 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgecrowd-hpo: Realistic Hyperparameter Optimization and Benchmarking for Learning from Crowds with Noisy Labels
Apr 12, 2025Crowdworking is a cost-efficient solution to acquire class labels. Since these labels are subject to noise, various approaches to learning from crowds have been proposed. Typically, these approaches are evaluated with default hyperparameters, resulting in suboptimal performance, or with hyperparameters tuned using a validation set with ground truth class labels, representing an often unrealistic scenario. Moreover, both experimental setups can produce different rankings of approaches, complicating comparisons between studies. Therefore, we introduce crowd-hpo as a realistic benchmark and experimentation protocol including hyperparameter optimization under noisy crowd-labeled data. At its core, crowd-hpo investigates model selection criteria to identify well-performing hyperparameter configurations only with access to noisy crowd-labeled validation data. Extensive experimental evaluations with neural networks show that these criteria are effective for optimizing hyperparameters in learning from crowds approaches. Accordingly, incorporating such criteria into experimentation protocols is essential for enabling more realistic and fair benchmarking.
dopanim: A Dataset of Doppelganger Animals with Noisy Annotations from Multiple Humans
Jul 30, 2024Human annotators typically provide annotated data for training machine learning models, such as neural networks. Yet, human annotations are subject to noise, impairing generalization performances. Methodological research on approaches counteracting noisy annotations requires corresponding datasets for a meaningful empirical evaluation. Consequently, we introduce a novel benchmark dataset, dopanim, consisting of about 15,750 animal images of 15 classes with ground truth labels. For approximately 10,500 of these images, 20 humans provided over 52,000 annotations with an accuracy of circa 67%. Its key attributes include (1) the challenging task of classifying doppelganger animals, (2) human-estimated likelihoods as annotations, and (3) annotator metadata. We benchmark well-known multi-annotator learning approaches using seven variants of this dataset and outline further evaluation use cases such as learning beyond hard class labels and active learning. Our dataset and a comprehensive codebase are publicly available to emulate the data collection process and to reproduce all empirical results.
Annot-Mix: Learning with Noisy Class Labels from Multiple Annotators via a Mixup Extension
May 06, 2024Training with noisy class labels impairs neural networks' generalization performance. In this context, mixup is a popular regularization technique to improve training robustness by making memorizing false class labels more difficult. However, mixup neglects that, typically, multiple annotators, e.g., crowdworkers, provide class labels. Therefore, we propose an extension of mixup, which handles multiple class labels per instance while considering which class label originates from which annotator. Integrated into our multi-annotator classification framework annot-mix, it performs superiorly to eight state-of-the-art approaches on eleven datasets with noisy class labels provided either by human or simulated annotators. Our code is publicly available through our repository at https://github.com/ies-research/annot-mix.
Fast Fishing: Approximating BAIT for Efficient and Scalable Deep Active Image Classification
Apr 13, 2024



Deep active learning (AL) seeks to minimize the annotation costs for training deep neural networks. BAIT, a recently proposed AL strategy based on the Fisher Information, has demonstrated impressive performance across various datasets. However, BAIT's high computational and memory requirements hinder its applicability on large-scale classification tasks, resulting in current research neglecting BAIT in their evaluation. This paper introduces two methods to enhance BAIT's computational efficiency and scalability. Notably, we significantly reduce its time complexity by approximating the Fisher Information. In particular, we adapt the original formulation by i) taking the expectation over the most probable classes, and ii) constructing a binary classification task, leading to an alternative likelihood for gradient computations. Consequently, this allows the efficient use of BAIT on large-scale datasets, including ImageNet. Our unified and comprehensive evaluation across a variety of datasets demonstrates that our approximations achieve strong performance with considerably reduced time complexity. Furthermore, we provide an extensive open-source toolbox that implements recent state-of-the-art AL strategies, available at https://github.com/dhuseljic/dal-toolbox.
Active Label Refinement for Semantic Segmentation of Satellite Images
Sep 12, 2023
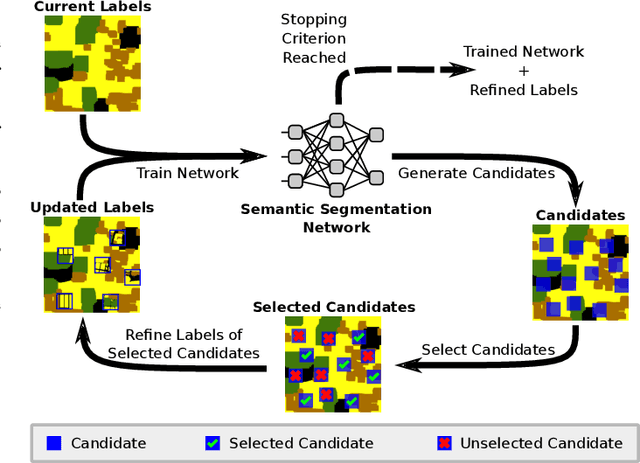
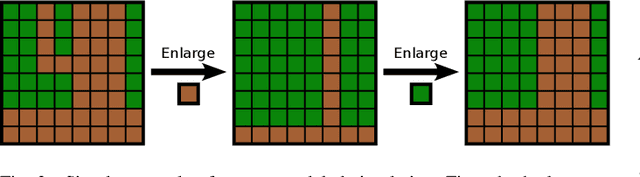
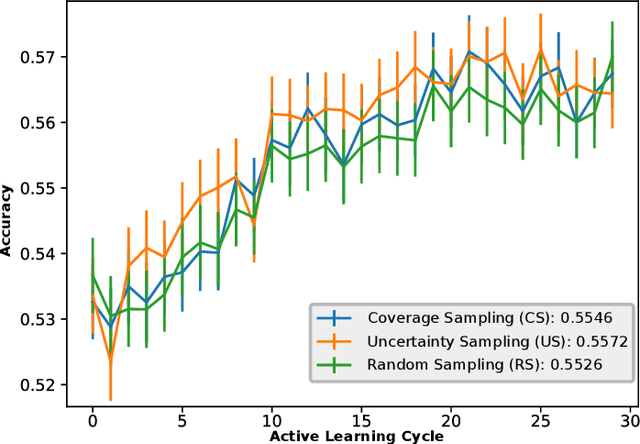
Remote sensing through semantic segmentation of satellite images contributes to the understanding and utilisation of the earth's surface. For this purpose, semantic segmentation networks are typically trained on large sets of labelled satellite images. However, obtaining expert labels for these images is costly. Therefore, we propose to rely on a low-cost approach, e.g. crowdsourcing or pretrained networks, to label the images in the first step. Since these initial labels are partially erroneous, we use active learning strategies to cost-efficiently refine the labels in the second step. We evaluate the active learning strategies using satellite images of Bengaluru in India, labelled with land cover and land use labels. Our experimental results suggest that an active label refinement to improve the semantic segmentation network's performance is beneficial.
Multi-annotator Deep Learning: A Probabilistic Framework for Classification
Apr 05, 2023



Solving complex classification tasks using deep neural networks typically requires large amounts of annotated data. However, corresponding class labels are noisy when provided by error-prone annotators, e.g., crowd workers. Training standard deep neural networks leads to subpar performances in such multi-annotator supervised learning settings. We address this issue by presenting a probabilistic training framework named multi-annotator deep learning (MaDL). A ground truth and an annotator performance model are jointly trained in an end-to-end learning approach. The ground truth model learns to predict instances' true class labels, while the annotator performance model infers probabilistic estimates of annotators' performances. A modular network architecture enables us to make varying assumptions regarding annotators' performances, e.g., an optional class or instance dependency. Further, we learn annotator embeddings to estimate annotators' densities within a latent space as proxies of their potentially correlated annotations. Together with a weighted loss function, we improve the learning from correlated annotation patterns. In a comprehensive evaluation, we examine three research questions about multi-annotator supervised learning. Our findings indicate MaDL's state-of-the-art performance and robustness against many correlated, spamming annotators.
Fast Bayesian Updates for Deep Learning with a Use Case in Active Learning
Oct 12, 2022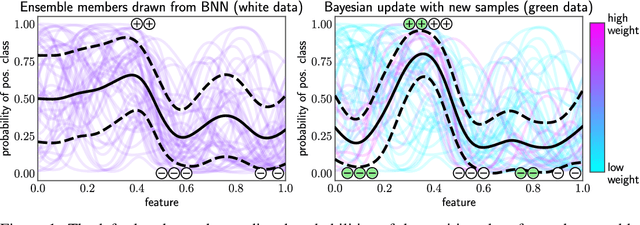
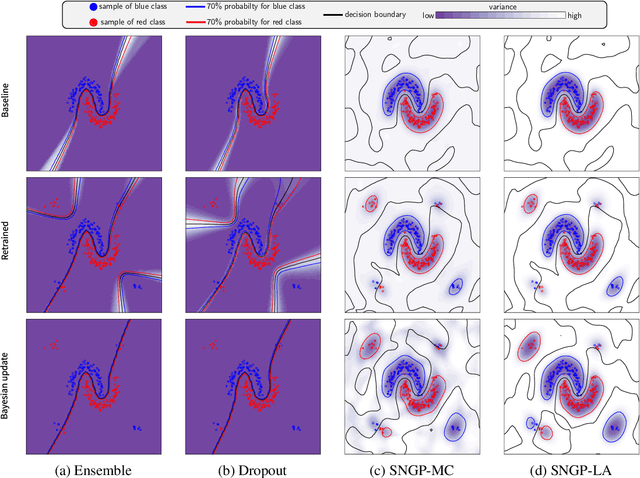
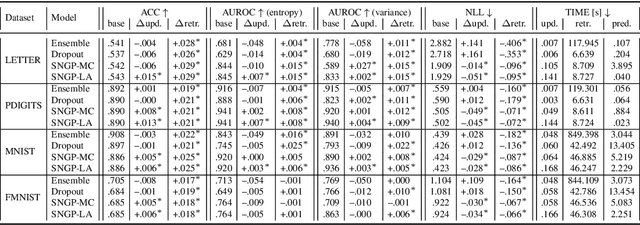
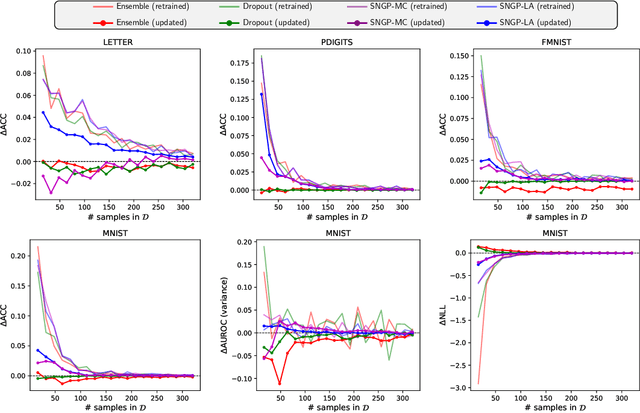
Retraining deep neural networks when new data arrives is typically computationally expensive. Moreover, certain applications do not allow such costly retraining due to time or computational constraints. Fast Bayesian updates are a possible solution to this issue. Therefore, we propose a Bayesian update based on Monte-Carlo samples and a last-layer Laplace approximation for different Bayesian neural network types, i.e., Dropout, Ensemble, and Spectral Normalized Neural Gaussian Process (SNGP). In a large-scale evaluation study, we show that our updates combined with SNGP represent a fast and competitive alternative to costly retraining. As a use case, we combine the Bayesian updates for SNGP with different sequential query strategies to exemplarily demonstrate their improved selection performance in active learning.
A Review of Uncertainty Calibration in Pretrained Object Detectors
Oct 06, 2022



In the field of deep learning based computer vision, the development of deep object detection has led to unique paradigms (e.g., two-stage or set-based) and architectures (e.g., Faster-RCNN or DETR) which enable outstanding performance on challenging benchmark datasets. Despite this, the trained object detectors typically do not reliably assess uncertainty regarding their own knowledge, and the quality of their probabilistic predictions is usually poor. As these are often used to make subsequent decisions, such inaccurate probabilistic predictions must be avoided. In this work, we investigate the uncertainty calibration properties of different pretrained object detection architectures in a multi-class setting. We propose a framework to ensure a fair, unbiased, and repeatable evaluation and conduct detailed analyses assessing the calibration under distributional changes (e.g., distributional shift and application to out-of-distribution data). Furthermore, by investigating the influence of different detector paradigms, post-processing steps, and suitable choices of metrics, we deliver novel insights into why poor detector calibration emerges. Based on these insights, we are able to improve the calibration of a detector by simply finetuning its last layer.
A Survey on Cost Types, Interaction Schemes, and Annotator Performance Models in Selection Algorithms for Active Learning in Classification
Sep 23, 2021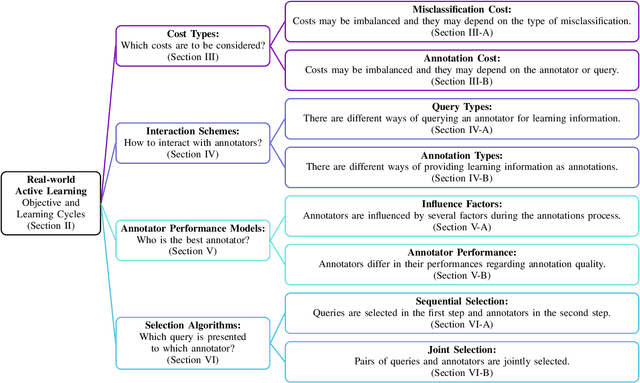
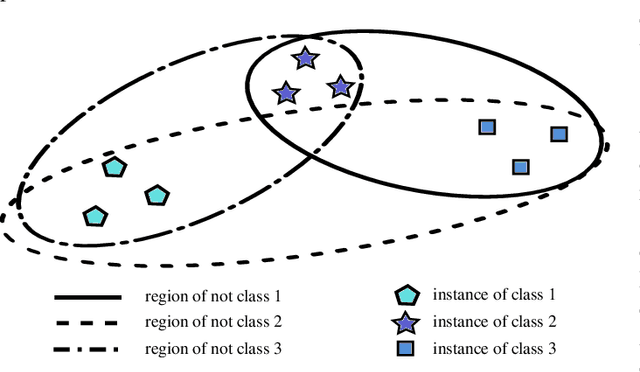
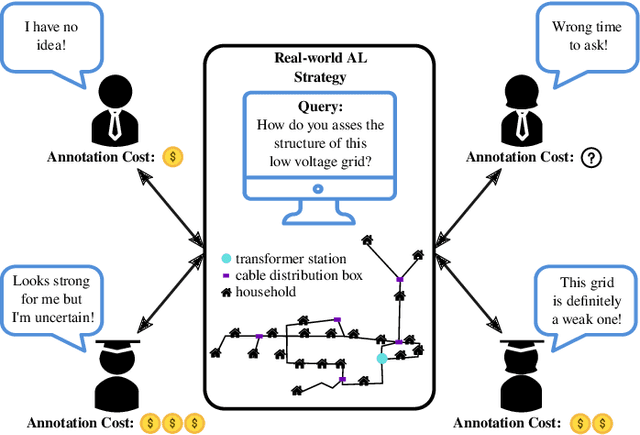
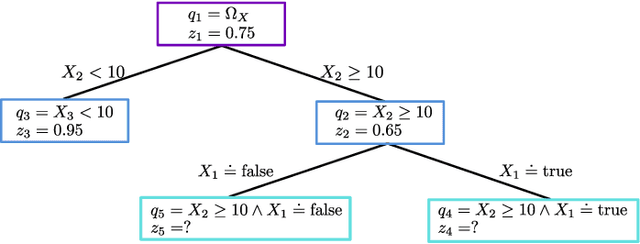
Pool-based active learning (AL) aims to optimize the annotation process (i.e., labeling) as the acquisition of annotations is often time-consuming and therefore expensive. For this purpose, an AL strategy queries annotations intelligently from annotators to train a high-performance classification model at a low annotation cost. Traditional AL strategies operate in an idealized framework. They assume a single, omniscient annotator who never gets tired and charges uniformly regardless of query difficulty. However, in real-world applications, we often face human annotators, e.g., crowd or in-house workers, who make annotation mistakes and can be reluctant to respond if tired or faced with complex queries. Recently, a wide range of novel AL strategies has been proposed to address these issues. They differ in at least one of the following three central aspects from traditional AL: (1) They explicitly consider (multiple) human annotators whose performances can be affected by various factors, such as missing expertise. (2) They generalize the interaction with human annotators by considering different query and annotation types, such as asking an annotator for feedback on an inferred classification rule. (3) They take more complex cost schemes regarding annotations and misclassifications into account. This survey provides an overview of these AL strategies and refers to them as real-world AL. Therefore, we introduce a general real-world AL strategy as part of a learning cycle and use its elements, e.g., the query and annotator selection algorithm, to categorize about 60 real-world AL strategies. Finally, we outline possible directions for future research in the field of AL.
Toward Optimal Probabilistic Active Learning Using a Bayesian Approach
Jun 02, 2020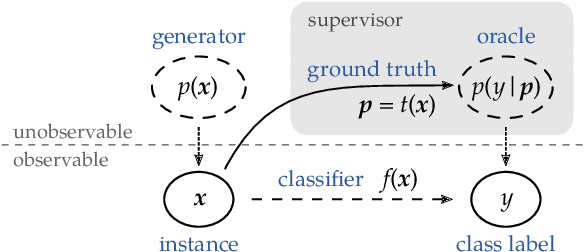
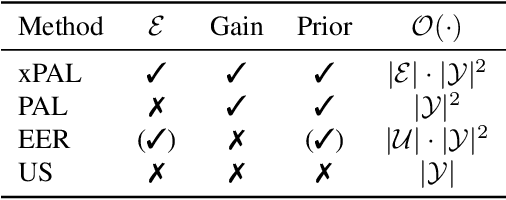
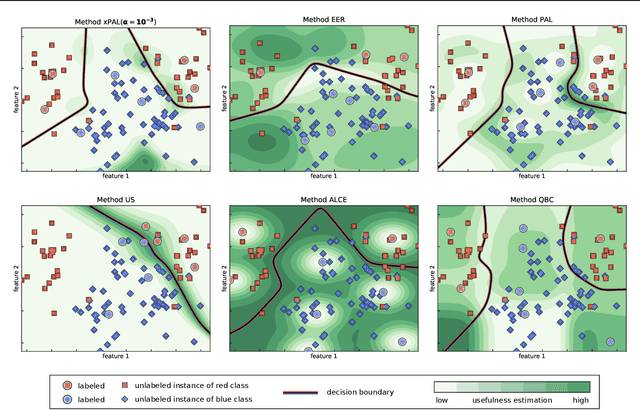
Gathering labeled data to train well-performing machine learning models is one of the critical challenges in many applications. Active learning aims at reducing the labeling costs by an efficient and effective allocation of costly labeling resources. In this article, we propose a decision-theoretic selection strategy that (1) directly optimizes the gain in misclassification error, and (2) uses a Bayesian approach by introducing a conjugate prior distribution to determine the class posterior to deal with uncertainties. By reformulating existing selection strategies within our proposed model, we can explain which aspects are not covered in current state-of-the-art and why this leads to the superior performance of our approach. Extensive experiments on a large variety of datasets and different kernels validate our claims.