novel Imitation Learning (IL) approach that leverages soft labels derived from simulated topological action outcomes, thereby capturing multiple viable actions per state. Unlike traditional IL methods that rely on hard labels to enforce a single optimal action, our method constructs soft labels over actions, by leveraging effective actions that prove suitable in resolving grid congestion. To further enhance decision-making, we integrate Graph Neural Networks (GNNs) to encode the structural properties of power grids, ensuring that the topology-aware representations contribute to better agent performance. Our approach significantly outperforms state-of-the-art baselines, all of which use only topological actions, as well as feedforward and GNN-based architectures with hard labels. Most notably, it achieves a 17% better performance compared to the greedy expert agent from which the imitation targets were derived.
Reliable Probabilistic Human Trajectory Prediction for Autonomous Applications
Oct 10, 2024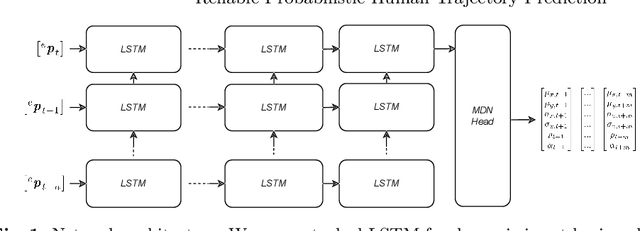

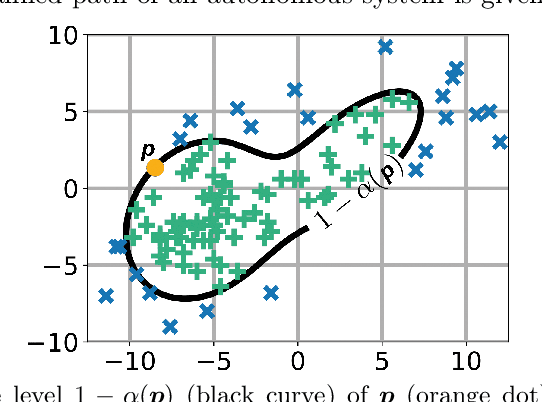
Autonomous systems, like vehicles or robots, require reliable, accurate, fast, resource-efficient, scalable, and low-latency trajectory predictions to get initial knowledge about future locations and movements of surrounding objects for safe human-machine interaction. Furthermore, they need to know the uncertainty of the predictions for risk assessment to provide safe path planning. This paper presents a lightweight method to address these requirements, combining Long Short-Term Memory and Mixture Density Networks. Our method predicts probability distributions, including confidence level estimations for positional uncertainty to support subsequent risk management applications and runs on a low-power embedded platform. We discuss essential requirements for human trajectory prediction in autonomous vehicle applications and demonstrate our method's performance using multiple traffic-related datasets. Furthermore, we explain reliability and sharpness metrics and show how important they are to guarantee the correctness and robustness of a model's predictions and uncertainty assessments. These essential evaluations have so far received little attention for no good reason. Our approach focuses entirely on real-world applicability. Verifying prediction uncertainties and a model's reliability are central to autonomous real-world applications. Our framework and code are available at: https://github.com/kav-institute/mdn_trajectory_forecasting.
Location based Probabilistic Load Forecasting of EV Charging Sites: Deep Transfer Learning with Multi-Quantile Temporal Convolutional Network
Sep 18, 2024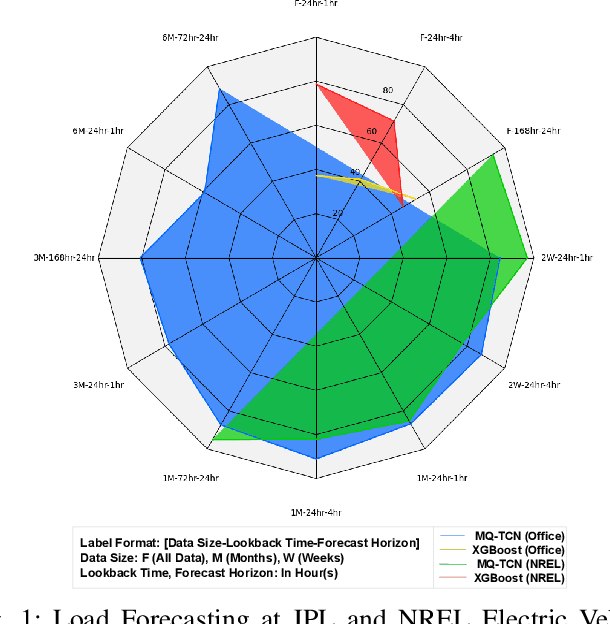
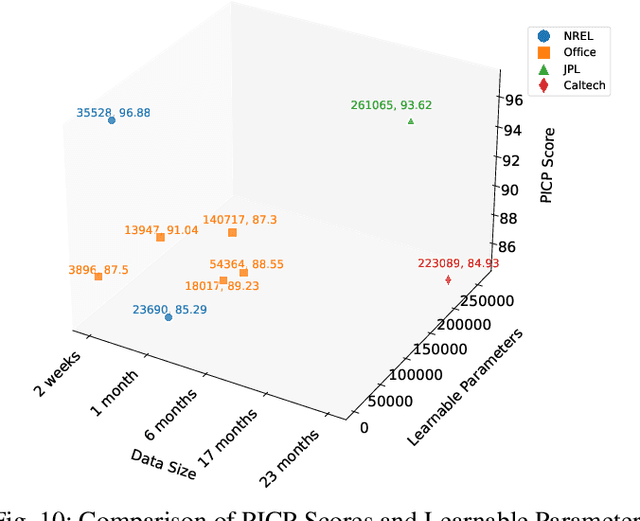
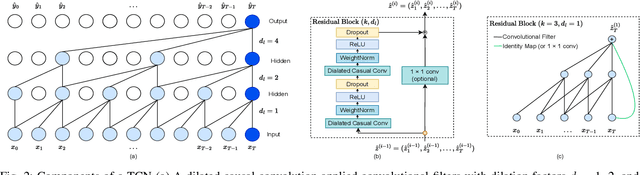
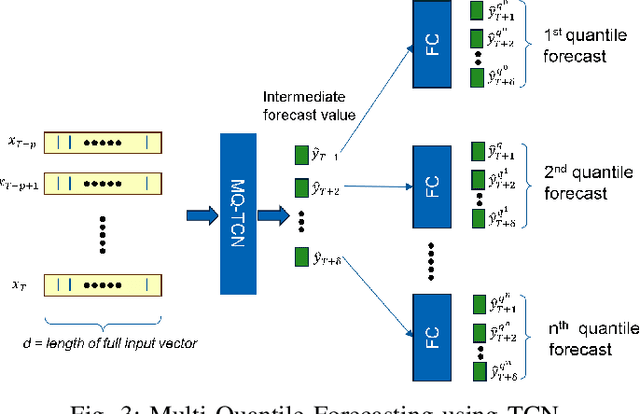
Electrification of vehicles is a potential way of reducing fossil fuel usage and thus lessening environmental pollution. Electric Vehicles (EVs) of various types for different transport modes (including air, water, and land) are evolving. Moreover, different EV user groups (commuters, commercial or domestic users, drivers) may use different charging infrastructures (public, private, home, and workplace) at various times. Therefore, usage patterns and energy demand are very stochastic. Characterizing and forecasting the charging demand of these diverse EV usage profiles is essential in preventing power outages. Previously developed data-driven load models are limited to specific use cases and locations. None of these models are simultaneously adaptive enough to transfer knowledge of day-ahead forecasting among EV charging sites of diverse locations, trained with limited data, and cost-effective. This article presents a location-based load forecasting of EV charging sites using a deep Multi-Quantile Temporal Convolutional Network (MQ-TCN) to overcome the limitations of earlier models. We conducted our experiments on data from four charging sites, namely Caltech, JPL, Office-1, and NREL, which have diverse EV user types like students, full-time and part-time employees, random visitors, etc. With a Prediction Interval Coverage Probability (PICP) score of 93.62\%, our proposed deep MQ-TCN model exhibited a remarkable 28.93\% improvement over the XGBoost model for a day-ahead load forecasting at the JPL charging site. By transferring knowledge with the inductive Transfer Learning (TL) approach, the MQ-TCN model achieved a 96.88\% PICP score for the load forecasting task at the NREL site using only two weeks of data.